Learning Temporal Regularity in Video Sequences
CVPR2016 无监督视频异常事件检测早期工作
摘要
由于对“有意义”的定义不明确以及场景混乱,因此在较长的视频序列中感知有意义的活动是一个具有挑战性的问题。我们通过在非常有限的监督下使用多种来源学习常规运动模式的生成模型(称为规律性)来解决此问题。体来说,我们提出了两种基于自动编码器的方法,以使其能够在很少或没有监督的情况下工作。我们首先利用传统的手工制作的时空局部特征,并在这些特征上学习完全连接的自动编码器。其次,我们构建了一个完全卷积前馈自动编码器来学习局部特征和分类器,作为端到端的学习框架。我们的模型可以从多个数据集中捕捉到规律性。我们从定性和定量两个方面对我们的方法进行了评估,展示了视频在各个方面的学习规律性,并作为应用展示了在异常检测数据集上的竞争性能。
- 这篇文章的目的:分辨长视频序列中事件的含义。以异常检测数据集为例。
- 贡献:
- 表明自动编码器可以有效地学习长时间视频中的规则动态,并可用于识别视频中的不规则。
- 使用全卷积自编码器学习我们提出的方法的低水平运动特征。
- 将该模型应用于各种应用,包括学习时间规律,检测与不规则运动相关的物体,过去和未来的帧预测,以及异常事件检测。
