| 序号 | 作者 | 版本 | 时间 | 备注 |
|---|---|---|---|---|
| 1 | HamaWhite | 1.0.0 | 2022-08-15 | 增加文档和源码 |
| 2 | HamaWhite | 2.0.0 | 2022-11-24 | 1.支持Watermark 2.支持UDTF 3. 改变Calcite源码修改方式 4. 升级hudi和mysql cdc版本 |
源码地址: https://github.com/HamaWhiteGG/flink-sql-lineage
一、基础知识
1.1 Apache Calcite简介
Apache Calcite是一款开源的动态数据管理框架,它提供了标准的SQL语言、多种查询优化和连接各种数据源的能力,但不包括数据存储、处理数据的算法和存储元数据的存储库。Calcite采用的是业界大数据查询框架的一种通用思路,它的目标是“one size fits all”,希望能为不同计算平台和数据源提供统一的查询引擎。Calcite作为一个强大的SQL计算引擎,在Flink内部的SQL引擎模块也是基于Calcite。
Calcite工作流程如下图所示,一般分为Parser、Validator和Converter、Optimizer阶段。

详情请参考How to screw SQL to anything with Apache Calcite
1.2 Calcite RelNode介绍
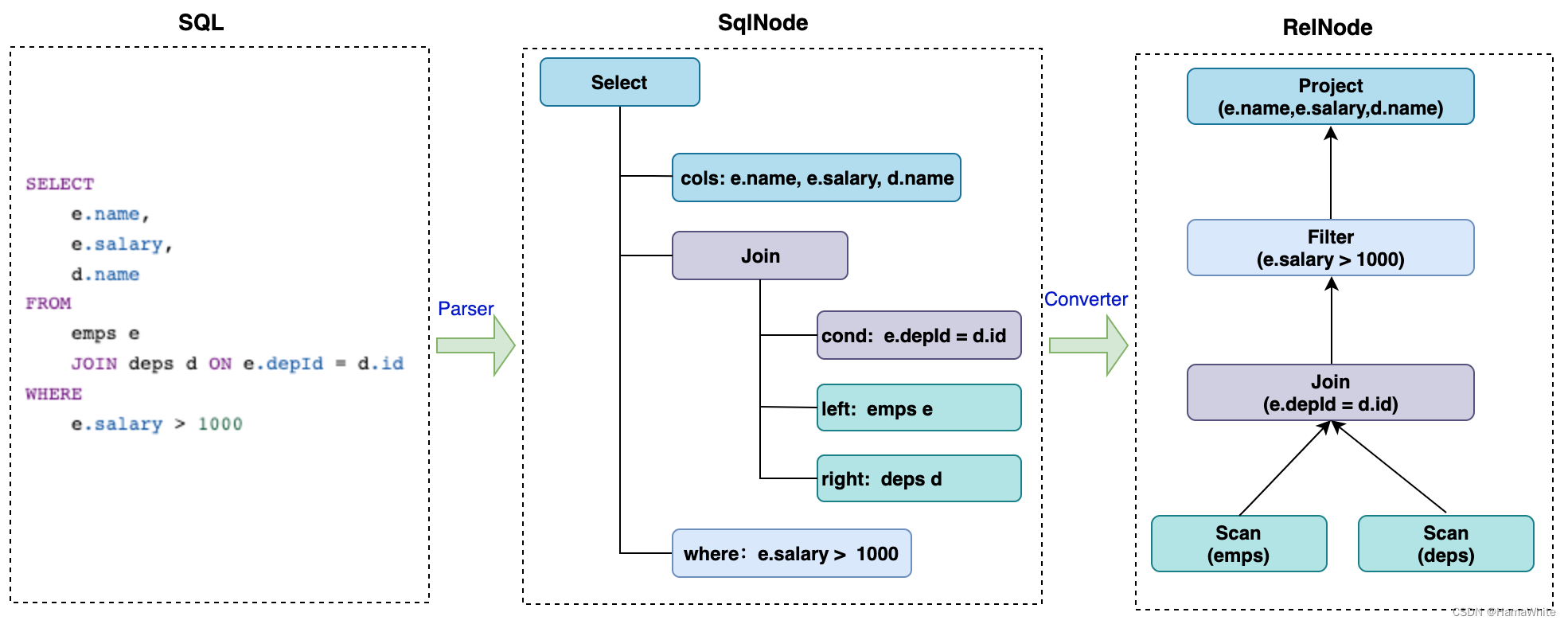
在CalciteSQL解析中,Parser解析后生成的SqlNode语法树,经过Validator校验后在Converter阶段会把SqlNode抽象语法树转为关系运算符树(RelNode Tree),如下图所示。
1.3 组件版本信息
| 组件名称 | 版本 | 备注 |
|---|---|---|
| Flink | 1.14.4 | |
| Hadoop | 3.2.2 | |
| Hive | 3.1.2 | |
| Hudi-flink1.14-bundle | 0.12.1 | |
| Flink-connector-mysql-cdc | 2.2.1 | |
| JDK | 1.8 | |
| Scala | 2.12 | 也支持2.11 |
二、字段血缘解析核心思想
2.1 FlinkSQL 执行流程解析
根据源码整理出FlinkSQL的执行流程如下图所示,主要分为五个阶段:
- Parse阶段
语法解析,使用JavaCC把SQL转换成抽象语法树(AST),在Calcite中用SqlNode来表示。
- Validate阶段
语法校验,根据元数据信息进行语法验证,例如查询的表、字段、函数是否存在,会分别对from、where、group by、having、select、orader by等子句进行validate,验证后还是SqlNode构成的语法树AST;
- Convert阶段
语义分析,根据SqlNode和元数据信息构建关系表达式RelNode树,也就是最初版本的逻辑计划。
- Optimize阶段
逻辑计划优化,优化器会基于规则进行等价变换,例如谓词下推、列裁剪等,最终得到最优的查询计划。
- Execute阶段
把逻辑查询计划翻译成物理执行计划,依次生成StreamGraph、JobGraph,最终提交运行。
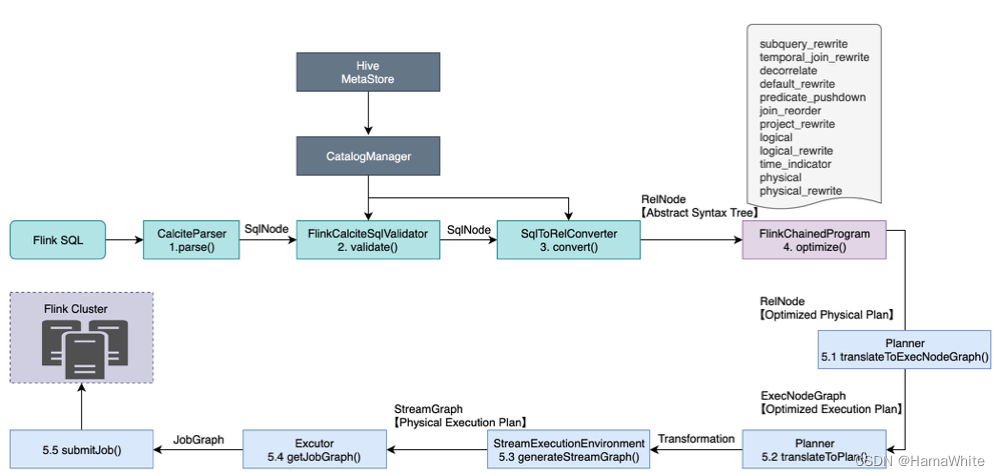
注1: 图中的Abstract Syntax Tree、Optimized Physical Plan、Optimized Execution Plan、Physical Execution Plan名称来源于StreamPlanner中的explain()方法。
注2: 相比Calcite官方工作流程图,此处把Validate和Convert分为两个阶段。
2.2 字段血缘解析思路
 FlinkSQL字段血缘解析分为三个阶段:
FlinkSQL字段血缘解析分为三个阶段:
- 对输入SQL进行Parse、Validate、Convert,生成关系表达式RelNode树,对应FlinkSQL 执行流程图中的第1、2和3步骤。
- 在优化阶段,只生成到Optimized Logical Plan即可,而非原本的Optimized Physical Plan。要修正FlinkSQL 执行流程图中的第4步骤。
- 针对上步骤优化生成的逻辑RelNode,调用RelMetadataQuery的getColumnOrigins(RelNode rel, int column)查询原始字段信息。然后构造血缘关系,并返回结果。
2.3 核心源码阐述
parseFieldLineage(String sql)方法是对外提供的字段血缘解析API,里面分别执行三大步骤。
