在Spark MLlib中可以做二次训练的模型
大家好,我是心情有点低落的一拳超人
今天给大家带来我整理的Spark 3.0.1 MLlib库中可以做二次训练的模型总结,首先给大家介绍一下什么是二次训练:这词是我自己想的,因为我不知道有哪些确切的表达方式,所谓二次训练就是将模型的参数,或者整个模型保存起来,然后通过new的方式新建训练类,通过训练类和上次训练出来的模型参数做第二次、第三次训练。接下来我将对Spark官方网站基于RDD的所有MLlib算法都做一遍测试,大家可以跟着目录来看。
1、可以做二次训练的模型
在Classification and Regression - RDD-based API和Clustering - RDD-based API中我找到了mllib支持的所有分类、回归、聚类的模型,不是很多,所以我打算一个个尝试。最终整理出表格如下:
| 类型 | 模型 | 是否支持 |
|---|---|---|
| 二分类 | SVMWithSGD | 支持 |
| 二分类 | LogisticRegressionWithLBFGS | 支持 |
| 二分类 | DecisionTree | 不支持 |
| 二分类 | RandomForest | 不支持 |
| 二分类 | GradientBoostedTrees | 不支持 |
| 二分类 | NaiveBayes | 不支持 |
| 多分类 | LogisticRegressionWithLBFGS | 支持 |
| 多分类 | DecisionTree | 不支持 |
| 多分类 | RandomForest | 不支持 |
| 多分类 | NaiveBayes | 不支持 |
| 回归 | DecisionTree | 不支持 |
| 回归 | RandomForest | 不支持 |
| 回归 | GradientBoostedTrees | 不支持 |
| 聚类 | KMeans | 支持 |
| 聚类 | GaussianMixture | 支持 |
| 聚类 | PowerIterationClustering | 未知 |
| 聚类 | LDA | 不支持 |
2、模型示例
按照用途分类,我对每个模型可以支持的不同场景都做了二次训练、指标打印的示例,分类共分为:二分类、多分类、回归、聚类。有一部分模型同时支持二分类、多分类、回归,我对不同类型也都做了示例。
2.1 二分类
MLlib中可以做二分类的模型有:linear SVMs, logistic regression, decision trees, random forests, gradient-boosted trees, naive Bayes 。
2.1.1 SVMWithSGD - 二分类
代码:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SVMWithSGDExample").setMaster("local[*]")
val sc = new SparkContext(conf)
// 加载数据
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\8_Spark_MLlib_Continue_Train\src\main\dataSet\sample_libsvm_data.txt"
val data: RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc, filePath)
// 切分
val Array(train, test) = data.randomSplit(Array(0.7, 0.3))
// 抽出特征、label
val testFeatures: RDD[linalg.Vector] = test.map(lp => lp.features)
val testLabel: RDD[Double] = test.map(lp => lp.label)
val numIteration = 1
var svmModel: SVMModel = null
var weights: linalg.Vector = null
val epochs = 1 to 4
for (epoch <- epochs) {
if (1.equals(epoch)) {
svmModel = SVMWithSGD.train(train, numIteration)
weights = svmModel.weights
} else {
svmModel = SVMWithSGD.train(train, numIteration, 0.05, 0.0, 0.5, svmModel.weights)
}
// 预测
val testPredict: RDD[Double] = svmModel.predict(testFeatures)
// 缝合
val labelAndPredict: RDD[(Double, Double)] = testLabel.zip(testPredict)
// 参数
val metrics: BinaryClassificationMetrics = new BinaryClassificationMetrics(labelAndPredict)
val roc: Array[(Double, Double)] = metrics.roc().collect()
val pr: Array[(Double, Double)] = metrics.pr().collect()
println(s"epoch : $epoch , roc: false positive rate , true positive rate ")
roc.foreach(println(_))
println(s"epoch : $epoch , pr: precision , recall ")
pr.foreach(println(_))
println(s"epoch : $epoch , areaUnderPR:${metrics.areaUnderPR()} , areaUnderROC:${metrics.areaUnderROC()} ")
}
}
打印结果:
epoch : 1 , roc: false positive rate , true positive rate
(0.0,0.0)
(0.0,1.0)
(1.0,1.0)
(1.0,1.0)
epoch : 1 , pr: precision , recall
(0.0,1.0)
(1.0,1.0)
(1.0,0.5641025641025641)
epoch : 1 , areaUnderPR:1.0 , areaUnderROC:1.0
epoch : 2 , roc: false positive rate , true positive rate
(0.0,0.0)
(0.0,1.0)
(1.0,1.0)
(1.0,1.0)
epoch : 2 , pr: precision , recall
(0.0,1.0)
(1.0,1.0)
(1.0,0.5641025641025641)
epoch : 2 , areaUnderPR:1.0 , areaUnderROC:1.0
