我是靠谱客的博主 任性世界,这篇文章主要介绍大数据学习笔记(二)(一)YARN体系结构(二)大数据的应用领域(三)协同过滤算法(四)HDFS高可用方案(五)HDFS Federation方案(六)NoSQL数据库,现在分享给大家,希望可以做个参考。
(一)YARN体系结构
- YARN设计思路
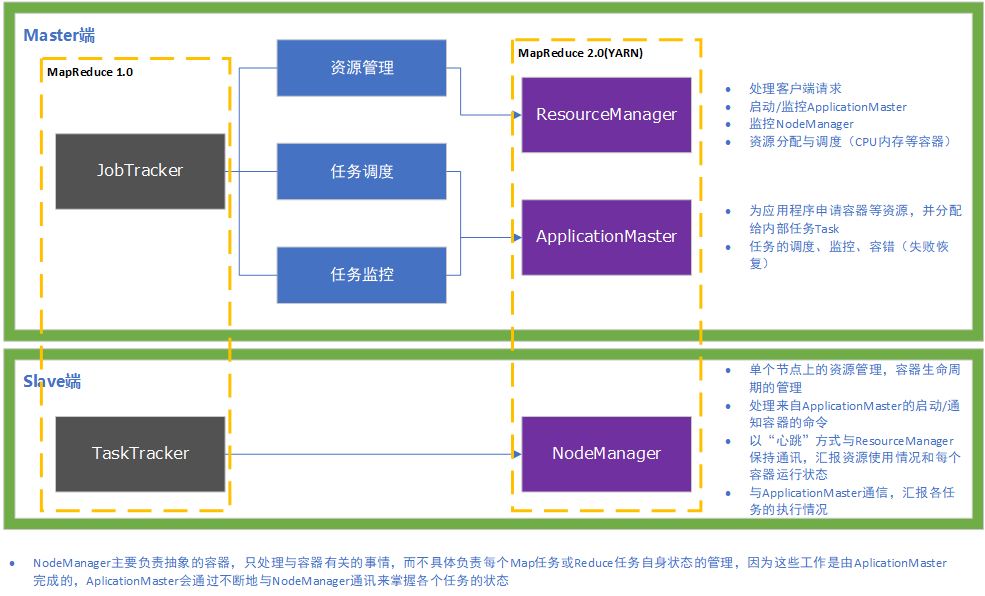
- YARN部署
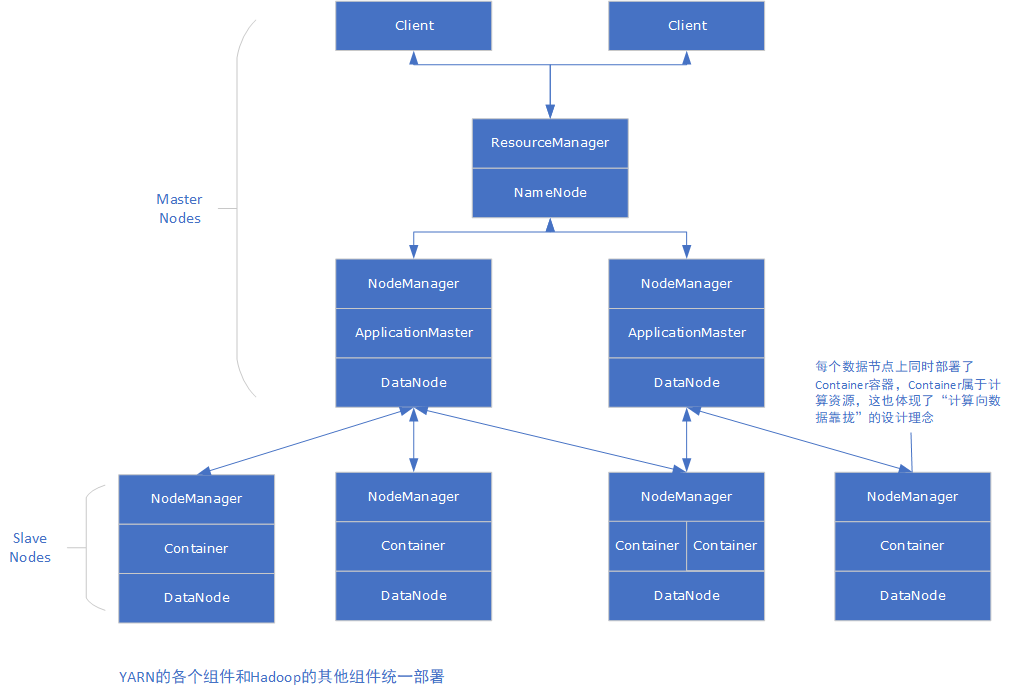
- YARN工作流程
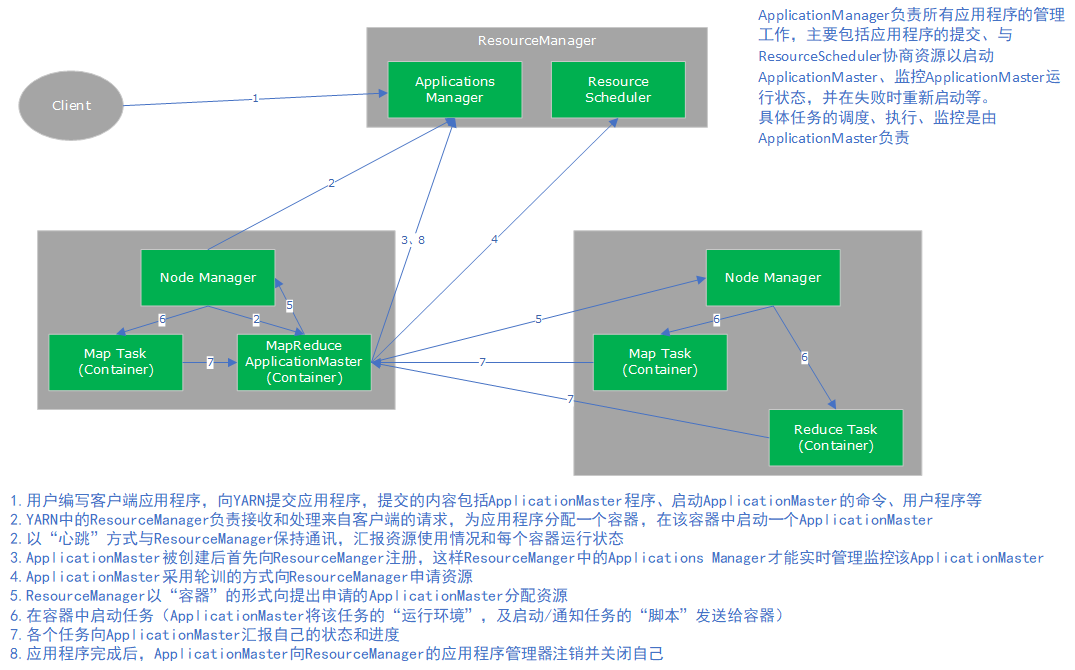
(二)大数据的应用领域

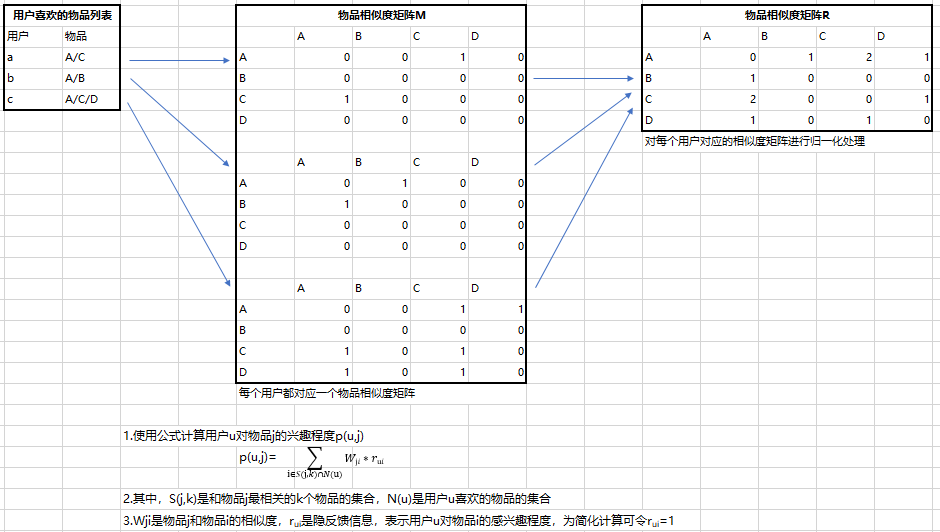
(三)协同过滤算法