public List<FieldLineage> parseFieldLineage(String sql) {
LOG.info("Input Sql: n {}", sql);
// 1. Generate original relNode tree
Tuple2<String, RelNode> parsed = parseStatement(sql);
String sinkTable = parsed.getField(0);
RelNode oriRelNode = parsed.getField(1);
LOG.debug("Original RelNode: n {}", oriRelNode.explain());
// 2. Optimize original relNode to generate Optimized Logical Plan
RelNode optRelNode = optimize(oriRelNode);
LOG.debug("Optimized RelNode: n {}", optRelNode.explain());
// 3. Build lineage based from RelMetadataQuery
return buildFiledLineageResult(sinkTable, optRelNode);
}
2.3.1 根据SQL生成RelNode树
调用ParserImpl.List parse(String statement) 方法即可,然后返回第一个operation中的calciteTree。此代码限制只支持Insert的血缘关系。
private Tuple2<String, RelNode> parseStatement(String sql) {
List<Operation> operations = tableEnv.getParser().parse(sql);
if (operations.size() != 1) {
throw new TableException(
"Unsupported SQL query! only accepts a single SQL statement.");
}
Operation operation = operations.get(0);
if (operation instanceof CatalogSinkModifyOperation) {
CatalogSinkModifyOperation sinkOperation = (CatalogSinkModifyOperation) operation;
PlannerQueryOperation queryOperation = (PlannerQueryOperation) sinkOperation.getChild();
RelNode relNode = queryOperation.getCalciteTree();
return new Tuple2<>(
sinkOperation.getTableIdentifier().asSummaryString(),
relNode);
} else {
throw new TableException("Only insert is supported now.");
}
}
2.3.2 生成Optimized Logical Plan
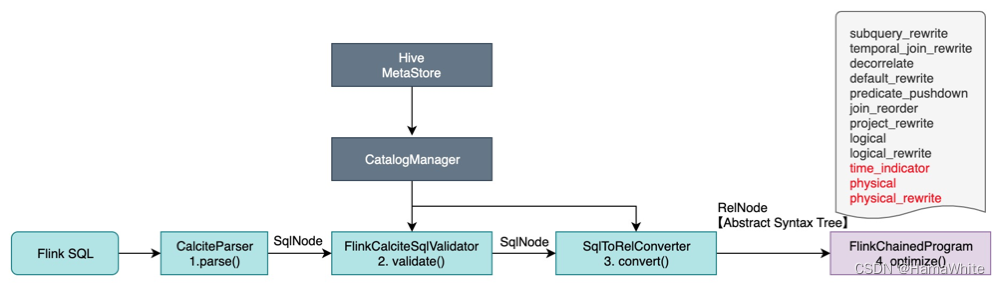
在第4步骤的逻辑计划优化阶段,根据源码可知核心是调用FlinkStreamProgram的中的优化策略,共包含12个阶段(subquery_rewrite、temporal_join_rewrite…logical_rewrite、time_indicator、physical、physical_rewrite),优化后生成的是Optimized Pysical Plan。
根据SQL的字段血缘解析原理可知,只要解析到logical_rewrite优化后即可,因此复制FlinkStreamProgram源码为FlinkStreamProgramWithoutPhysical类,并删除time_indicator、physical、physical_rewrite策略及最后面chainedProgram.addLast相关代码。然后调用optimize方法核心代码如下:
// this.flinkChainedProgram = FlinkStreamProgramWithoutPhysical.buildProgram(configuration);
/**
* Calling each program's optimize method in sequence.