epoch : 3 , roc: false positive rate , true positive rate
(0.0,0.0)
(0.0,1.0)
(1.0,1.0)
(1.0,1.0)
epoch : 3 , pr: precision , recall
(0.0,1.0)
(1.0,1.0)
(1.0,0.5641025641025641)
epoch : 3 , areaUnderPR:1.0 , areaUnderROC:1.0
epoch : 4 , roc: false positive rate , true positive rate
(0.0,0.0)
(0.0,1.0)
(1.0,1.0)
(1.0,1.0)
epoch : 4 , pr: precision , recall
(0.0,1.0)
(1.0,1.0)
(1.0,0.5641025641025641)
epoch : 4 , areaUnderPR:1.0 , areaUnderROC:1.0
可能是因为数据量不够大,官方数据100条,所以没什么变化。
2.1.2 LogisticRegressionWithLBFGS - 二分类
代码:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("LogisticRegressionWithLBFGSExample").setMaster("local[*]")
val sc = new SparkContext(conf)
// 加载数据
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\8_Spark_MLlib_Continue_Train\src\main\dataSet\sample_libsvm_data.txt"
val data = MLUtils.loadLibSVMFile(sc, filePath)
val Array(train, test) = data.randomSplit(Array(0.7, 0.3))
// 抽出features和label
val testFeatures: RDD[linalg.Vector] = test.map(lp => lp.features)
val testLabel: RDD[Double] = test.map(lp => lp.label)
val epochs = 1 to 4
var model: LogisticRegressionModel = null
for (epoch <- epochs) {
if (1.equals(epoch)) {
model = new LogisticRegressionWithLBFGS().run(train)
} else {
model = new LogisticRegressionWithLBFGS().run(train, model.weights)
}
// 预测
val predictLabel: RDD[Double] = model.predict(testFeatures)
val labelAndPredict: RDD[(Double, Double)] = testLabel.zip(predictLabel)
val metrics: BinaryClassificationMetrics = new BinaryClassificationMetrics(labelAndPredict)
val roc: Array[(Double, Double)] = metrics.roc().collect()
val pr: Array[(Double, Double)] = metrics.pr().collect()
println(s"epoch : $epoch , roc: (false positive rate , true positive rate)")
roc.foreach(println(_))
println(s"epoch : $epoch , pr: (precision , recall)")
pr.foreach(println(_))
println(s"epoch : $epoch , areaUnderROC : ${metrics.areaUnderROC()}")
println(s"epoch : $epoch , areaUnderPR : ${metrics.areaUnderPR()}")
}
打印结果:
epoch : 1 , roc: (false positive rate , true positive rate)
(0.0,0.0)
(0.07692307692307693,0.9090909090909091)
(1.0,1.0)
(1.0,1.0)
epoch : 1 , pr: (precision , recall)
(0.0,0.9523809523809523)
(0.9090909090909091,0.9523809523809523)
(1.0,0.6285714285714286)
epoch : 1 , areaUnderROC : 0.9160839160839163
epoch : 1 , areaUnderPR : 0.9376623376623375
epoch : 2 , roc: (false positive rate , true positive rate)
(0.0,0.0)
(0.07692307692307693,0.9090909090909091)
(1.0,1.0)
(1.0,1.0)
epoch : 2 , pr: (precision , recall)
(0.0,0.9523809523809523)
(0.9090909090909091,0.9523809523809523)
(1.0,0.6285714285714286)
epoch : 2 , areaUnderROC : 0.9160839160839163
epoch : 2 , areaUnderPR : 0.9376623376623375
epoch : 3 , roc: (false positive rate , true positive rate)
(0.0,0.0)
(0.07692307692307693,0.9090909090909091)
(1.0,1.0)
(1.0,1.0)
epoch : 3 , pr: (precision , recall)
(0.0,0.9523809523809523)
(0.9090909090909091,0.9523809523809523)
(1.0,0.6285714285714286)
epoch : 3 , areaUnderROC : 0.9160839160839163
epoch : 3 , areaUnderPR : 0.9376623376623375
epoch : 4 , roc: (false positive rate , true positive rate)
(0.0,0.0)
(0.07692307692307693,0.9090909090909091)
