转载自:https://blog.csdn.net/weixin_43486780/article/details/105344900
项目地址
首先加载时间序列数据集,数据集
import pandas as pd
data = pd.read_csv('SP500.csv')
data.head()
数据集大概是这样的,这里我们选择’Close’这一列特征进行预测。
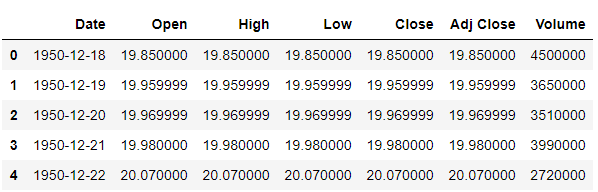
将其可视化
import matplotlib.pyplot as plt
import numpy as np
data_close = np.reshape(data['Close'].values,(-1,1))
plt.plot(data_close)
可以看到数值变化较大,从0变化到2500,为了方便LSTM训练我们将其进行MinMax归一化,最后再将预测结果反归一化回来即可。
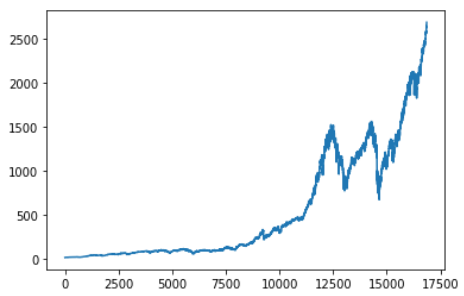
如下,对数据进行归一化
from sklearn.preprocessing import MinMaxScaler
data_scaler = MinMaxScaler(feature_range=(0, 1))
scale_data = data_scaler.fit_transform(data_close)
plt.plot(scale_data)
归一化后并不改变数据的趋势,此时数值大小被限制在(0,1)间。
LSTM的输入数据格式是:[batchsize,num_steps,feature_size],num_steps即我们每次用多少个观测值去预测下一个时刻的观测值,这些观测值在时间上是连续的,feature_size表示每个观测值的特征大小,这里我们是预测一个数,因此feature_size=1。我们需要定义一个函数将数据规范成这种格式。
将数据规范成[None,num_steps,feature_size]的形式,且根据test_ratio划分训练集和测试集。
def data_format(data, num_steps=4, test_ratio=0.2):
# split into groups of num_steps
X = np.array([data[i: i + num_steps]
for i in range(len(data) - num_steps)])
y = np.array([data[i + num_steps]
for i in range(len(data) - num_steps)])
train_size = int(len(X) * (1.0 - test_ratio))
train_X, test_X = X[:train_size], X[train_size:]
train_y, test_y = y[:train_size], y[train_size:]
return train_X, train_y, test_X, test_y
对归一化后的数据进行数据格式规范化
num_steps = 3
test_ratio = 0.2
train_X, train_y, test_X, test_y = data_format(scale_data, num_steps, test_ratio)
print(train_X.shape, test_X.shape)
>>> (13487, 3, 1) (3372, 3, 1)
接下来定义LSTM网络对进行预测
输入为[batchsize,num_steps,feature_size](定义Inputs时是不需要管batchsize大小的),LSTM的神经元个数为32,即LSTM层输出是一个大小为32的向量,后接一个全连接层将32维的向量映射成一个数字,采用MSE作为误差函数。
from keras.layers import LSTM, Dense, Input
from keras import Model
inputs = Input(shape=[num_steps, 1])
lstm = LSTM(32)(inputs)
out = Dense(1)(lstm)
model = Model(inputs, out)
model.compile(loss='mean_squared_error', optimizer='adam')
model.summary()
网络形状如下,关于LSTM的网络参数个数可以看我的另一篇博客
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 3, 1) 0
_________________________________________________________________
lstm_2 (LSTM) (None, 32) 4352
_________________________________________________________________
dense_2 (Dense) (None, 1) 33
=================================================================
Total params: 4,385
Trainable params: 4,385
Non-trainable params: 0
接着对网络进行fit训练
model.fit(train_X, train_y, batch_size=1, epochs=30)

训练完成后我们对测试集进行预测
preds = model.predict(test_X)
将预测结果反归一化,并于真实值比较
preds = data_scaler.inverse_transform(preds)
trues = data_scaler.inverse_transform(test_y)
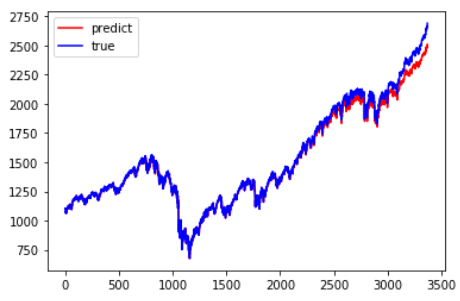
plt.plot(preds, c='r', label='predict')
plt.plot(trues, c='b', label='true')
plt.legend()
可以看到这个简单的网络已经基本拟合了测试集,表现不错,我们还可以搭建多层LSTM做更复杂的模型,搭建多层LSTM可见我的另一篇博客
最后
以上就是粗犷盼望最近收集整理的关于【keras】利用LSTM做简单的时间序列预测的全部内容,更多相关【keras】利用LSTM做简单内容请搜索靠谱客的其他文章。








发表评论 取消回复