*/
private RelNode optimize(RelNode relNode) {
return flinkChainedProgram.optimize(relNode, new StreamOptimizeContext() {
@Override
public boolean isBatchMode() {
return false;
}
@Override
public TableConfig getTableConfig() {
return tableEnv.getConfig();
}
@Override
public FunctionCatalog getFunctionCatalog() {
return ((PlannerBase)tableEnv.getPlanner()).getFlinkContext().getFunctionCatalog();
}
@Override
public CatalogManager getCatalogManager() {
return tableEnv.getCatalogManager();
}
@Override
public SqlExprToRexConverterFactory getSqlExprToRexConverterFactory() {
return relNode.getCluster().getPlanner().getContext().unwrap(FlinkContext.class).getSqlExprToRexConverterFactory();
}
@Override
public <C> C unwrap(Class<C> clazz) {
return StreamOptimizeContext.super.unwrap(clazz);
}
@Override
public FlinkRelBuilder getFlinkRelBuilder() {
return ((PlannerBase)tableEnv.getPlanner()).getRelBuilder();
}
@Override
public boolean needFinalTimeIndicatorConversion() {
return true;
}
@Override
public boolean isUpdateBeforeRequired() {
return false;
}
@Override
public MiniBatchInterval getMiniBatchInterval() {
return MiniBatchInterval.NONE;
}
});
}
注: 此代码可参考StreamCommonSubGraphBasedOptimizer中的optimizeTree方法来书写。
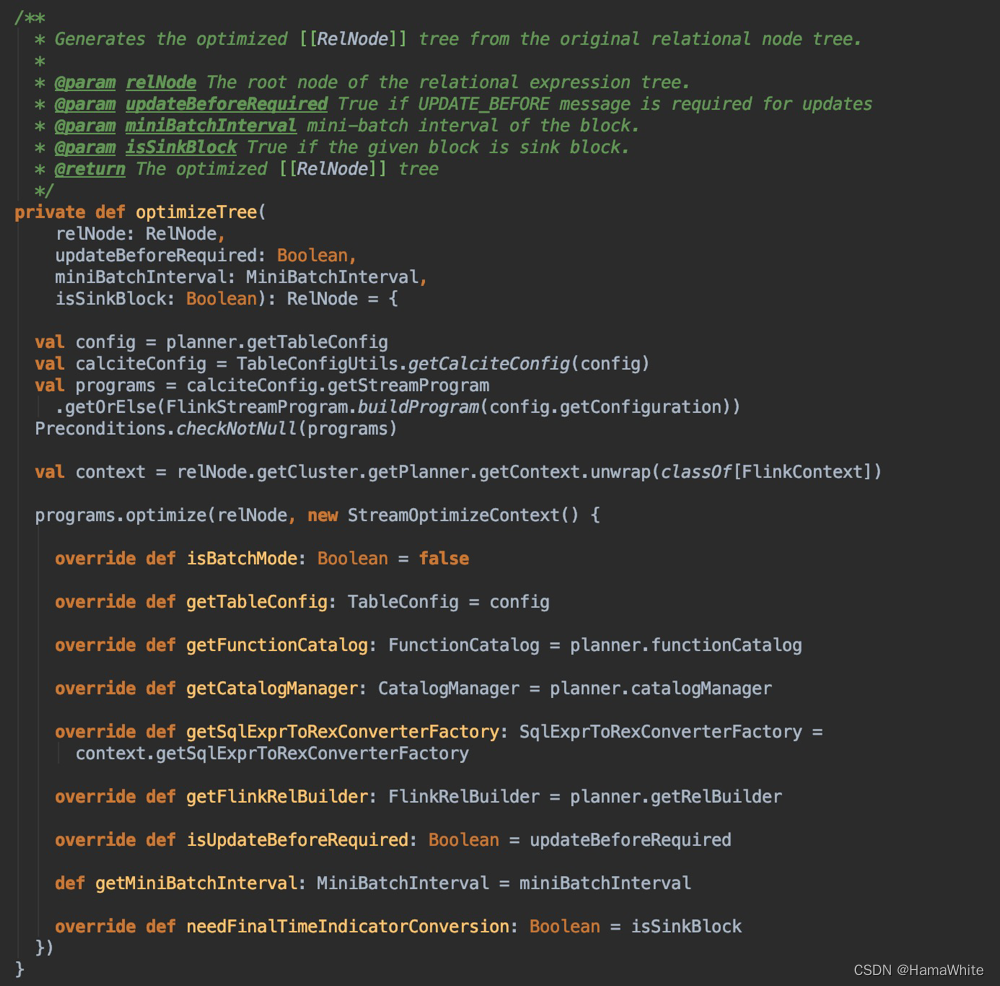
2.3.3 查询原始字段并构造血缘
调用RelMetadataQuery的getColumnOrigins(RelNode rel, int column)查询原始字段信息,然后构造血缘关系,并返回结果。
buildFiledLineageResult(String sinkTable, RelNode optRelNode)
private List<FieldLineage> buildFiledLineageResult(String sinkTable, RelNode optRelNode) {
// target columns
List<String> targetColumnList = tableEnv.from(sinkTable)
.getResolvedSchema()
.getColumnNames();
RelMetadataQuery metadataQuery = optRelNode.getCluster().getMetadataQuery();
List<FieldLineage> fieldLineageList = new ArrayList<>();
for (int index = 0; index < targetColumnList.size(); index++) {
String targetColumn = targetColumnList.get(index);
LOG.debug("**********************************************************");
LOG.debug("Target table: {}", sinkTable);
LOG.debug("Target column: {}", targetColumn);
Set<RelColumnOrigin> relColumnOriginSet = metadataQuery.getColumnOrigins(optRelNode, index);
if (CollectionUtils.isNotEmpty(relColumnOriginSet)) {
for (RelColumnOrigin relColumnOrigin : relColumnOriginSet) {
// table
RelOptTable table = relColumnOrigin.getOriginTable();
String sourceTable = String.join(".", table.getQualifiedName());
// filed
int ordinal = relColumnOrigin.getOriginColumnOrdinal();
List<String> fieldNames = table.getRowType().getFieldNames();
String sourceColumn = fieldNames.get(ordinal);
LOG.debug("----------------------------------------------------------");
LOG.debug("Source table: {}", sourceTable);
LOG.debug("Source column: {}", sourceColumn);
// add record
fieldLineageList.add(buildRecord(sourceTable, sourceColumn, sinkTable, targetColumn));
}
}
}
return fieldLineageList;
}
三、测试结果
详细测试用例可查看代码中的单测,此处只描述两个测试点。
3.1 建表语句
下面新建三张表,分别是: ods_mysql_users、dim_mysql_company和dwd_hudi_users。
3.1.1 新建mysql cdc table-ods_mysql_users
DROP TABLE IF EXISTS ods_mysql_users;
CREATE TABLE ods_mysql_users(
id BIGINT,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
proc_time as proctime()
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.90.xxx',
'port' = '3306',
'username' = 'root',
'password' = 'xxx',
'server-time-zone' = 'Asia/Shanghai',
'database-name' = 'demo',
'table-name' = 'users'
);
3.1.2 新建mysql dim table-dim_mysql_company
DROP TABLE IF EXISTS dim_mysql_company;
CREATE TABLE dim_mysql_company (
user_id BIGINT,
company_name STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.90.xxx:3306/demo?useSSL=false&characterEncoding=UTF-8',
'username' = 'root',
'password' = 'xxx',
'table-name' = 'company'
);
3.1.3 新建hudi sink table-dwd_hudi_users
DROP TABLE IF EXISTS dwd_hudi_users;
CREATE TABLE dwd_hudi_users (
id BIGINT,
name STRING,
company_name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
`partition` VARCHAR(20)
) PARTITIONED BY (`partition`) WITH (
'connector' = 'hudi',
'table.type' = 'COPY_ON_WRITE',
'path' = 'hdfs://192.168.90.xxx:9000/hudi/dwd_hudi_users',