(1.0,1.0)
(1.0,1.0)
epoch : 4 , pr: (precision , recall)
(0.0,0.9523809523809523)
(0.9090909090909091,0.9523809523809523)
(1.0,0.6285714285714286)
epoch : 4 , areaUnderROC : 0.9160839160839163
epoch : 4 , areaUnderPR : 0.9376623376623375
2.1.3 DecisionTree - 二分类
经过翻查DecisionTree以及DecisionTreeModel内部的构造函数和相关函数,都没有发现可以构造相关模型的方法,下面是一次训练的代码:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("DecisionTreeClassificationExample").setMaster("local[*]")
val sc = new SparkContext(conf)
// 数据
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\8_Spark_MLlib_Continue_Train\src\main\dataSet\sample_libsvm_data.txt"
val data = MLUtils.loadLibSVMFile(sc, filePath)
val Array(train, test) = data.randomSplit(Array(0.7, 0.3))
// 参数
val numClasses = 2 // 分类
val categoricalFeaturesInfo = Map[Int, Int]() //需要分类的特征如 "sex" -> 2,表示sex分2类
val impurity = "gini" // 杂质
val maxDepth = 5 // 深度
val maxBins = 32 // 广度
// 训练
val model = DecisionTree.trainClassifier(train, numClasses, categoricalFeaturesInfo,
impurity, maxDepth, maxBins)
// 预测
val labelAndPrecit: RDD[(Double, Double)] = test.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
// 评估
val metrics = new BinaryClassificationMetrics(labelAndPrecit)
println(metrics.areaUnderPR())
println(metrics.areaUnderROC())
}
为什么没法构造模型继续训练:
构造模型继续训练应该要走下面几步:
- 1、拿到模型参数
- 2、通过参数构建负责训练的类
- 3、通过类继续训练
在决策树中有几个参数是可以拿到的:
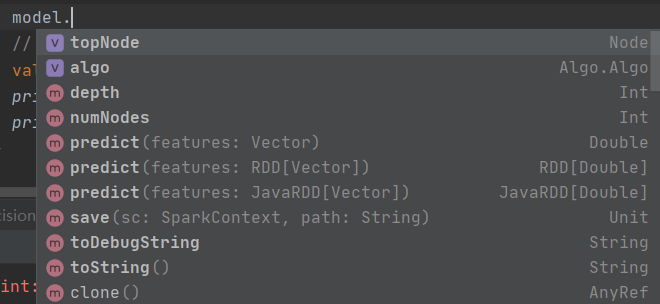
其中topNode和algo应该是构建树的关键参数。假设第一步可以完成。
在Spark 3.0.1 mllib中的算法设计中都做了分层,例如KMeans类负责训练,KMeansModel则是被训练的模型。在决策树也是一样的,DecisionTree负责训练,DecisionTreeModel负责被训练,而重新构造的话要么通过参数构造Model,通过Model去构造DecisionTree,要么直接通过参数构造DecisionTree。
DecisionTree主要函数如下:
class DecisionTree private[spark] (private val strategy: Strategy, private val seed: Int)
extends Serializable with Logging {
def this(strategy: Strategy) = this(strategy, seed = 0)
strategy.assertValid()
def run(input: RDD[LabeledPoint]): DecisionTreeModel =
}
DecisionTree伴生对象如下:
object DecisionTree extends Serializable with Logging {
def train(input: RDD[LabeledPoint], strategy: Strategy): DecisionTreeModel =
def train(
input: RDD[LabeledPoint],
algo: Algo,
impurity: Impurity,
maxDepth: Int): DecisionTreeModel =
def train(
input: RDD[LabeledPoint],
algo: Algo,
impurity: Impurity,
maxDepth: Int,
numClasses: Int): DecisionTreeModel =
def train(
input: RDD[LabeledPoint],
algo: Algo,
impurity: Impurity,
maxDepth: Int,
numClasses: Int,
maxBins: Int,
quantileCalculationStrategy: QuantileStrategy,
categoricalFeaturesInfo: Map[Int, Int]): DecisionTreeModel =
def trainClassifier(
input: RDD[LabeledPoint],
numClasses: Int,
categoricalFeaturesInfo: Map[Int, Int],
impurity: String,
maxDepth: Int,
maxBins: Int): DecisionTreeModel =
def trainClassifier(
input: JavaRDD[LabeledPoint],
numClasses: Int,
categoricalFeaturesInfo: java.util.Map[java.lang.Integer, java.lang.Integer],
impurity: String,
maxDepth: Int,
maxBins: Int): DecisionTreeModel =
def trainRegressor(
input: RDD[LabeledPoint],
categoricalFeaturesInfo: Map[Int, Int],
impurity: String,
maxDepth: Int,
maxBins: Int): DecisionTreeModel =
def trainRegressor(
input: JavaRDD[LabeledPoint],
categoricalFeaturesInfo: java.util.Map[java.lang.Integer, java.lang.Integer],
