大数据技术原理与应用学习笔记(二)
- 本系列历史文章
- Hadoop
- Hadoop简介
- Hadoop的特性
- Hadoop在企业中的应用架构
- Hadoop的版本
- Hadoop项目结构
- Linux和Hadoop安装
- Hadoop集群部署
本系列历史文章
大数据技术原理与应用学习笔记(一)
Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。
Hadoop简介
Hadoop两大核心:分布式文件系统(HDFS)、分布式并行编程框架(MapReduce)
Hadoop的特性
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下特性:
高可靠性
高效性
高可扩展性
高容错性
成本低
运行在Linux操作系统上
支持多种编程语言
Hadoop在企业中的应用架构
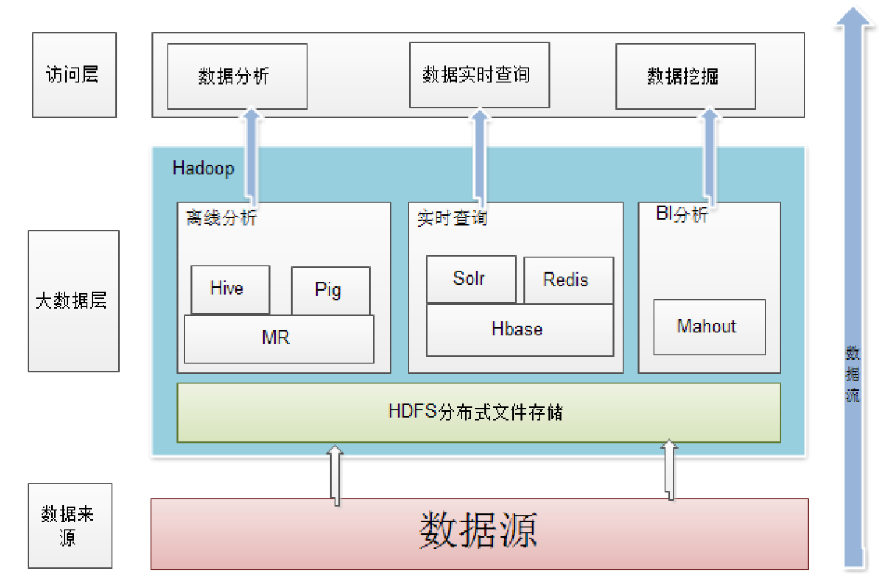
Hadoop的版本
此处注意:在Hadoop1.0中,只有MapReduce和HDFS两个框架,在Hadoop2.0中,将资源调度管理部分独立为Yarn框架来进行资源的管理调度。
Hadoop项目结构
经过多年的发展,Hadoop生态系统不断完善和成熟,目前已经包含了多个子项目,除了核心的HDFS与MapReduce以外,还包括如下图所示的多个项目,由他们协同合作,完成相应功能。
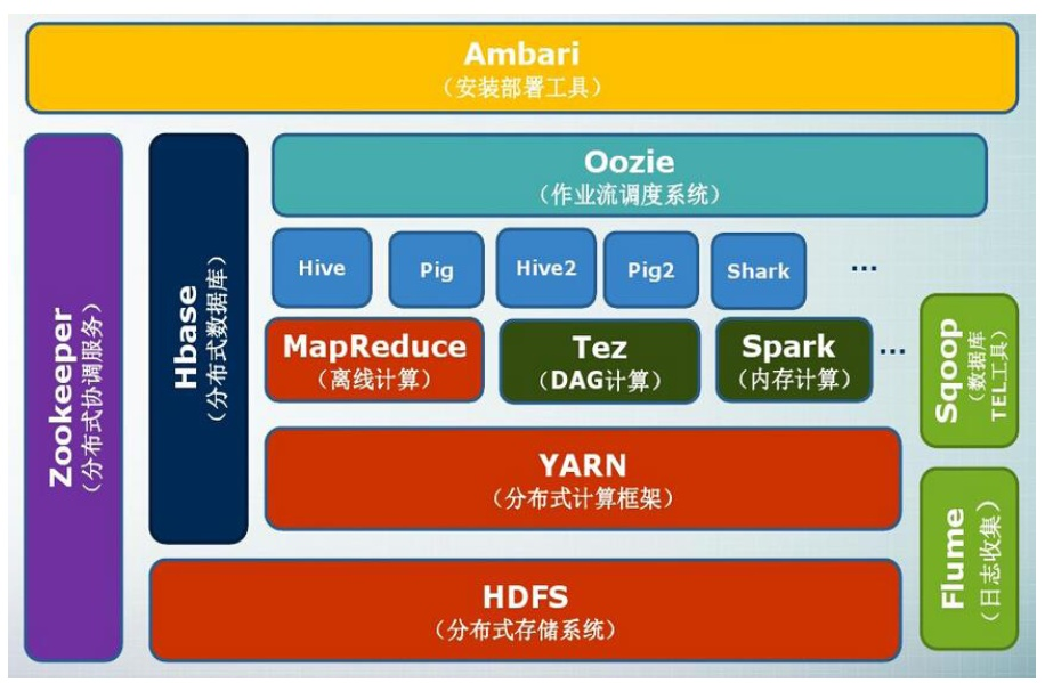
- HDFS: 分布式存储文件系统,Hadoop两大核心之一。
- HBase: 分布式列式数据库。
- MapReduce: 分布式并行编程框架,是针对谷歌MapReduce的开源实现。
- Hive: 数据仓库(数据分析用)。
- Pig: 基于Hadoop的大规模数据分析平台。
- Mahout: 支持数据挖掘的开源项目。
- Zookeeper: 提供分布式协调一致性服务。
- Flume: 分布式海量日志采集、聚合和传输的系统。
- Sqoop: 关系型数据库和Hadoop之间进行数据迁移的工具。
- Ambari: 是一种基于Web的工具,支持Apache Hadoop集群的安装、部署、配置和管理。
Linux和Hadoop安装
关于Linux安装的部分可参考厦大数据库博客:Linux系统安装
关于Hadoop安装的部分可参考厦大数据库博客:Hadoop3.1.3安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04(16.04)
Hadoop集群部署
硬件配置分为NameNode、SecondNameNode和DataNode,MapReduce的两大组件为JobTracker和TaskTracker,这部分还会在后面的学习笔记中在详细提到,此处作为了解。
最后
以上就是昏睡金毛最近收集整理的关于大数据技术原理与应用学习笔记(二)本系列历史文章Hadoop的全部内容,更多相关大数据技术原理与应用学习笔记(二)本系列历史文章Hadoop内容请搜索靠谱客的其他文章。








发表评论 取消回复