补充内容:
Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数、Executor数、core数目的关系
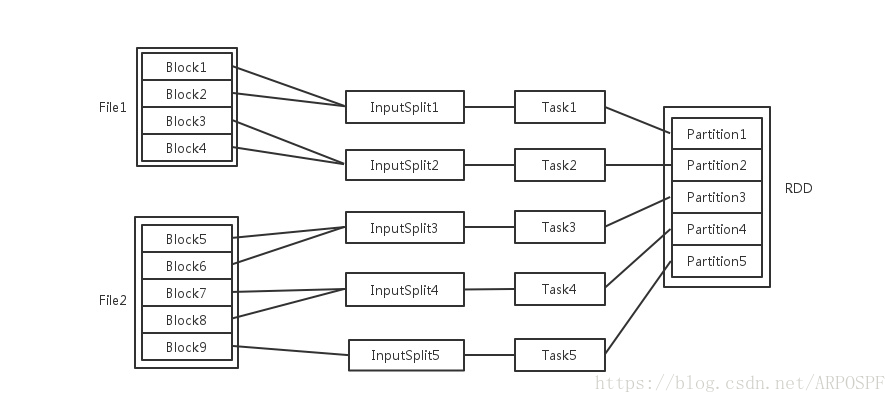
输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为Block。默认情况下,一个block最大为128M。
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partiton。
注意: 这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。
而 Task被执行的并发度 = Executor数目 * 每个Executor核数。
至于partition的数目:- 对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task。
- 在Map阶段partition数目保持不变。
- 在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
- 分布在集群中的只读对象集合(由多个Partition构成)
- 可以存储在磁盘或内存中(多种存储级别)
- 通过并行“转换”操作构造
- 失效后自动重构
Spark编程模型
SparkContext类与SparkConf类:
任何Spark程序的编写都是从SparkContext(或用Java编写时的JavaSparkContext)开始的。SparkContext的初始化需要一个SparkConf对象,后者包含了Spark集群配置的各种参数。初始化后,便可用SparkContext对象所包含的各种方法来创建和操作分布式数据集和共享变量。
弹性分布式数据集RDD:
RDD可从现有的集合创建,也可以基于Hadoop的输入源创建。基于Hadoop的RDD可以使用任何实现了Hadoop InputFormat接口的输入格式。
在Spark编程模式下,所有的操作被分为转换(transformation)和执行(action)两种。一般来说,转换操作是对一个数据集里的所有记录执行某种函数,从而使记录发生改变;而执行通常是运行某些计算或聚合操作,并将结果返回运行SparkContext的那个驱动程序。
Spark的操作通常采用函数式风格。Spark程序中最常用的转换操作便是map操作。该操作对一个RDD里的每一条记录都执行某个函数,从而将输入映射称为新的输出。“=>”是Scala下表示匿名函数的语法。匿名函数指那些没有指定函数名的函数。Spark的大多数操作都会返回一个新RDD,但多数的执行操作则是返回计算的结果,值的注意的是,Spark中的转换操作是延后的。也就是说,在RDD上调用一个转换操作并不会立即出发相应的计算。相反,这些转换操作会链接起来,并只在有执行操作被调用时才被高效地计算。