impurity: String,
maxDepth: Int,
maxBins: Int): DecisionTreeModel =
}
这两个类都没有接受topNode或者接受Model的方法或者构造函数。
2.1.4 RandomForest - 二分类
下面是一次训练的代码:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RandomForestClassificationExample").setMaster("local[*]")
val sc = new SparkContext(conf)
// 数据
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\8_Spark_MLlib_Continue_Train\src\main\dataSet\sample_libsvm_data.txt"
val data = MLUtils.loadLibSVMFile(sc, filePath)
val Array(train, test) = data.randomSplit(Array(0.7, 0.3))
val testFeatures: RDD[linalg.Vector] = test.map(lp => lp.features)
val testLabel: RDD[Double] = test.map(lp => lp.label)
// 参数
val numClasses = 2 // 分类
val categoricalFeaturesInfo = Map[Int, Int]() // 需要分类的特征
val numTrees = 3 // 树数目
val featureSubsetStrategy = "auto" // 划分子集的策略
val impurity = "gini" // 杂质
val maxDepth = 4 // 树深
val maxBins = 32 // 宽度
// 模型
val randomForestModel: RandomForestModel = RandomForest.trainClassifier(train, numClasses, categoricalFeaturesInfo, numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins)
// 预测
val predict: RDD[Double] = randomForestModel.predict(testFeatures)
val labelAndPredict: RDD[(Double, Double)] = testLabel.zip(predict)
// 评估
val metrics = new BinaryClassificationMetrics(labelAndPredict)
println(metrics.areaUnderPR())
println(metrics.areaUnderROC())
}
在随机森林中可以拿到的参数如下:
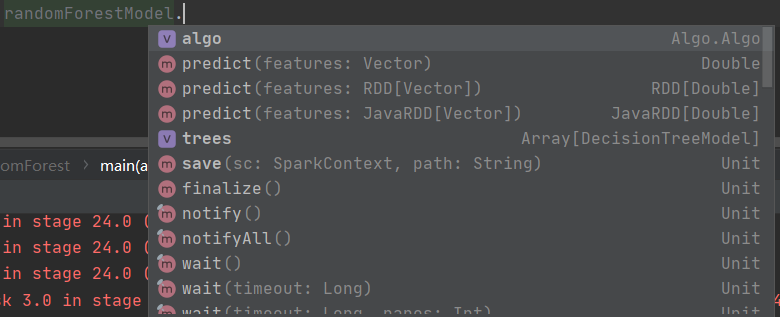
关键的参数是trees。
RandomForest类如下:
private class RandomForest (
private val strategy: Strategy,
private val numTrees: Int,
featureSubsetStrategy: String,
private val seed: Int)
extends Serializable with Logging {
def run(input: RDD[LabeledPoint]): RandomForestModel =
}
没有可以塞入trees或者RandomForestModel的地方。
RandomForest伴生对象如下:
object RandomForest extends Serializable with Logging {
def trainClassifier(
input: RDD[LabeledPoint],
strategy: Strategy,
numTrees: Int,
featureSubsetStrategy: String,
seed: Int): RandomForestModel =
def trainClassifier(
input: RDD[LabeledPoint],
numClasses: Int,
categoricalFeaturesInfo: Map[Int, Int],
numTrees: Int,
featureSubsetStrategy: String,
impurity: String,
maxDepth: Int,
maxBins: Int,
seed: Int = Utils.random.nextInt()): RandomForestModel =
def trainClassifier(
input: JavaRDD[LabeledPoint],
numClasses: Int,
categoricalFeaturesInfo: java.util.Map[java.lang.Integer, java.lang.Integer],
numTrees: Int,
featureSubsetStrategy: String,
impurity: String,
maxDepth: Int,
maxBins: Int,
seed: Int): RandomForestModel =
def trainRegressor(
input: RDD[LabeledPoint],
strategy: Strategy,
numTrees: Int,
featureSubsetStrategy: String,
seed: Int): RandomForestModel =
def trainRegressor(
input: RDD[LabeledPoint],
categoricalFeaturesInfo: Map[Int, Int],
numTrees: Int,
featureSubsetStrategy: String,
impurity: String,
maxDepth: Int,
maxBins: Int,
seed: Int = Utils.random.nextInt()): RandomForestModel =
def trainRegressor(
input: JavaRDD[LabeledPoint],
categoricalFeaturesInfo: java.util.Map[java.lang.Integer, java.lang.Integer],
numTrees: Int,
featureSubsetStrategy: String,
impurity: String,
maxDepth: Int,
maxBins: Int,
seed: Int): RandomForestModel =
}
同样的没有接受trees或者Model的函数,因此无法构建RandomForest来继续训练。