'read.streaming.enabled' = 'true',
'read.streaming.check-interval' = '1'
);
3.2 测试SQL及血缘结果
3.2.1 测试insert-select
- 测试SQL
INSERT INTO
dwd_hudi_users
SELECT
id,
name,
name as company_name,
birthday,
ts,
DATE_FORMAT(birthday, 'yyyyMMdd')
FROM
ods_mysql_users
- 测试结果
| sourceTable | sourceColumn | targetTable | targetColumn |
|---|---|---|---|
| ods_mysql_users | id | dwd_hudi_users | id |
| ods_mysql_users | name | dwd_hudi_users | name |
| ods_mysql_users | name | dwd_hudi_users | company_name |
| ods_mysql_users | birthday | dwd_hudi_users | birthday |
| ods_mysql_users | ts | dwd_hudi_users | ts |
| ods_mysql_users | birthday | dwd_hudi_users | partition |
3.2.2 测试insert-select-table-join
- 测试SQL
SELECT
a.id as id1,
CONCAT(a.name, b.company_name),
b.company_name,
a.birthday,
a.ts,
DATE_FORMAT(a.birthday, 'yyyyMMdd') as p
FROM
ods_mysql_users as a
JOIN
dim_mysql_company as b
ON a.id = b.user_id
-
RelNode树展示
Original RelNode
LogicalProject(id1=[$0], EXPR$1=[CONCAT($1, $6)], company_name=[$6], birthday=[$2], ts=[$3], p=[DATE_FORMAT($2, _UTF-16LE'yyyyMMdd')])
LogicalJoin(condition=[=($0, $5)], joinType=[inner])
LogicalProject(id=[$0], name=[$1], birthday=[$2], ts=[$3], proc_time=[PROCTIME()])
LogicalTableScan(table=[[hive, flink_demo, ods_mysql_users]])
LogicalTableScan(table=[[hive, flink_demo, dim_mysql_company]])
经过optimize(RelNode relNode)优化后的Optimized RelNode结果如下:
FlinkLogicalCalc(select=[id AS id1, CONCAT(name, company_name) AS EXPR$1, company_name, birthday, ts, DATE_FORMAT(birthday, _UTF-16LE'yyyyMMdd') AS p])
FlinkLogicalJoin(condition=[=($0, $4)], joinType=[inner])
FlinkLogicalTableSourceScan(table=[[hive, flink_demo, ods_mysql_users]], fields=[id, name, birthday, ts])
FlinkLogicalTableSourceScan(table=[[hive, flink_demo, dim_mysql_company]], fields=[user_id, company_name])
- 测试结果
| sourceTable | sourceColumn | targetTable | targetColumn |
|---|---|---|---|
| ods_mysql_users | id | dwd_hudi_users | id |
| dim_mysql_company | company_name | dwd_hudi_users | name |
| ods_mysql_users | name | dwd_hudi_users | name |
| dim_mysql_company | company_name | dwd_hudi_users | company_name |
| ods_mysql_users | birthday | dwd_hudi_users | birthday |
| ods_mysql_users | ts | dwd_hudi_users | ts |
| ods_mysql_users | birthday | dwd_hudi_users | partition |
3.2.3 测试insert-select-lookup-join
上述步骤完成后还不支持Lookup Join的字段血缘解析,测试情况如下所述。
- 测试SQL
SELECT
a.id as id1,
CONCAT(a.name, b.company_name),
b.company_name,
a.birthday,
a.ts,
DATE_FORMAT(a.birthday, 'yyyyMMdd') as p
FROM
ods_mysql_users as a
JOIN
dim_mysql_company FOR SYSTEM_TIME AS OF a.proc_time AS b
ON a.id = b.user_id
- 测试结果
| sourceTable | sourceColumn | targetTable | targetColumn |
|---|---|---|---|
| ods_mysql_users | id | dwd_hudi_users | id |
| ods_mysql_users | name | dwd_hudi_users | name |
| ods_mysql_users | birthday | dwd_hudi_users | birthday |
| ods_mysql_users | ts | dwd_hudi_users | ts |
| ods_mysql_users | birthday | dwd_hudi_users | partition |
可以看到,维表dim_mysql_company的字段血缘关系都被丢失掉,因此继续进行下面的步骤。
四、修改Calcite源码支持Lookup Join
4.1 实现思路
针对Lookup Join,Parser会把SQL语句“FOR SYSTEM_TIME AS OF ”解析成 SqlSnapshot ( SqlNode),validate() 将其转换成 LogicalSnapshot(RelNode)。
Lookup Join-Original RelNode
LogicalProject(id1=[$0], EXPR$1=[CONCAT($1, $6)], company_name=[$6], birthday=[$2], ts=[$3], p=[DATE_FORMAT($2, _UTF-16LE'yyyyMMdd')])
LogicalCorrelate(correlation=[$cor0], joinType=[inner], requiredColumns=[{0, 4}])
LogicalProject(id=[$0], name=[$1], birthday=[$2], ts=[$3], proc_time=[PROCTIME()])
LogicalTableScan(table=[[hive, flink_demo, ods_mysql_users]])
LogicalFilter(condition=[=($cor0.id, $0)])
LogicalSnapshot(period=[$cor0.proc_time])
LogicalTableScan(table=[[hive, flink_demo, dim_mysql_company]])
但calcite-core中RelMdColumnOrigins这个Handler类里并没有处理Snapshot类型的RelNode,导致返回空,继而丢失Lookup Join字段的血缘关系。因此,需要在RelMdColumnOrigins增加一个处理Snapshot的getColumnOrigins(Snapshot rel,RelMetadataQuery mq, int iOutputColumn)方法。
由于flink-table-planner是采用maven-shade-plugin打包的,因此修改calcite-core后要重新打flink包。flink-table/flink-table-planner/pom.xml。
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
...
