
数据降维最为重要的是降低数据的维度的同时尽可能保有大量的原始信息,而其中最为大家熟知的是PCA和tSNE,但是这二者都存在一些问题,
PCA的速度相对很快,但代价是数据缩减后会丢很多底层的结构信息; tSNE可以保留数据的底层结构,但速度非常慢;
UMAP是2018年被提出的降维和可视化算法,它使用Uniform流形近似和投影(UMAP),既可以获得PCA的速度优势,同时还可以保留尽可能多的数据信息,而且其可视化效果也非常美观,如下:UMAP 在其当前的化身中取得了一些重大胜利。
Umap介绍
统一流形逼近和投影 (UMAP) 是一种降维技术,可用于类似于 t-SNE 的可视化,但也可用于一般的非线性降维。该算法基于对数据的三个假设:
- 数据均匀分布在黎曼流形上;
- 黎曼度量是局部常数(或可以近似);
- 流形是局部连接的。
根据这些假设,可以用模糊拓扑结构对流形进行建模。通过搜索具有最接近的等效模糊拓扑结构的数据的低维投影来找到嵌入。
首先,UMAP 速度很快。它可以毫不费力地处理大型数据集和高维数据,超出大多数 t-SNE 包可以管理的范围。这包括非常高维的稀疏数据集。 UMAP 已成功地直接用于超过一百万维的数据。
其次,UMAP 在嵌入维度上的扩展性很好——它不仅仅用于可视化!您可以使用 UMAP 作为通用降维技术,作为其他机器学习任务的初步步骤。稍加注意,它就可以与 hdbscan 集群库很好地配合(有关更多详细信息,请参阅使用 UMAP 进行集群)。
第三,与大多数 t-SNE 实现相比,UMAP 在保留数据全局结构的某些方面通常表现更好。这意味着它通常可以为您的数据提供更好的“大图”视图,并保留本地邻居关系。
第四,UMAP支持多种距离函数,包括余弦距离和相关距离等非度量距离函数。您终于可以使用余弦距离正确嵌入词向量了!
第五,UMAP 支持通过标准 sklearn 变换方法向现有嵌入添加新点。这意味着 UMAP 可以用作 sklearn 管道中的预处理转换器。
第六,UMAP 支持有监督和半监督的降维。这意味着,如果您希望将标签信息用作降维的额外信息(即使它只是部分标签),您可以这样做——就像在 fit 方法中提供它作为 y 参数一样简单。
第七,UMAP 支持多种额外的实验特性,包括: 一个“逆变换”,可以近似一个高维样本,该样本将映射到嵌入空间中的给定位置;嵌入非欧几里得空间的能力,包括双曲嵌入和具有不确定性的嵌入;还存在对嵌入数据帧的非常初步的支持。
最后,UMAP 在流形学习方面具有扎实的理论基础(参见我们关于 ArXiv 的论文)。这既证明了该方法的合理性,又允许将很快添加到库中的进一步扩展。
代码如下:
import umap
import umap.plot
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import QuantileTransformer
from sklearn.datasets import load_digits
X, y = load_digits(return_X_y=True)
pipe = make_pipeline(SimpleImputer(), QuantileTransformer())
X_processed = pipe.fit_transform(X)
manifold = umap.UMAP().fit(X_processed, y)
umap.plot.points(manifold, labels=y, theme="fire")
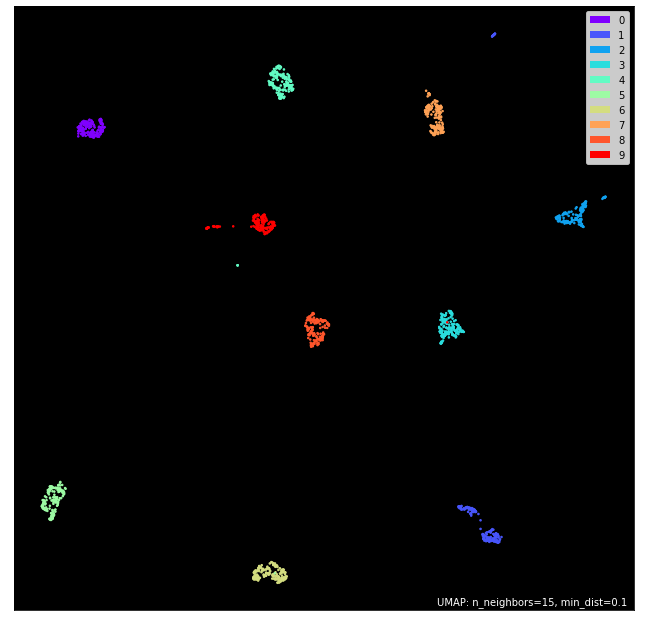
最后
以上就是粗心枕头最近收集整理的关于UMAP:强大的可视化&异常检测工具的全部内容,更多相关UMAP:强大内容请搜索靠谱客的其他文章。








发表评论 取消回复