1. SparkMllib介绍
MLLIB是Spark的机器学习库。提供了利用Spark构建大规模和易用性的机器学习平台,组件:
五大特性:
- 1-ML算法,包含-机器学习分类算法、聚类算法、属性降维算法、协同过滤算法
- 2-特征化:特征抽取、特征转换、特征选择、特征降维
- 3-管道Pipeline:将数据处理或特征工程的流程按照管道的方式去串联
- 4-持久化Persistence:保存模型,保存管道
- 如何理解保存模型?
- 原因就是不可能每次都去训练模型,而将已经训练好的模型进行保存,保存在本地或hdfs中,在本地或hdfs中加载已经训练好点模型,直接可以做预测分析
- 如何理解保存模型?
- 5-工具:包括线性代数、统计学、数据处理科学

注意:
- 基于DataFrame是现在主要用的API
- Spark ml基于DataFrame的API
- Spark mllib基于RDD的API(2.0开始处于维护模式,将被淘汰)
Spark的各种数据结构:
-
SparkCore-----RDD
-
SparkSQL-----DataFrame和DataSet
-
SparkStreaming批处理框架----DFrame(目前Spark官网已经对SparkStreaming停止了更新)
-
StructedStreming实时流处理------DataFrame和Dataset
-
SparkMllib机器学习库
为什么SparkMllib需要从rdd转变成dataframe?
- 1-Dataframe的Api是比较友好的,基于统一的数据源、sql查询、Tungsten 和catalyst优化的各种优势
- 2-DataFrame提供多种语言的统一的API接口
- 3-DataFrame可以整合Pipeline完成管道的操作
2. SparkMllib的架构详解

从架构图可以看出MLlib主要包含三个部分:
- 底层基础:包括Spark的运行库、矩阵库和向量库;
- 算法库:包含广义线性模型、推荐系统、聚类、决策树和评估的算法;
- 实用程序:包括测试数据的生成、外部数据的读入等功能。
MLlib算法库的核心内容:
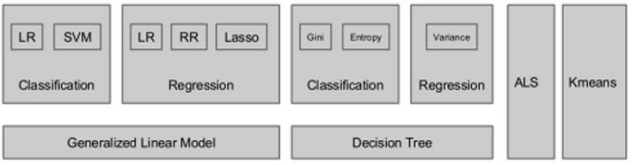
MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。
最后
以上就是粗心春天最近收集整理的关于SparkMllib原理与架构简介的全部内容,更多相关SparkMllib原理与架构简介内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复