<artifactSet>
<includes combine.children="append">
<include>org.apache.calcite:*</include>
<include>org.apache.calcite.avatica:*</include>
...
本文在下面的4.2-4.4小节给出基础性操作步骤,分别讲述如何修改calcite、flink源码,以及如何编译、打包。
同时在4.5小节也提供另外一种实现路径,即通过动态编辑Java字节码技术来增加getColumnOrigins方法,源码已默认采用此技术,读者也可直接跳到4.5小节进行阅读。
4.2 重新编译Calcite源码
4.2.1 下载源码及创建分支
flink1.14.4依赖的calcite版本是1.26.0,因此基于tag calcite-1.26.0来修改源码。并且在原有3位版本号后面再增加一位版本号,以区别于官方发布的版本。
# 下载github上源码
$ git clone git@github.com:apache/calcite.git
# 切换到 calcite-1.26.0 tag
$ git checkout calcite-1.26.0
# 新建分支calcite-1.26.0.1
$ git checkout -b calcite-1.26.0.1
4.2.2 修改源码
- 在calcite-core模块,给RelMdColumnOrigins类增加方法 getColumnOrigins(Snapshot rel,RelMetadataQuery mq, int iOutputColumn)。org.apache.calcite.rel.metadata.RelMdColumnOrigins
public Set<RelColumnOrigin> getColumnOrigins(Snapshot rel,
RelMetadataQuery mq, int iOutputColumn) {
return mq.getColumnOrigins(rel.getInput(), iOutputColumn);
}
- 修改版本号为 1.26.0.1,calcite/gradle.properties
# 修改前
calcite.version=1.26.0
# 修改后
calcite.version=1.26.0.1
-
删除打包名称上的SNAPSHOT,由于未研究出Gradlew 打包参数,此处直接修改build.gradle.kts代码。
calcite/build.gradle.kts
# 修改前
val buildVersion = "calcite".v + releaseParams.snapshotSuffix
#修改后
val buildVersion = "calcite".v
4.2.3 编译源码和推送到本地仓库
# 编译源码
$ ./gradlew build -x test
# 推送到本地仓库
$ ./gradlew publishToMavenLocal
运行成功后查看本地maven仓库,已经产生calcite-core-1.26.0.1.jar。
$ ll ~/.m2/repository/org/apache/calcite/calcite-core/1.26.0.1
-rw-r--r-- 1 baisong staff 8893065 8 9 13:51 calcite-core-1.26.0.1-javadoc.jar
-rw-r--r-- 1 baisong staff 3386193 8 9 13:51 calcite-core-1.26.0.1-sources.jar
-rw-r--r-- 1 baisong staff 2824504 8 9 13:51 calcite-core-1.26.0.1-tests.jar
-rw-r--r-- 1 baisong staff 5813238 8 9 13:51 calcite-core-1.26.0.1.jar
-rw-r--r-- 1 baisong staff 5416 8 9 13:51 calcite-core-1.26.0.1.pom
4.3 重新编译Flink源码
4.2.1 下载源码及创建分支
基于tag calcite-1.26.0来修改源码。并且在原有3位版本号后面再增加一位版本号,以区别于官方发布的版本。
# 下载github上flink源码
$ git clone git@github.com:apache/flink.git
# 切换到 release-1.14.4 tag
$ git checkout release-1.14.4
# 新建分支release-1.14.4.1
$ git checkout -b release-1.14.4.1
4.3.2 修改源码
- 在flink-table模块,修改calcite.version的版本为 1.26.0.1,flink-table-planner会引用此版本号。即让flink-table-planner引用calcite-core-1.26.0.1。flink/flink-table/pom.xml。
<properties>
<!-- When updating Janino, make sure that Calcite supports it as well. -->
<janino.version>3.0.11</janino.version>
<!--<calcite.version>1.26.0</calcite.version>-->
<calcite.version>1.26.0.1</calcite.version>
<guava.version>29.0-jre</guava.version>
</properties>
- 修改flink-table-planner版本号为1.14.4.1,包含下面3点。flink/flink-table/flink-table-planner/pom.xml。
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<!--1.新增此行-->
<version>1.14.4.1</version>
<name>Flink : Table : Planner</name>
<!--2. 全局替换${project.version}为${parent.version}-->
<!--3.新增加此依赖,强制指定flink-test-utils-junit版本,否则编译会报错-->
<dependency>
<artifactId>flink-test-utils-junit</artifactId>
<groupId>org.apache.flink</groupId>
<version>${parent.version}</version>
<scope>test</scope>
</dependency>
4.3.3 编译源码和推送到远程仓库
# 只编译 flink-table-planner
$ mvn clean install -pl flink-table/flink-table-planner -am -Dscala-2.12 -DskipTests -Dfast -Drat.skip=true -Dcheckstyle.skip=true -Pskip-webui-build
运行成功后查看本地maven仓库,已经产生flink-table-planner_2.12-1.14.4.1.jar
$ ll ~/.m2/repository/org/apache/flink/flink-table-planner_2.12/1.14.4.1
-rw-r--r-- 1 baisong staff 11514580 11 24 18:27 flink-table-planner_2.12-1.14.4.1-tests.jar