- 背景:目前对视频序列中有意义的事件定义还比较模糊,在有限监督或许无监督情况下有效的识别有意义的活动是一个有挑战的工作。
- 结果:我们的模型可以从多个数据集中捕捉到规律性。我们从定性和定量两个方面对我们的方法进行了评估,展示了视频在各个方面的学习规律性,并作为应用展示了在异常检测数据集上的竞争性能。
- 方法 :模型核心是利用当前最好的手工特征将一小段视频手动抽取特征,然后在利用自动编码器得到重构误差,误差就作为规则打分。
I.Introduction
大量不受控制的视频的可获得性带来了长时间观看无意义场景的问题[1]。在没有监督或监督非常有限的情况下自动分割这类视频中的“有意义的”时刻是各种计算机视觉应用的基本问题,例如视频标注[2]、摘要[3,4]、索引或时间分割[5]、异常检测[6]和活动识别[7]。我们通过对有限监督的视频的时间规律性进行建模来解决这个问题,而不是以有监督的方式对稀疏的不规则或有意义的时刻进行建模。学习有意义或显著时刻的时间视觉特征是非常具有挑战性的,因为这种时刻的定义是模糊的,即,视觉上没有界限。另一方面,学习普通时刻的时间视觉特征相对容易,因为它们通常表现出时间规律的动力学,例如周期性的人群运动.。我们专注于学习在有限标记下事件规则的模式。我们假设培训视频中的所有事件都是常规模式的一部分。