2.1.5 GradientBoostedTrees - 二分类
一次训练代码如下:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("GradientBoostedTreesClassificationExample").setMaster("local[*]")
val sc = new SparkContext(conf)
// 数据
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\8_Spark_MLlib_Continue_Train\src\main\dataSet\sample_libsvm_data.txt"
val data: RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc, filePath)
val Array(train, test) = data.randomSplit(Array(0.7, 0.3))
val testFeatures: RDD[linalg.Vector] = test.map(lp => lp.features)
val testLabel: RDD[Double] = test.map(lp => lp.label)
// 参数
val boostingStrategy = BoostingStrategy.defaultParams("Classification")
boostingStrategy.numIterations = 3 // 迭代次数
boostingStrategy.treeStrategy.numClasses = 2 // 分类
boostingStrategy.treeStrategy.maxDepth = 5 // 树深
boostingStrategy.treeStrategy.categoricalFeaturesInfo = Map[Int, Int]() // 需要分类的特征
// 模型
val gbtModel: GradientBoostedTreesModel = GradientBoostedTrees.train(train, boostingStrategy)
// 预测
val predict: RDD[Double] = gbtModel.predict(testFeatures)
val labelAndPredict: RDD[(Double, Double)] = testLabel.zip(predict)
// 评估
val metrics = new BinaryClassificationMetrics(labelAndPredict)
println(metrics.areaUnderPR()) //0.9857397504456328
println(metrics.areaUnderROC()) // 0.9705882352941176
}
在GradientBoostedTreeModel中可以拿到的参数如下:
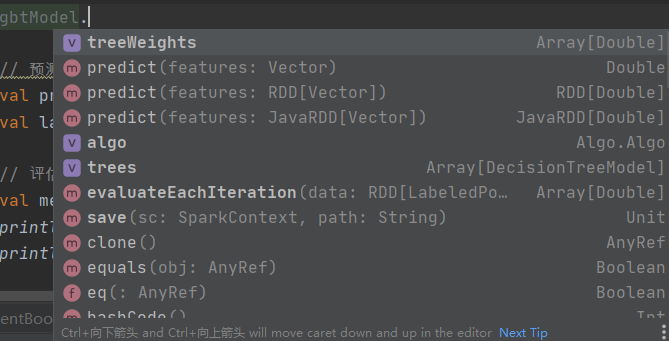
有树的权重、algo、trees,因为这个是基于决策树来做的,所以内部很多参数都跟决策树一样。包括在trees里面都是决策树模型。
同样的,在GradientBoostedTrees中有类和对应的伴生对象,内部具体函数如下:
object GradientBoostedTrees extends Logging {
def train(
input: RDD[LabeledPoint],
boostingStrategy: BoostingStrategy): GradientBoostedTreesModel =
def train(
input: JavaRDD[LabeledPoint],
boostingStrategy: BoostingStrategy): GradientBoostedTreesModel =
}
伴生对象中没有可以添加参数或者模型的方法。
class GradientBoostedTrees private[spark] (
private val boostingStrategy: BoostingStrategy,
private val seed: Int)
extends Serializable with Logging {
def this(boostingStrategy: BoostingStrategy) = this(boostingStrategy, seed = 0)
def run(input: RDD[LabeledPoint]): GradientBoostedTreesModel =
def run(input: JavaRDD[LabeledPoint]): GradientBoostedTreesModel =
def runWithValidation(
input: RDD[LabeledPoint],
validationInput: RDD[LabeledPoint]): GradientBoostedTreesModel =
def runWithValidation(
input: JavaRDD[LabeledPoint],
validationInput: JavaRDD[LabeledPoint]): GradientBoostedTreesModel =
}
同样在类中也没有可以用的构造函数和api。
2.1.6 NaiveBayes - 二分类
NaiveBayes的一次训练代码如下:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("NaiveBayesExample").setMaster("local[*]")
val sc = new SparkContext(conf)
// 数据
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\8_Spark_MLlib_Continue_Train\src\main\dataSet\sample_libsvm_data.txt"
val data = MLUtils.loadLibSVMFile(sc, filePath)
val Array(train, test) = data.randomSplit(Array(0.7, 0.3))
// 抽出features和label
val testFeatures: RDD[linalg.Vector] = test.map(lp => lp.features)
val testLabel: RDD[Double] = test.map(lp => lp.label)
// 模型
val nbModel = NaiveBayes.train(train, lambda = 1.0, modelType = "multinomial")
// 预测
val predict: RDD[Double] = nbModel.predict(testFeatures)
val labelAndPredict: RDD[(Double, Double)] = testLabel.zip(predict)