-rw-r--r-- 1 baisong staff 35776592 11 24 18:28 flink-table-planner_2.12-1.14.4.1.jar
-rw-r--r-- 1 baisong staff 40 11 23 17:13 flink-table-planner_2.12-1.14.4.1.jar.sha1
-rw-r--r-- 1 baisong staff 15666 11 24 18:28 flink-table-planner_2.12-1.14.4.1.pom
-rw-r--r-- 1 baisong staff 40 11 23 17:12 flink-table-planner_2.12-1.14.4.1.pom.sha1
如果要推送到Maven仓库,修改pom.xml 增加仓库地址。
<distributionManagement>
<repository>
<id>releases</id>
<url>http://xxx.xxx-inc.com/repository/maven-releases</url>
</repository>
<snapshotRepository>
<id>snapshots</id>
<url>http://xxx.xxx-inc.com/repository/maven-snapshots</url>
</snapshotRepository>
</distributionManagement>
# 进入flink-table-planner模块
$ cd flink-table/flink-table-planner
# 推送到到远程仓库
$ mvn clean deploy -Dscala-2.12 -DskipTests -Dfast -Drat.skip=true -Dcheckstyle.skip=true -Pskip-webui-build -T 1C
4.4 修改Flink依赖版本并测试Lookup Join
修改pom.xml中依赖的flink-table-planner的版本为1.14.4.1。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.14.4.1</version>
</dependency>
执行测试用例得到Lookup Join血缘结果如下,已经包含维表dim_mysql_company的字段血缘关系。
| sourceTable | sourceColumn | targetTable | targetColumn |
|---|---|---|---|
| ods_mysql_users | id | dwd_hudi_users | id |
| dim_mysql_company | company_name | dwd_hudi_users | name |
| ods_mysql_users | name | dwd_hudi_users | name |
| dim_mysql_company | company_name | dwd_hudi_users | company_name |
| ods_mysql_users | birthday | dwd_hudi_users | birthday |
| ods_mysql_users | ts | dwd_hudi_users | ts |
| ods_mysql_users | birthday | dwd_hudi_users | partition |
4.5 动态编辑Java字节码增加getColumnOrigins方法
Javassist是可以动态编辑Java字节码的类库,它可以在Java程序运行时定义一个新的类并加载到JVM中,还可以在JVM加载时修改一个类文件。
因此,本文通过Javassist技术来动态给RelMdColumnOrigins类增加getColumnOrigins(Snapshot rel,RelMetadataQuery mq, int iOutputColumn)方法。
核心代码如下:
/**
* Dynamic add getColumnOrigins method to class RelMdColumnOrigins by javassist:
*
* public Set<RelColumnOrigin> getColumnOrigins(Snapshot rel,RelMetadataQuery mq, int iOutputColumn) {
* return mq.getColumnOrigins(rel.getInput(), iOutputColumn);
* }
*/
static {
try {
ClassPool classPool = ClassPool.getDefault();
CtClass ctClass = classPool.getCtClass("org.apache.calcite.rel.metadata.RelMdColumnOrigins");
CtClass[] parameters = new CtClass[]{classPool.get(Snapshot.class.getName())
, classPool.get(RelMetadataQuery.class.getName())
, CtClass.intType
};
// add method
CtMethod ctMethod = new CtMethod(classPool.get("java.util.Set"), "getColumnOrigins", parameters, ctClass);
ctMethod.setModifiers(Modifier.PUBLIC);
ctMethod.setBody("{return $2.getColumnOrigins($1.getInput(), $3);}");
ctClass.addMethod(ctMethod);
// load the class
ctClass.toClass();
} catch (Exception e) {
throw new TableException("Dynamic add getColumnOrigins() method exception.", e);
}
}
注1: 也可把RelMdColumnOrigins类及package拷贝到项目中,然后手动增加getColumnOrigins方法。但是此方法兼容性不够友好,后续calcite源码进行迭代后血缘代码要跟随calcite一起修正。
五、Flink其他高级语法支持
在1.0.0版本发布后,经过读者@SinyoWong实践测试发现还不支持Table Functions(UDTF)和Watermark语法的字段血缘解析,于是开始进一步完善代码。
详见issue: https://github.com/HamaWhiteGG/flink-sql-lineage/issues/3,在此表示感谢。
5.1 改变Calcite源码修改方式
由于下面步骤还需要修改Calcite源码中的RelMdColumnOrigins类,第四章节介绍的两种修改Calcite源码重新编译和动态编辑字节码方法都太过于笨重,
因此直接在本项目下新建org.apache.calcite.rel.metadata.RelMdColumnOrigins类,把Calcite的源码拷贝过来后进行修改。
记得把支持Lookup Join添加的getColumnOrigins(Snapshot rel,RelMetadataQuery mq, int iOutputColumn)增加进来。
/**
* Support the field blood relationship of lookup join
*/
public Set<RelColumnOrigin> getColumnOrigins(Snapshot rel,