特别地,我们使用多个视频源(例如,不同的数据集)来学习单个模型中视频的规则时间外观变化模式,然后该模式可以用于多个视频。仅给定常规视频的训练数据,学习常规场景的时间动态是一个无监督的学习问题。这种无监督建模的最先进方法包括稀疏编码和单词包的组合[8–10]。然而,词袋并不保留词的时空结构,并且需要关于词的数量的先验信息。此外,针对训练和测试的稀疏编码所涉及的优化在计算上非常昂贵,尤其是对于视频等大数据。
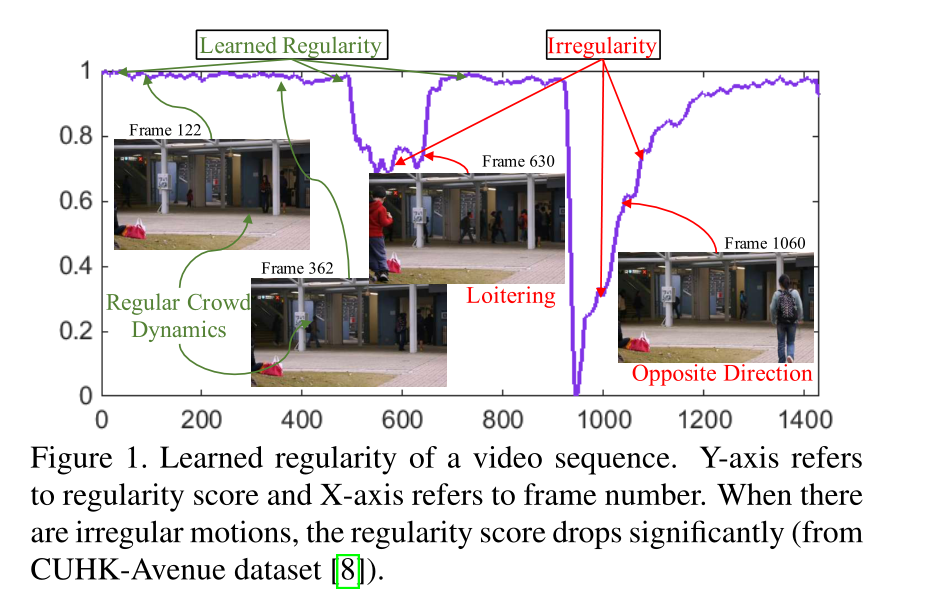 这个图表示的意思是不规则事件发生时,y轴得分变低,图中是出现踩草坪。
这个图表示的意思是不规则事件发生时,y轴得分变低,图中是出现踩草坪。
我们提出了一种基于自动编码器的方法。它的目标函数在计算上比稀疏编码更有效,并且它在编码动态时保留了时空信息。所学习的自动编码器以低误差重构规则运动,但是对于不规则运动会引起较高的重构误差。重建误差已被广泛用于异常事件检测[6],因为它是帧视觉统计的函数,并且异常表现为与正常视觉模式的偏差。 Figure 1 shows an example of learned regularity, which is computed from the reconstruction error by a learned model (Eq.3 and Eq.4).