// 评估
val metrics = new BinaryClassificationMetrics(labelAndPredict)
println(metrics.areaUnderROC()) // 1.0
println(metrics.areaUnderPR()) // 1.0
}
NaiveBayesModel可以获取的参数如下:
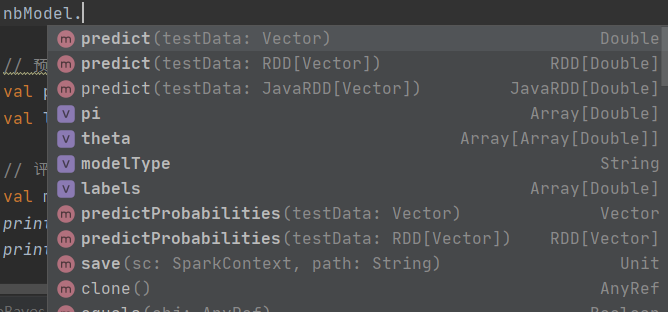
同样的,在NaiveBayes文件内有类和对应的伴生对象,都没有合适的方法可以注入参数,也没有注入模型的函数。
2.2 多分类
在上面二分类中有许多模型可以设置参数numClasses,只需要将分类从2改为大于2的数目就是多分类,而支持二次训练的模型只有LogisticRegressionWithLBFGS,具体情况在下表:
| 类型 | 模型 | 是否支持 |
|---|---|---|
| 多分类 | LogisticRegressionWithLBFGS | 支持 |
| 多分类 | DecisionTree | 不支持 |
| 多分类 | RandomForest | 不支持 |
| 多分类 | NaiveBayes | 不支持 |
2.3 回归
Spark mllib中的回归算法有: linear least squares, Lasso, ridge regression, decision trees, random forests, gradient-boosted trees, isotonic regression。接下来对所有算法一个个试是否支持二次训练。
关于前三个回归算法的介绍在Linear least squares, Lasso, and ridge regression,但是给出的案例是streaming的。
在Spark 3.0.x中,上述的回归模型 linear least squares, Lasso, ridge regression三个是没办法使用的(在网上有关于LinearRegressionWithSGD训练的博客,应该使用的是老的版本),因为其内部设计改动,只能提供给Streaming使用,例如LinearRegressionWithSGD:

点击打开LinearRegressionWithSGD的源码会发现只存在class而没有伴生对象,并且类添加了private[mllib],只能由mllib中的代码使用。所以在外部new该对象会出现构造函数不可达的错误。
同理的,LassoWithSGD、RidgeRegressionWithSGD也是一样的:


在Spark提供的官方API介绍中,这三个模型与我所使用的Spark 3.0.1源码不一致,在官方介绍中模型有run方法,并且可以接受 initialWeights,这显然是可以做二次训练的。在我将Spark版本切换至3.1.1(最新版本,同时与介绍中版本一致)时,这三个模型的源码并没有变化,应该是Spark官方没有更新。
综上,针对这三个模型做二次训练应该要切换更早的版本来做,具体哪一个版本还不清楚。
2.3.1 DecisionTree - 回归
一次训练代码如下:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("DecisionTreeClassificationExample").setMaster("local[*]")
val sc = new SparkContext(conf)
// 数据
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\8_Spark_MLlib_Continue_Train\src\main\dataSet\sample_libsvm_data.txt"
val data = MLUtils.loadLibSVMFile(sc, filePath)
val Array(train, test) = data.randomSplit(Array(0.7, 0.3))
val testFeatures: RDD[linalg.Vector] = test.map(lp => lp.features)
val testLabel: RDD[Double] = test.map(lp => lp.label)
// 参数
val categoricalFeaturesInfo = Map[Int, Int]()
val impurity = "variance"
val maxDepth = 5
val maxBins = 32
// 模型
val model = DecisionTree.trainRegressor(train, categoricalFeaturesInfo, impurity,
maxDepth, maxBins)
// 预测
val predict: RDD[Double] = model.predict(testFeatures)
val labelAndPredict: RDD[(Double, Double)] = testLabel.zip(predict)
// 评估
val metrics: RegressionMetrics = new RegressionMetrics(labelAndPredict)
println(metrics.meanAbsoluteError) // MAE 0.09375
println(metrics.meanSquaredError) // MSE 0.09374999999999999
println(metrics.r2) // R2 0.623529411764706
println(metrics.rootMeanSquaredError) // RMSE 0.30618621784789724
}
由于在二分类的时候已经了解过决策树不能做二次训练了,所以就只准备了训练的代码。
2.3.2 RandomForest - 回归
一次训练代码如下:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("DecisionTreeClassificationExample").setMaster("local[*]")
val sc = new SparkContext(conf)
// 数据
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\8_Spark_MLlib_Continue_Train\src\main\dataSet\sample_libsvm_data.txt"
val data = MLUtils.loadLibSVMFile(sc, filePath)
val Array(train, test) = data.randomSplit(Array(0.7, 0.3))
val testFeatures: RDD[linalg.Vector] = test.map(lp => lp.features)
val testLabel: RDD[Double] = test.map(lp => lp.label)
// 参数