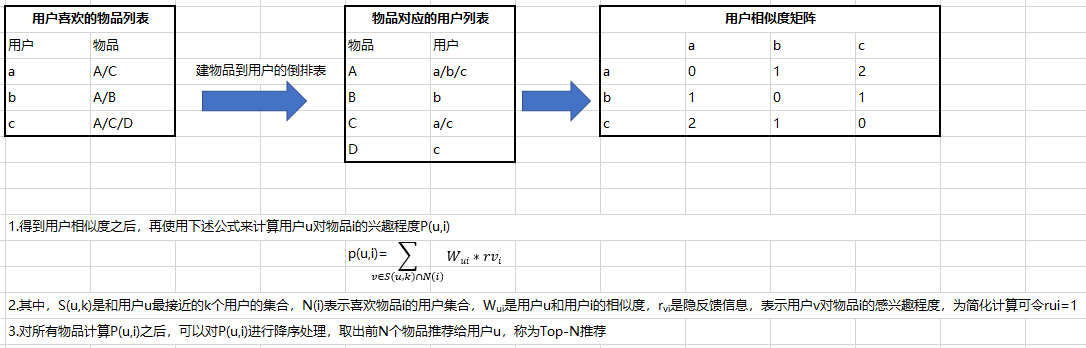
- 基于用户的协同过滤
- 基于物品的协同过滤
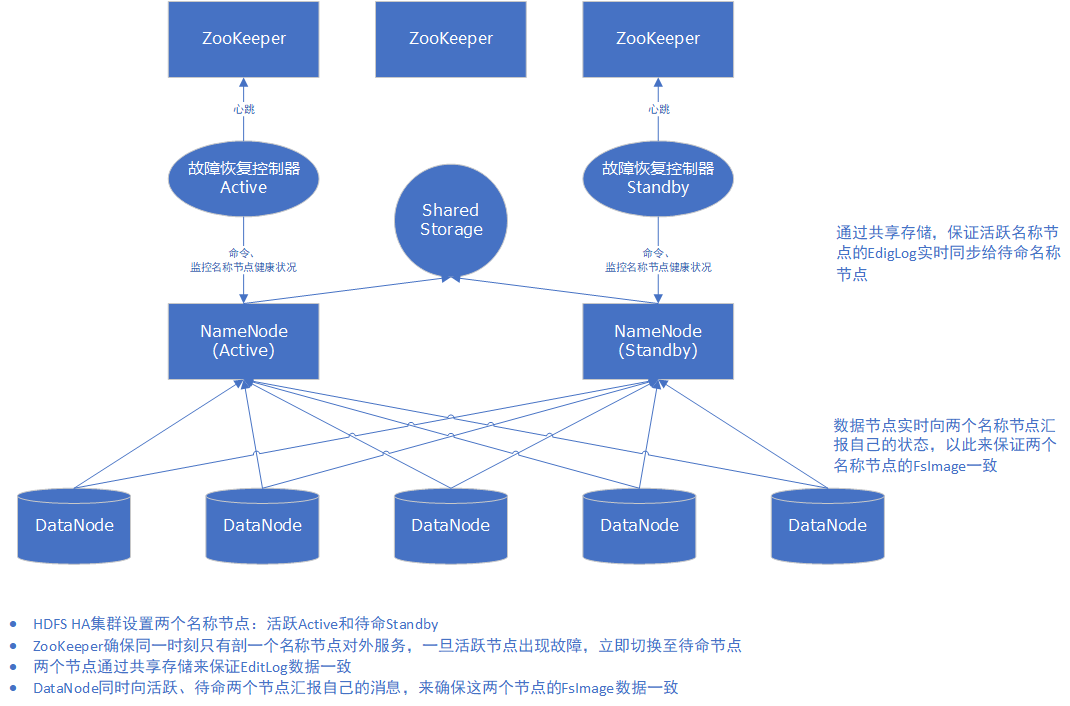
(四)HDFS高可用方案
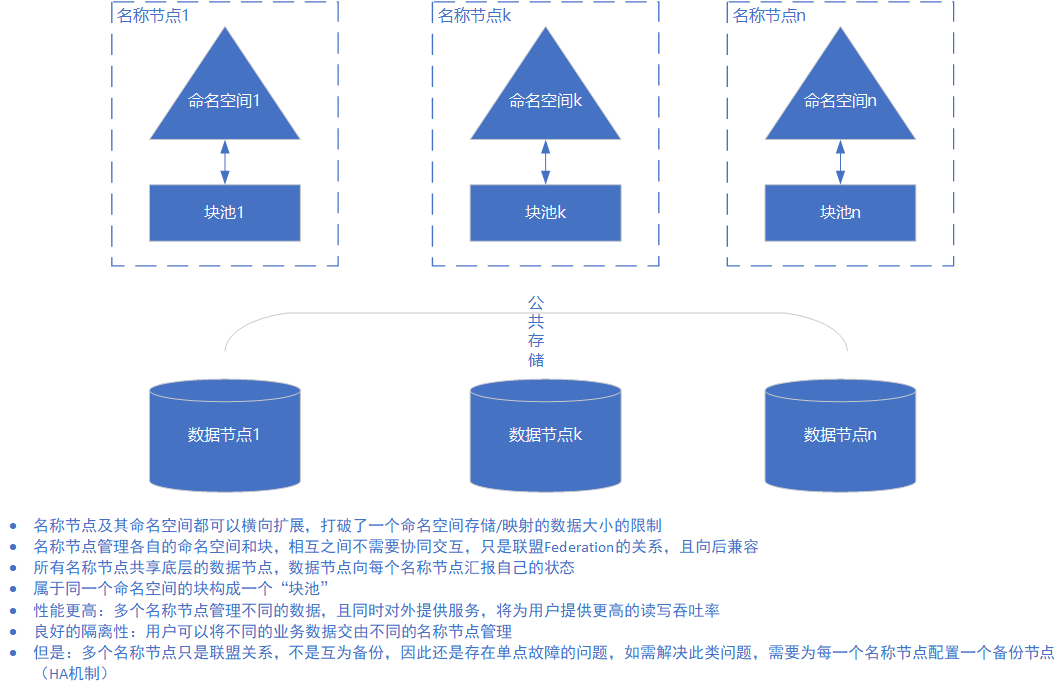
(五)HDFS Federation方案
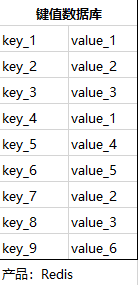
(六)NoSQL数据库
- 示例

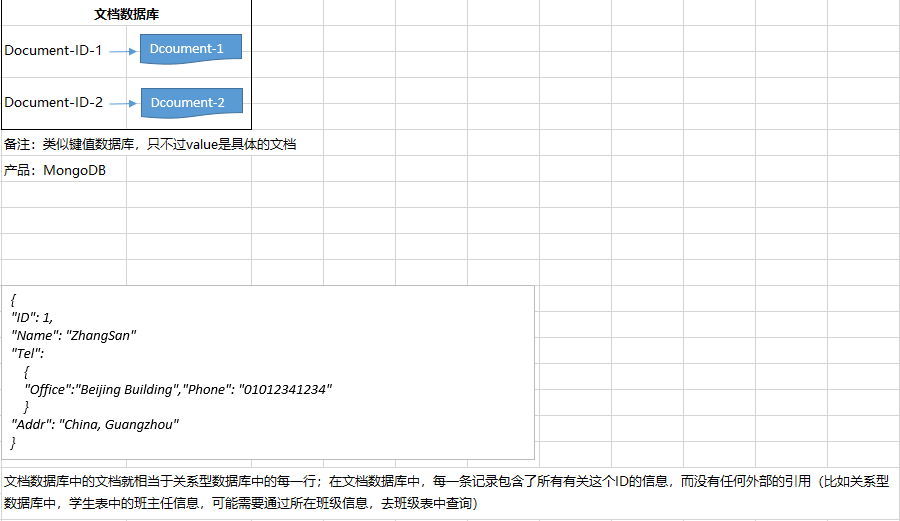
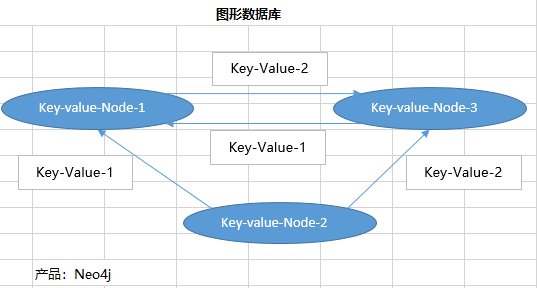
- 对比
| 主要产品 | 数据模型 | 典型应用 | 优点 | 缺点 | |