我们提出基于以下两种类型的特征来学习时间规律的自动编码器。首先,我们使用最先进的手工制作的运动特征,学习一个基于神经网络的深度自动编码器,由七个完全连接的层组成。然而,最先进的运动特征对于学习时间规律来说可能是次优的,因为它们不是为这个问题设计或优化的。随后,我们使用基于全卷积神经网络的自编码器直接学习运动特征和判别式规则模式。
们使用多个数据集训练我们的模型,包括中大大道[8]、地铁(进入和出口)[11]和UCSD行人数据集(Ped1和Ped2)[12],而不补偿数据集偏差[13]。因此,学习到的模型可以在数据集上泛化。我们展示了我们的方法在不同的应用中发现时间规则的视频外观变化模式——综合视频中最规则的帧,描绘涉及不规则运动的物体,并从单一帧中预测过去和未来的规则运动。我们的模型也可以在多个数据集(包括最近发布的公共数据集)上执行最先进的异常检测任务。我们的贡献总结如下:
- 表明自动编码器可以有效地学习长时间视频中的规则动态,并可用于识别视频中的不规则。
- 使用全卷积自编码器学习我们提出的方法的低水平运动特征。
- 将该模型应用于各种应用,包括学习时间规律,检测与不规则运动相关的物体,过去和未来的帧预测,以及异常事件检测。
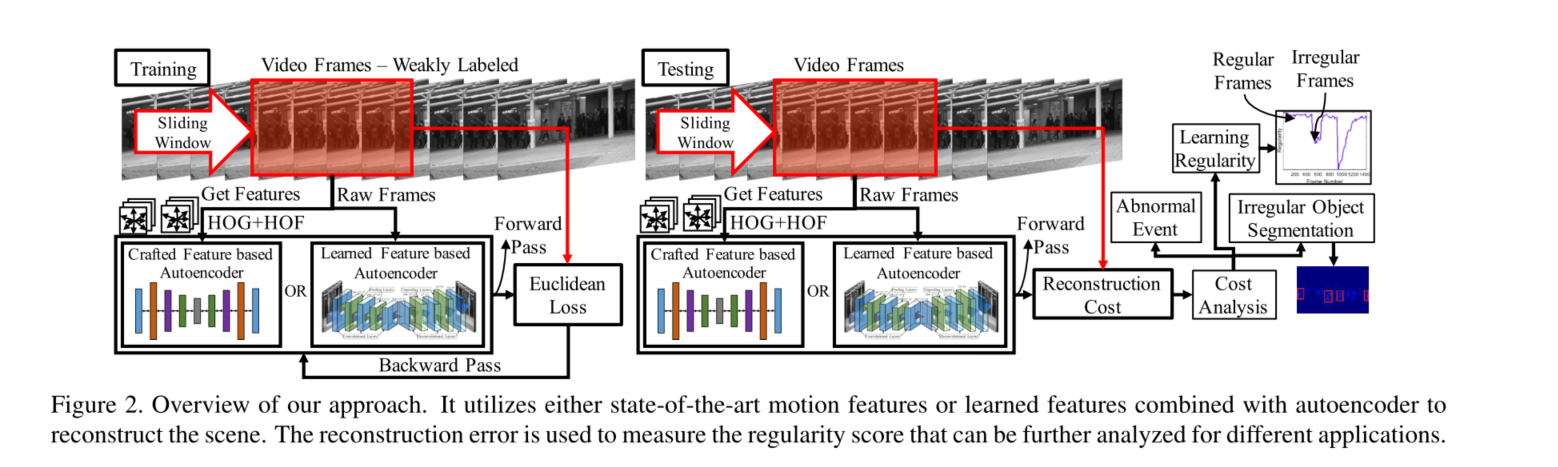