val categoricalFeaturesInfo = Map[Int, Int]()
val numTrees = 3
val featureSubsetStrategy = "auto"
val impurity = "variance"
val maxDepth = 4
val maxBins = 32
// 模型
val model = RandomForest.trainRegressor(train, categoricalFeaturesInfo, numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins)
// 预测
val predict: RDD[Double] = model.predict(testFeatures)
val labelAndPredict: RDD[(Double, Double)] = testLabel.zip(predict)
// 评估
val metrics = new RegressionMetrics(labelAndPredict)
println(metrics.rootMeanSquaredError) // RMSE 0.12782749814122843
println(metrics.meanSquaredError) // MSE 0.016339869281045756
println(metrics.meanAbsoluteError) // MAE 0.029411764705882353
println(metrics.r2) // R2 0.9241071428571428
}
2.3.3 GradientBoostedTrees - 回归
一次训练代码:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("DecisionTreeClassificationExample").setMaster("local[*]")
val sc = new SparkContext(conf)
// 数据
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\8_Spark_MLlib_Continue_Train\src\main\dataSet\sample_libsvm_data.txt"
val data = MLUtils.loadLibSVMFile(sc, filePath)
val Array(train, test) = data.randomSplit(Array(0.7, 0.3))
val testFeatures: RDD[linalg.Vector] = test.map(lp => lp.features)
val testLabel: RDD[Double] = test.map(lp => lp.label)
// 参数
val boostingStrategy = BoostingStrategy.defaultParams("Regression")
boostingStrategy.numIterations = 3
boostingStrategy.treeStrategy.maxDepth = 5
boostingStrategy.treeStrategy.categoricalFeaturesInfo = Map[Int, Int]()
// 模型
val model: GradientBoostedTreesModel = GradientBoostedTrees.train(train, boostingStrategy)
// 预测
val predict: RDD[Double] = model.predict(testFeatures)
val labelAndPredict: RDD[(Double, Double)] = testLabel.zip(predict)
// 评估
val metrics = new RegressionMetrics(labelAndPredict)
println(metrics.rootMeanSquaredError) // RMSE 0.1889822365046136
println(metrics.meanSquaredError) // MSE 0.03571428571428571
println(metrics.meanAbsoluteError) // MAE 0.03571428571428571
println(metrics.r2) // R2 0.8362573099415205
}
2.4 聚类
在Spark官网关于聚类的算法有介绍: K-means 、 Gaussian mixture 、 Power iteration clustering (PIC) 、 Latent Dirichlet allocation (LDA) 、 Bisecting k-means 。
2.4.1 KMeans - 聚类
KMeans是支持二次训练的,代码如下:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("repeat train kmeans")
val sc = new SparkContext(conf)
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\7_Spark_mllib_params_get\src\main\dataSet\kmeans_data.txt"
val data: RDD[String] = sc.textFile(filePath)
val parsedData: RDD[linalg.Vector] = data.map(line => Vectors.dense(line.split(" ").map(_.toDouble))).cache()
val numClusters = 2
val numIterations = 20
// 反复训练
val epochs = 1 to 4
var model: KMeansModel = null
var centers: Array[linalg.Vector] = null
for (epoch <- epochs) {
println(s"第 $epoch 次训练")
if (1.equals(epoch)) {
model = KMeans.train(parsedData, numClusters, numIterations)
centers = model.clusterCenters
} else {
// 重新加载
model = new KMeansModel(centers)
val kmeans: KMeans = new KMeans().setInitialModel(model)
// 继续训练
model = kmeans.run(parsedData)
centers = model.clusterCenters
}
println(s"epoch ${epoch} ,cost = ${model.computeCost(parsedData)}")
}
}
打印结果如下:
第 1 次训练