RelMetadataQuery mq, int iOutputColumn) {
return mq.getColumnOrigins(rel.getInput(), iOutputColumn);
}
5.2 支持Table Functions
5.2.1 新建UDTF
- 自定义Table Function 类
@FunctionHint(output = @DataTypeHint("ROW<word STRING, length INT>"))
public class MySplitFunction extends TableFunction<Row> {
public void eval(String str) {
for (String s : str.split(" ")) {
// use collect(...) to emit a row
collect(Row.of(s, s.length()));
}
}
}
- 新建my_split_udtf函数
DROP FUNCTION IF EXISTS my_split_udtf;
CREATE FUNCTION IF NOT EXISTS my_split_udtf
AS 'com.dtwave.flink.lineage.tablefuncion.MySplitFunction';
5.2.2 测试UDTF SQL
INSERT INTO
dwd_hudi_users
SELECT
length,
name,
word as company_name,
birthday,
ts,
DATE_FORMAT(birthday, 'yyyyMMdd')
FROM
ods_mysql_users,
LATERAL TABLE (my_split_udtf (name))
5.2.3 分析Optimized Logical Plan
生成Optimized Logical Plan的如下:
FlinkLogicalCalc(select=[length, name, word AS company_name, birthday, ts, DATE_FORMAT(birthday, _UTF-16LE'yyyyMMdd') AS EXPR$5])
FlinkLogicalCorrelate(correlation=[$cor0], joinType=[inner], requiredColumns=[{1}])
FlinkLogicalCalc(select=[id, name, birthday, ts, PROCTIME() AS proc_time])
FlinkLogicalTableSourceScan(table=[[hive, flink_demo, ods_mysql_users]], fields=[id, name, birthday, ts])
FlinkLogicalTableFunctionScan(invocation=[my_split_udtf($cor0.name)], rowType=[RecordType:peek_no_expand(VARCHAR(2147483647) word, INTEGER length)])
可以看到中间生成 FlinkLogicalCorrelate, 源码调试过程中的变量信息如下图:
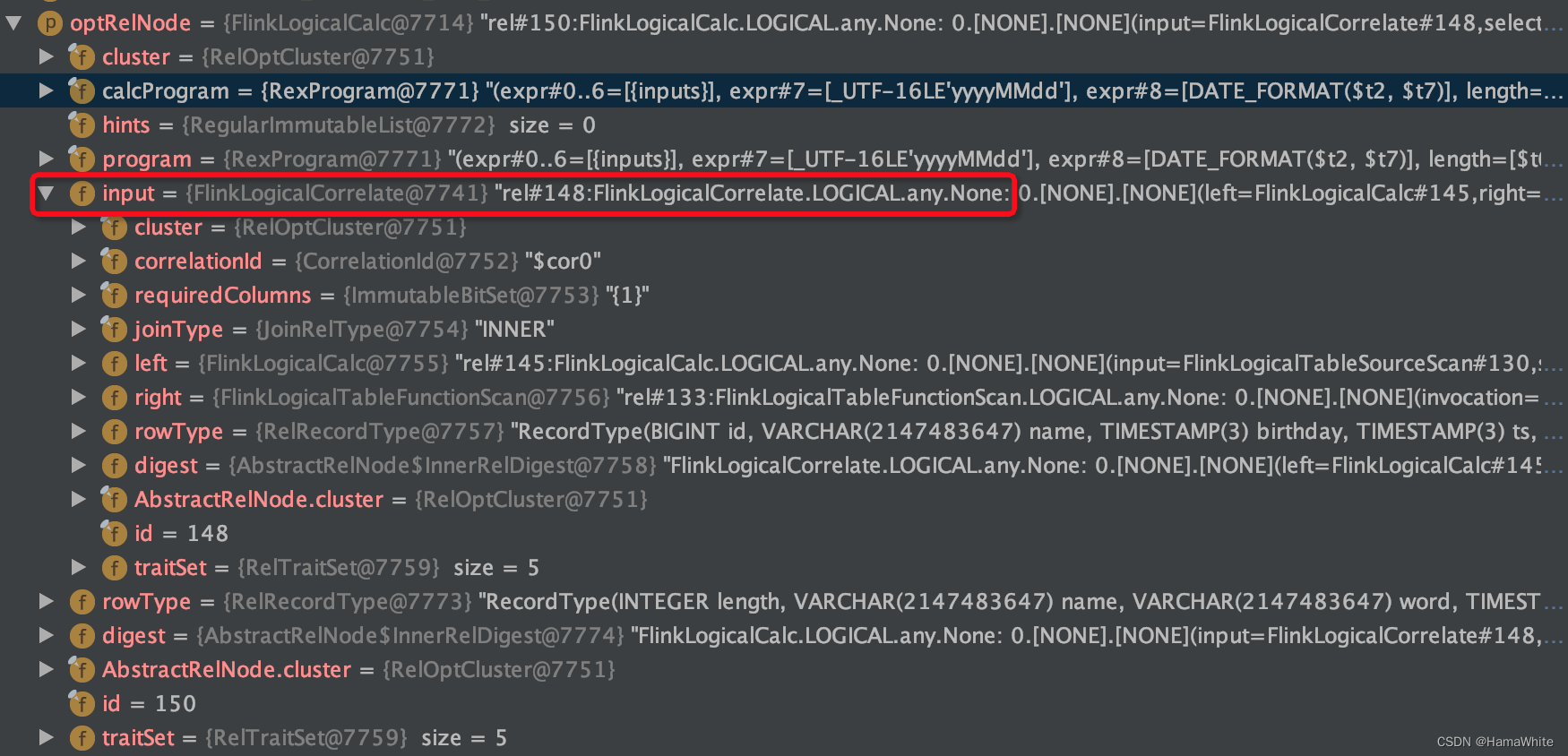
分析继承关系:
# FlinkLogicalCorrelate
FlinkLogicalCorrelate -> Correlate -> BiRel -> AbstractRelNode -> RelNode
# Join(Join和Correlate有类似,此处也展示下)
Join -> BiRel -> AbstractRelNode -> RelNode
# FlinkLogicalTableSourceScan
FlinkLogicalTableSourceScan -> TableScan ->AbstractRelNode -> RelNode
# FlinkLogicalTableFunctionScan
FlinkLogicalTableFunctionScan -> TableFunctionScan ->AbstractRelNode -> RelNode
5.2.4 新增getColumnOrigins(Correlate rel, RelMetadataQuery mq, int iOutputColumn)方法
在org.apache.calcite.rel.metadata.RelMdColumnOrigins类的getColumnOrigins()的方法中,发现没有Correlate作为参数的方法,因此解析不出UDTF的字段血缘关系。
由于Correlate和Join都继承自BiRel,即有left和right两个RelNode。因此在书写Correlate的解析时可参考下已有的getColumnOrigins(Join rel, RelMetadataQuery mq,int iOutputColumn)方法。
LATERAL TABLE (my_split_udtf (name))生成的临时表两个字段word和length,本质是来自dwd_hudi_users表的name字段。
因此针对右边的LATERAL TABLE获取UDTF中的字段,然后再根据字段名获取左表信息和索引,最终是获取的是左表的字段血缘关系。
核心代码如下:
/**
* Support the field blood relationship of table function
*/
public Set<RelColumnOrigin> getColumnOrigins(Correlate rel, RelMetadataQuery mq, int iOutputColumn) {
List<RelDataTypeField> leftFieldList = rel.getLeft().getRowType().getFieldList();
int nLeftColumns = leftFieldList.size();
Set<RelColumnOrigin> set;
if (iOutputColumn < nLeftColumns) {
set = mq.getColumnOrigins(rel.getLeft(), iOutputColumn);
} else {
// get the field name of the left table configured in the Table Function on the right
TableFunctionScan tableFunctionScan = (TableFunctionScan) rel.getRight();
RexCall rexCall = (RexCall) tableFunctionScan.getCall();
// support only one field in table function
RexFieldAccess rexFieldAccess = (RexFieldAccess) rexCall.operands.get(0);
String fieldName = rexFieldAccess.getField().getName();
int leftFieldIndex = 0;
for (int i = 0; i < nLeftColumns; i++) {
if (leftFieldList.get(i).getName().equalsIgnoreCase(fieldName)) {
leftFieldIndex = i;
break;
}
}
/**
* Get the fields from the left table, don't go to