模型核心是利用当前最好的手工特征将一小段视频手动抽取特征,然后在利用自动编码器得到重构误差,误差就作为规则打分。
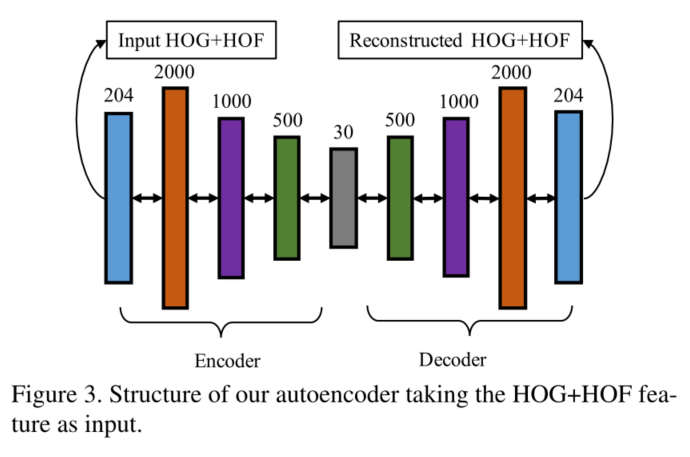
输入输出都是手工特征
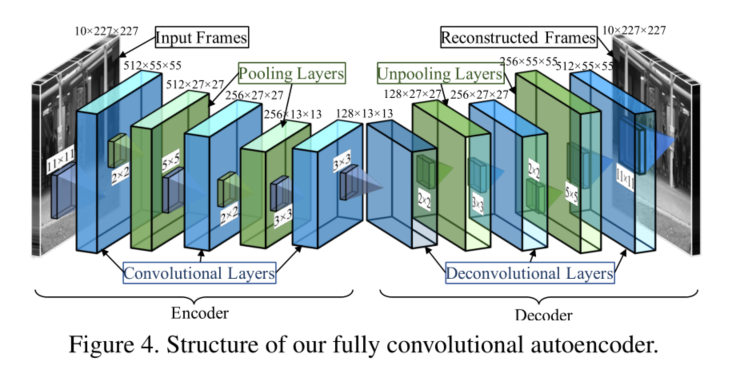
详细的模型结构
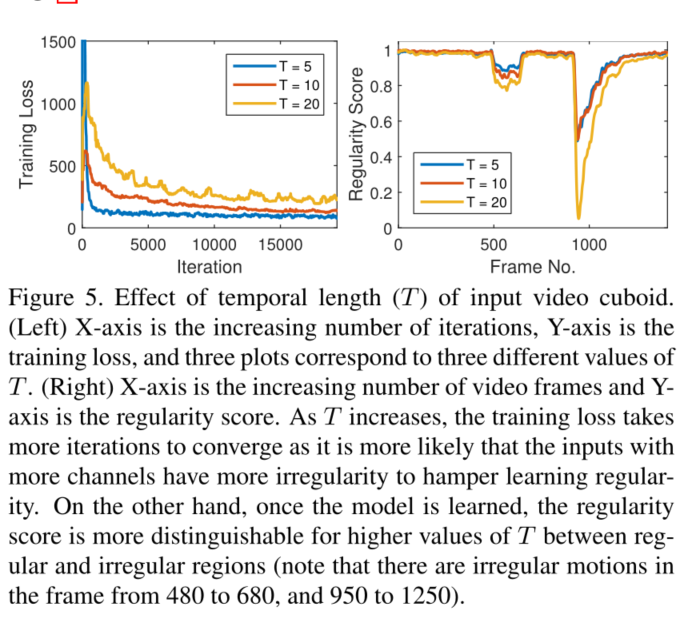
T的调参,T代表一次输入的帧数。输入帧数越多,越能准确的找到不规则。
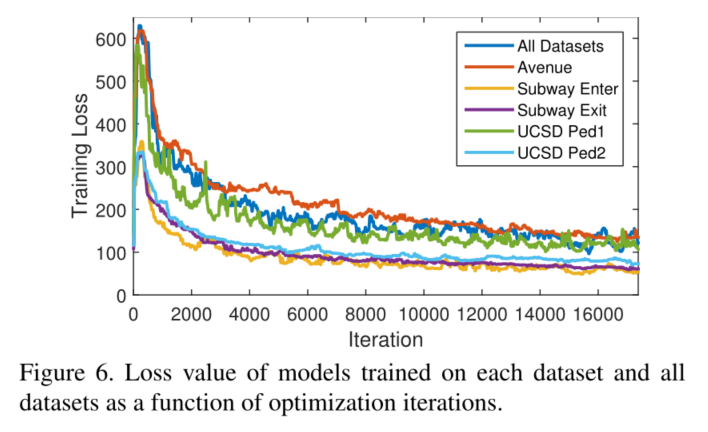
各个数据集上的训练loss变化
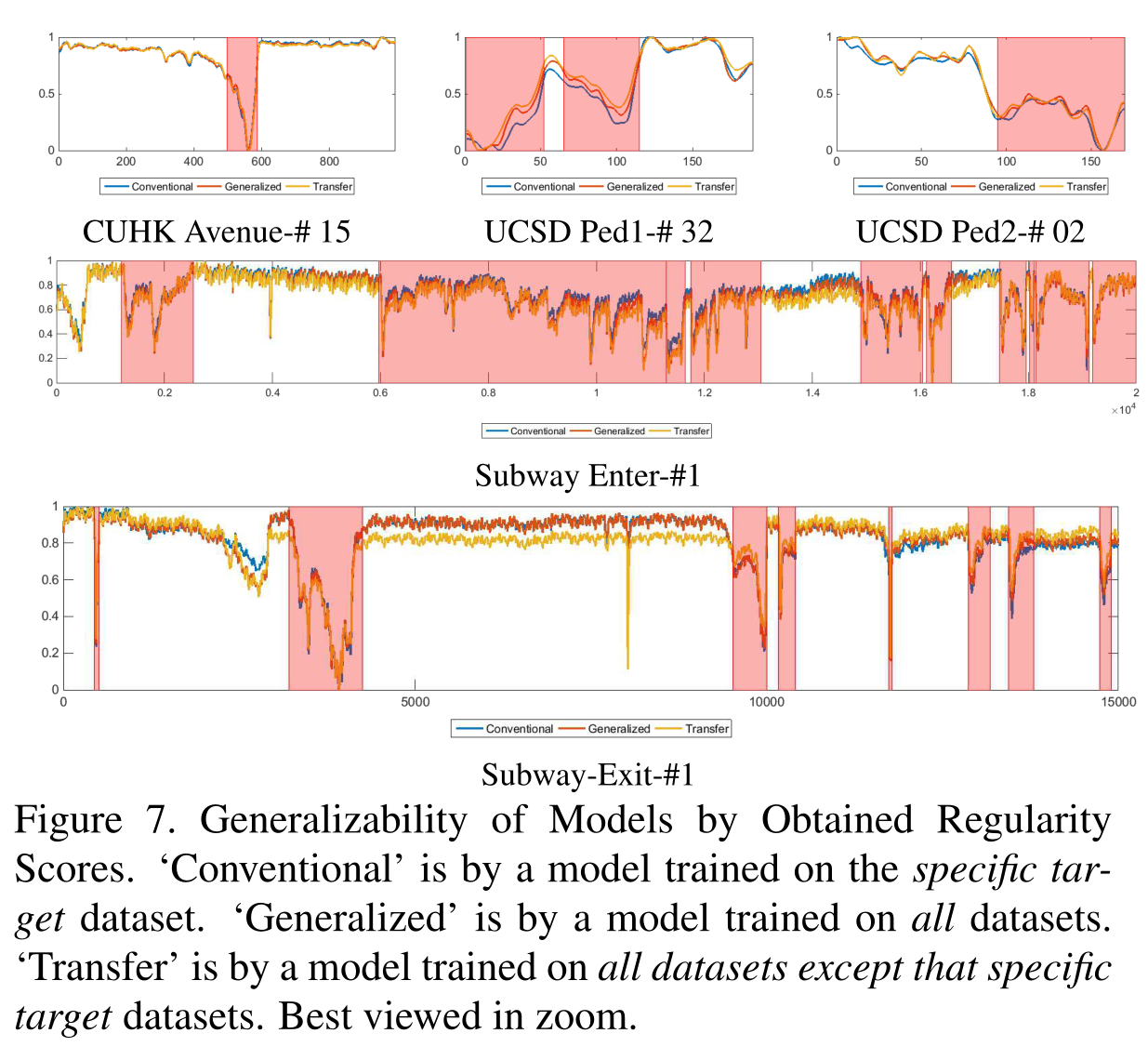

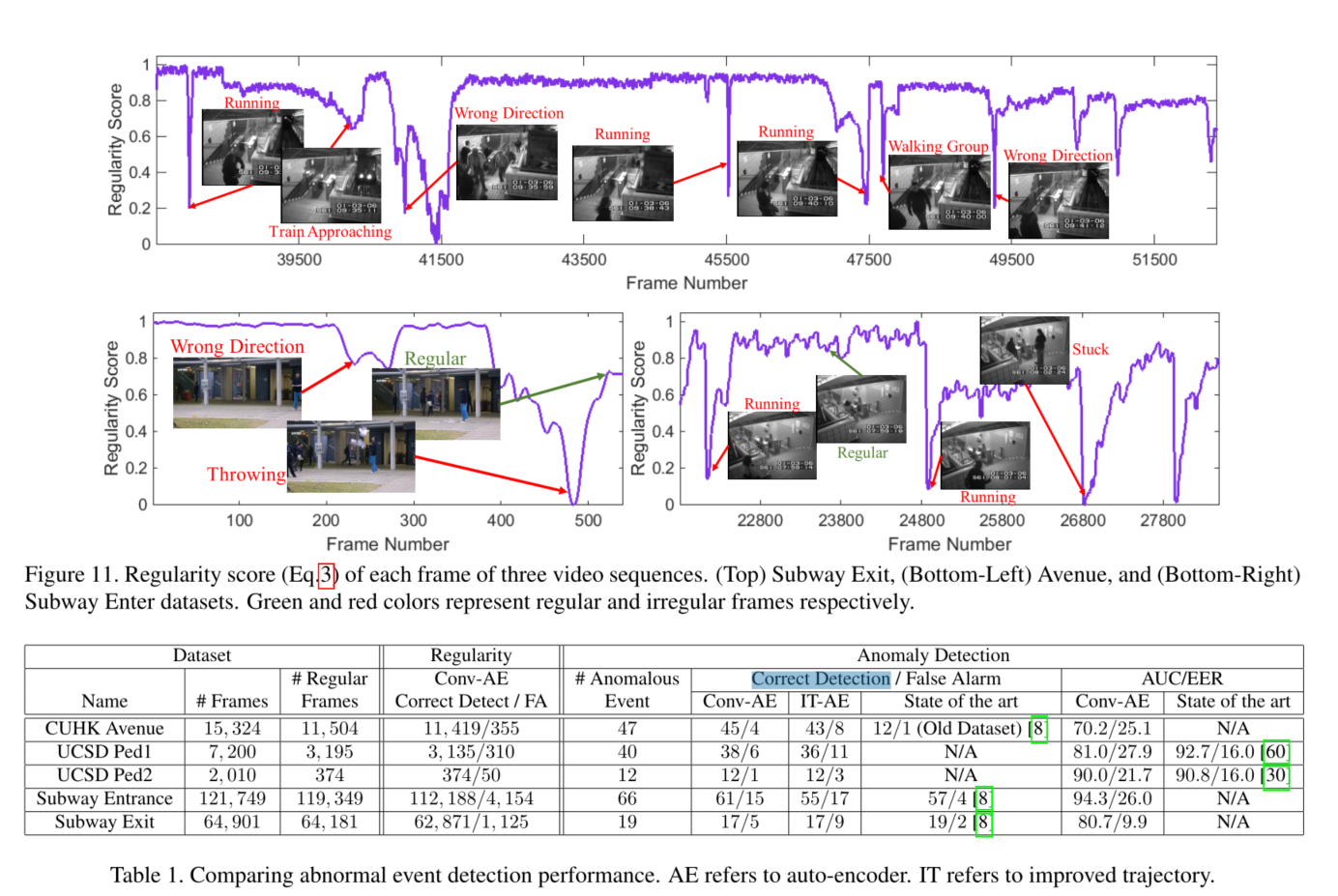
效果展示,性能对比,虽然不是最好的,但是也还可以。
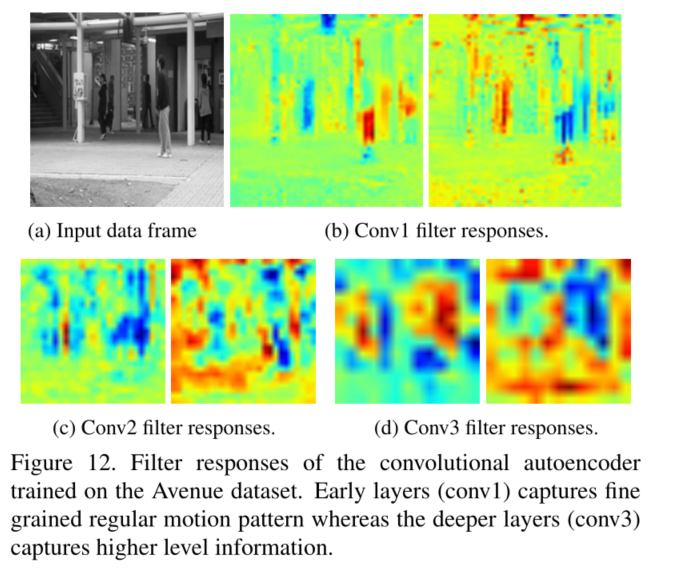
5.结论
提出了一种在有限监督下利用自动编码器学习规则模式的方法。我们首先利用传统的时空局部特征,学习一种完全连接的自动编码器。然后,我们构建了一个完全卷积的自动编码器,在一个学习框架中同时学习局部特征和分类器。即使存在潜在的数据集偏差,我们的模型也可以在多个数据集上推广。我们通过多种方式分析我们学习到的模型,比如以帧和像素为单位可视化规律性,以及在只有一张图像的情况下预测过去和未来的常规视频。对于定量分析,我们证明了我们的方法的性能优于最先进的异常检测方法。
最后
以上就是强健电源最近收集整理的关于Learning Temporal Regularity in Video Sequences——视频序列的时间规则性学习摘要I.Introduction的全部内容,更多相关Learning内容请搜索靠谱客的其他文章。



![[2021] Spatio-Temporal Graph Contrastive Learning21-Spatio-Temporal Graph Contrastive Learning](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)


![[文献阅读]——Prefix-Tuning: Optimizing Continuous Prompts for Generation前言任务介绍Prefix-Tuning实验其它](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)

发表评论 取消回复