| 键值数据库 | Redis/Riak/SimpleDB | 键/值对; 键是一个字符对象;值可以是任意类型的数据,比如整型/字符型/数组/集合。 | 涉及频繁读写、拥有简单数据模型的应用; 内容缓存,比如会话、配置文件、参数、购物车等; 存储配置和用户数据信息的移动应用。 | 可扩展性好,灵活性好,大量写操作时性能高 | 无法存储结构化信息,条件查询效率较低;只能通过键来构建索引,即不能通过值来查询(比如在人员年龄的键值表中查询年龄在20-30岁之间的人员,则无法建立年龄字段的所有) |
| 列族数据库 | BigTable/Hbase | 列族 | 分布式数据存储与管理; 数据在地里上分布于多个数据中心的应用; 可以容忍副本中存在短期不一致情况的应用; 拥有动态字段的应用; 拥有潜在大量数据的应用,大到几百TB的数据。 | 查找速度快;可扩展性强,容易进行分布式扩展;复杂性低 | 功能较少,大都不支持事务一致性 |
| 文档数据库 | MongoDB/CouchDB | 键/值对; 值Value是版本化的文档; XML文档/HTML文档/JASON文档。 | 存储、索引并管理面向文档的数据或者半结构化数据; 比如用于后台具有大量读写操作的网站;使用JASON数据结构的应用;使用嵌套结构等非规范化数据的应用。 | 性能好(高并发),灵活性高、复杂性低, 数据结构灵活,提供嵌入式文档给你,将经常查询的数据结构存储在同一个文档中; 既可以根据键来构建所有,也可以根据值来构建索引。 | 缺乏统一的查询语法 |
| 图形数据库 | Neo4J | 图结构 | 专门用于处理具有高度相互关联关系的数据,比较适合于社交网络、模式识别、依赖分析、推荐系统以及路径寻找等问题 | 灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱 | 复杂度较高,只支持一定规模的数据量 |
- MongoDB
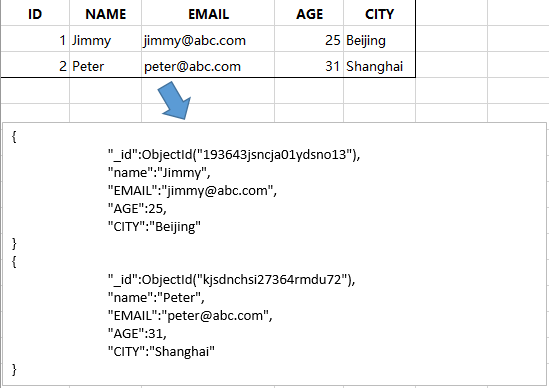

最后
以上就是任性世界最近收集整理的关于大数据学习笔记(二)(一)YARN体系结构(二)大数据的应用领域(三)协同过滤算法(四)HDFS高可用方案(五)HDFS Federation方案(六)NoSQL数据库的全部内容,更多相关大数据学习笔记(二)(一)YARN体系结构(二)大数据的应用领域(三)协同过滤算法(四)HDFS高可用方案(五)HDFS内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复