* getColumnOrigins(TableFunctionScan rel,RelMetadataQuery mq, int iOutputColumn),
* otherwise the return is null, and the UDTF field origin cannot be parsed
*/
set = mq.getColumnOrigins(rel.getLeft(), leftFieldIndex);
}
return set;
}
注: 在Logical Plan中可以看到right RelNode是FlinkLogicalTableFunctionScan类型,继承自TableFunctionScan,但在已有getColumnOrigins(TableFunctionScan rel,RelMetadataQuery mq, int iOutputColumn) 获取的结果是null。
刚开始也尝试修改此方法,但一直无法获取的左表的信息。因此改为在getColumnOrigins(Correlate rel, RelMetadataQuery mq, int iOutputColumn) 获取右变LATERAL TABLE血缘的代码。
5.2.5 测试结果
| sourceTable | sourceColumn | targetTable | targetColumn |
|---|---|---|---|
| ods_mysql_users | name | dwd_hudi_users | id |
| ods_mysql_users | name | dwd_hudi_users | name |
| ods_mysql_users | name | dwd_hudi_users | company_name |
| ods_mysql_users | birthday | dwd_hudi_users | birthday |
| ods_mysql_users | ts | dwd_hudi_users | ts |
| ods_mysql_users | birthday | dwd_hudi_users | partition |
注: SQL中的word和length本质是来自dwd_hudi_users表的name字段,因此字段血缘关系展示的是name。
即 ods_mysql_users.name -> length -> dwd_hudi_users.id 和 ods_mysql_users.name -> word -> dwd_hudi_users.company_name
5.3 支持Watermark
5.3.1 新建ods_mysql_users_watermark
DROP TABLE IF EXISTS ods_mysql_users_watermark;
CREATE TABLE ods_mysql_users_watermark(
id BIGINT,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
proc_time as proctime(),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.90.xxx',
'port' = '3306',
'username' = 'root',
'password' = 'xxx',
'server-time-zone' = 'Asia/Shanghai',
'database-name' = 'demo',
'table-name' = 'users'
);
5.3.2 测试Watermark SQL
INSERT INTO
dwd_hudi_users
SELECT
id,
name,
name as company_name,
birthday,
ts,
DATE_FORMAT(birthday, 'yyyyMMdd')
FROM
ods_mysql_users_watermark
5.3.3 分析Optimized Logical Plan
生成Optimized Logical Plan的如下:
FlinkLogicalCalc(select=[id, name, name AS company_name, birthday, ts, DATE_FORMAT(birthday, _UTF-16LE'yyyyMMdd') AS EXPR$5])
FlinkLogicalWatermarkAssigner(rowtime=[ts], watermark=[-($3, 5000:INTERVAL SECOND)])
FlinkLogicalTableSourceScan(table=[[hive, flink_demo, ods_mysql_users_watermark]], fields=[id, name, birthday, ts])
可以看到中间生成 FlinkLogicalWatermarkAssigner, 分析继承关系:
FlinkLogicalWatermarkAssigner -> WatermarkAssigner -> SingleRel -> AbstractRelNode -> RelNode
因此下面增加SingleRel作为参数的getColumnOrigins方法。
5.3.4 新增getColumnOrigins(SingleRel rel, RelMetadataQuery mq, int iOutputColumn)方法
/**
* Support the field blood relationship of watermark
*/
public Set<RelColumnOrigin> getColumnOrigins(SingleRel rel,
RelMetadataQuery mq, int iOutputColumn) {
return mq.getColumnOrigins(rel.getInput(), iOutputColumn);
}
5.3.5 测试结果
| sourceTable | sourceColumn | targetTable | targetColumn |
|---|---|---|---|
| ods_mysql_users_watermark | id | dwd_hudi_users | id |
| ods_mysql_users_watermark | name | dwd_hudi_users | name |
| ods_mysql_users_watermark | name | dwd_hudi_users | company_name |
| ods_mysql_users_watermark | birthday | dwd_hudi_users | birthday |
| ods_mysql_users_watermark | ts | dwd_hudi_users | ts |
| ods_mysql_users_watermark | birthday | dwd_hudi_users | partition |
六、参考文献
- How to screw SQL to anything with Apache Calcite
- 使用build.gradle.kts发布到mavenLocal
- Flink SQL LookupJoin终极解决方案及Flink Rule入门
- 基于Calcite解析Flink SQL列级数据血缘
- 干货|详解FlinkSQL实现原理
- SQL解析框架: Calcite
- Flink1.14-table functions doc
最后
以上就是虚幻大树最近收集整理的关于FlinkSQL字段血缘解决方案及源码的全部内容,更多相关FlinkSQL字段血缘解决方案及源码内容请搜索靠谱客的其他文章。








发表评论 取消回复