RDD缓存策略
Spark最为强大的功能之一便是能够把数据缓存在集群的内存里。这通过调用RDD的cache函数来实现:rddFromTextFile.cache。调用一个RDD的cache函数将会告诉Spark将这个RDD缓存在内存中。在RDD首次调用一个执行操作时,这个操作对应的计算会立即执行,数据会从数据源里读出来并保存到内存。因此,首次调用cache函数所需要的时间会部分取决于Spark从输入源读取数据所需要的时间。但是,当下一次访问数据集的时候,数据可以直接从内存中读出从而减少低效的I/O操作,加快计算。
通过persist函数可以指定Spark的数据缓存策略。
广播变量和累加器
广播变量(broadcast variable)为只读变量,它由运行SparkContext的驱动程序创建后发送给会参与计算的节点。Spark下创建广播变量只需在SparkContext上调用一个方法即可:
val broadcastAList = sc.broadcast()
广播变量也可以被非驱动程序所在的节点(即工作节点)访问,访问的方法是调用变量的value方法。
通常只在需将结果返回到驱动程序所在的节点以供本地处理时,才调用collect函数。collect函数一般仅在的确需要将整个结果集返回驱动程序并进行后续处理时才有必要调用。
累加器(accumulator)也是一种被广播到工作节点的变量。累加器与广播变量的关键不同,是后者只能读取而前者却可累加。但支持的累加操作有一定的限制。具体来说,这种累加必须是一种有关量的操作,即它得能保证在全局范围内累加起来的值能被正确地并行计算以及返回驱动程序。每一个工作节点只能访问和操作其自己本地的累加器,全局累加器则只允许驱动程序访问。累加器同样可以在Spark代码中通过value访问。
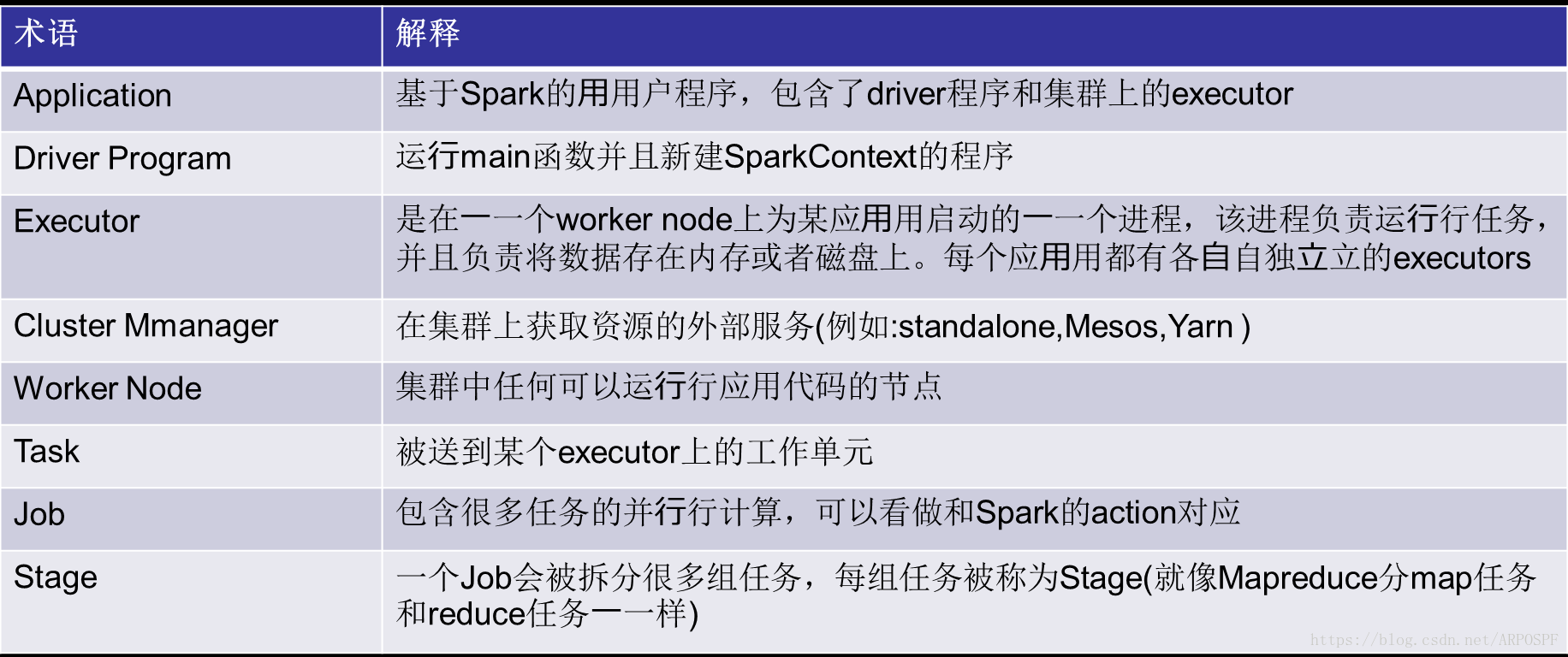
每个Spark程序都是有一个Driver和多个Executor构成的,它们实际上都是一个进程,Driver会把应用程序分解为多个Task,Task是一个线程。
正文:
设计机器学习系统
现代的大数据场景包含如下需求:
- 必须能与系统的其他组件整合,尤其是数据的收集和存储系统、分析和报告以及前端应用。
- 易于扩展且与其他组件相对独立。理想情况下,同时具备良好的水平和垂直可扩展性
- 支持高校完成所需类型的计算,即机器学习和迭代式分析应用
- 最好能同时支持批处理和实时处理。
个性化与推荐:
推荐(recommendation)从根本上说是个性化的一种,常指向用户呈现一个他们可能感兴趣的物品列表。
推荐通常专指向用户显式地呈现某些产品或内容,而个性化有时也偏向隐式。
目标影响和客户细分:
一般来说,推荐和个性化的应用场景都是一对一,而客户细分则试图将用户分成不同的组。其分组根据用户的特征进行,并可能参考行为数据。
预测建模与分析
机器学习模型的种类:监督学习:使用已标记数据来学习;无监督学习:学习过程中不需要标记数据。
数据获取与存储
文件系统,如HDFS、Amazon S3等
SQL数据库,如MySQL或PostgreSQL
分布式NoSQL数据存储,如HBase、Cassandra和DynamoDB;
搜索引擎,如Solr和Elasticsearch;
流数据系统,如Kafka、Fluma和Amazon Kinesis。
数据清理与转换:大多数机器学习模型所处理的都是特征(feature)。
预处理过程可能包括:数据过滤,处理数据缺失、不完整或有缺陷,处理可能的异常、错误和异常值,合并多个数据源,数据汇总。
数据转换和特征提取时常见的挑战有以下情况:
将类别数据编码为对应的数值表示;
从文本数据提取有用信息;
处理图像或是音频数据;
数值数据常被转换为类别数据以减少某个变量的可能值的数目,如数值分段;
对数值特征进行转换,如对数值变量应用对数转换;
对特征进行正则化、标准化,以保证同一模型的不同输入变量的值域相同;
特征工程是对现有变量进行组合或转换以生成新特征的过程,如求平均值。
模型训练与测试回路:当数据已转换为可用于模型的形式,便可开始模型的训练和测试。在训练数据集上运行模型并在测试数据集上测试其效果,这个过程一般相对直接,被称作交叉验证(cross-validation)。Spark内置的机器学习库MLlib能够胜任这一阶段的需求。
模型部署与整合
模型监控与反馈
模型反馈(model feedback),指通过用户的行为来对模型的预测进行反馈的过程。
批处理或实时方案的选择:
Spark提供了实时流处理组件Spark Streaming
实践中还需要考虑的方面有:
需要哪些数据源;数据格式应该如何;数据收集、处理、可能进行的汇总以及存储的频率;使用何种存储以保证可扩展性。
参考内容:
知乎:https://www.zhihu.com/question/33270495?sort=created
知乎:https://www.zhihu.com/question/33270495/answer/93424104,作者:王燚光
博客园:http://www.cnblogs.com/MOBIN/p/5857314.html
博客园:http://www.cnblogs.com/ITtangtang/p/7967386.html
云栖社区:https://yq.aliyun.com/articles/368691
最后
以上就是鳗鱼蜗牛最近收集整理的关于Spark学习(2)——设计机器学习系统的全部内容,更多相关Spark学习(2)——设计机器学习系统内容请搜索靠谱客的其他文章。








发表评论 取消回复