epoch 1 ,cost = 0.11999999999999958
第 2 次训练
epoch 2 ,cost = 0.11999999999999958
第 3 次训练
epoch 3 ,cost = 0.11999999999999958
第 4 次训练
epoch 4 ,cost = 0.11999999999999958
2.4.2 GaussianMixture - 聚类
GaussianMixture 可以做二次训练,具体的代码如下:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("GaussianMixtureExample").setMaster("local[*]")
val sc = new SparkContext(conf)
// 数据
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\8_Spark_MLlib_Continue_Train\src\main\dataSet\gmm_data.txt"
val data = sc.textFile(filePath)
val parsedData = data.map(s => Vectors.dense(s.trim.split(' ').map(_.toDouble))).cache()
// 参数
val numClasses = 2
// 模型
val epochs = 1 to 4
var model: GaussianMixtureModel = null
for (epoch <- epochs) {
if (1.equals(epoch)) {
model = new GaussianMixture().setK(numClasses).run(parsedData)
}else {
val mixture: GaussianMixture = new GaussianMixture().setInitialModel(model)
model = mixture.run(parsedData)
}
// 预测
val predict: RDD[Int] = model.predict(parsedData)
// Spark未提供cost接口,要自己求
}
}
该模型内部没有提供类似KMeans中的cost接口,所以要自己求。
2.4.3 PowerIterationClustering - 聚类
没看懂Spark的案例,所以没做出来
2.4.4 LDA - 聚类
LDA应该也是没法做二次训练的,在内部的方法中除了一些正常的参数设置接口外,并没有设置模型或者关键参数的接口:
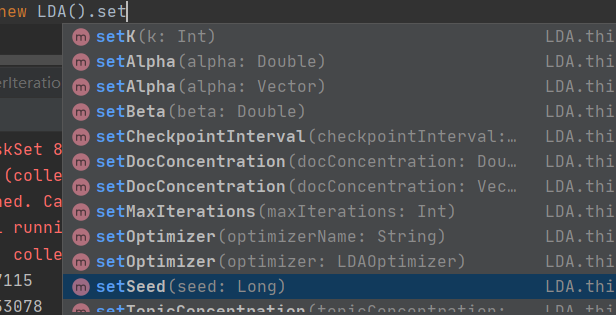
LDA的一次训练代码如下:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("KMeansExample")
val sc = new SparkContext(conf)
// 数据
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\8_Spark_MLlib_Continue_Train\src\main\dataSet\kmeans_data.txt"
val data: RDD[String] = sc.textFile(filePath)
val parsedData: RDD[linalg.Vector] = data.map(line => Vectors.dense(line.trim.split(" ").map(_.toDouble)))
// 赋予唯一ID
val corps: RDD[(Long, linalg.Vector)] = parsedData.zipWithIndex().map(_.swap).cache()
// 模型
val numClasses = 3
val model: LDAModel = new LDA().setK(numClasses).run(corps)
val matrix: Matrix = model.topicsMatrix
for (topic <- Range(0, 3)) {
print(s"Topic $topic :")
for (word <- Range(0, model.vocabSize)) {
print(s"${matrix(word, topic)}")
}
println()
}
}
3、总结
可以看到表格中大部分的模型是不支持二次训练的,也就是说很多算法只能一次批式训练成型,至于拟合的情况只能通过几次重复的训练(重头开始),调整迭代次数来做。为什么会有这个需求呢?一般我们训练模型都希望知道模型的训练进度,比如到哪一个epoch了,每个epoch对应的指标打印出来之类的,那么我就需要去整理出来,所以就有了这个表格。
new SparkContext(conf)
// 数据
val filePath = "D:\My_IDE\IDEA2019\WorkSpace\Spark-Kafka\8_Spark_MLlib_Continue_Train\src\main\dataSet\kmeans_data.txt"
val data: RDD[String] = sc.textFile(filePath)
val parsedData: RDD[linalg.Vector] = data.map(line => Vectors.dense(line.trim.split(" ").map(_.toDouble)))
// 赋予唯一ID
val corps: RDD[(Long, linalg.Vector)] = parsedData.zipWithIndex().map(_.swap).cache()
// 模型
val numClasses = 3
val model: LDAModel = new LDA().setK(numClasses).run(corps)
val matrix: Matrix = model.topicsMatrix
for (topic <- Range(0, 3)) {
print(s"Topic $topic :")
for (word <- Range(0, model.vocabSize)) {
print(s"${matrix(word, topic)}")
}
println()
}
}
## 3、总结
可以看到表格中大部分的模型是不支持二次训练的,也就是说很多算法只能一次批式训练成型,至于拟合的情况只能通过几次重复的训练(重头开始),调整迭代次数来做。为什么会有这个需求呢?一般我们训练模型都希望知道模型的训练进度,比如到哪一个epoch了,每个epoch对应的指标打印出来之类的,那么我就需要去整理出来,所以就有了这个表格。
目前做二次训练的方法我只能通过官方提供的API,如果有其他的方法或者建议请给我留言私信,非常感谢!
最后
以上就是酷酷八宝粥最近收集整理的关于Spark MLlib中支持二次训练的模型算法在Spark MLlib中可以做二次训练的模型的全部内容,更多相关Spark内容请搜索靠谱客的其他文章。








发表评论 取消回复