*【正确】 题目1:*
下列关于hadoop中partition描述正确的是?
- A、reduce的个数小于分区个数且不等于1的时候会报错
- B、默认只有一个reduce,虽然自定义了分区,但不会使用自定义分区类
- C、分区个数小于reduce的个数时,会有空文件出现
- D、自定义分区的分区号默认从0开始
【参考答案】: ABCD
(1)如果reduceTask的数量 > getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
(2)如果reduceTask的数量 < getpartition的结果数,则由一部分分区数据无处安放,会exception
(3)如果reduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这个reduceTask,最终也就只会产生一个结果文件part-r-0000
【您的答案】: ABCD
*【正确】 题目2:*
Hdfs dfs中的-get和-put命令操作对象是 [单选题] *
- A、 只是文件
- B、只是目录
- C、目录和文件都是
- D、目录和文件都不是
【参考答案】: C
【您的答案】: C
*【正确】 题目3:*
关于HDFS的文件写入,正确的是 [单选题] *
- A、支持多用户对同一文件的写操作
- B、用户可以在文件任意位置进行修改
- C、默认将文件块复制成三份存放
- D、复制的文件块默认都存在同一机架上
【参考答案】: C
【您的答案】: C
*【正确】 题目4:*
HDFS是基于流数据模式访问和处理超大文件的需求而开发的,具有高容错、高可靠性、高可扩展性、高吞吐率等特征,适合的读写任务是 [单选题]
- A、一次写入,少次读
- B、多次写入,少次读
- C、多次写入,多次读
- D、一次写入,多次读
【参考答案】: D
【您的答案】: D
*【正确】 题目5:*
下面哪个程序负责 HDFS 数据存储? [单选题]
- A、NameNode
- B、Jobtracker
- C、Datanode
- D、secondaryNameNode
【参考答案】: C
【您的答案】: C
*【正确】 题目6:*
NameNode故障后,采用什么方法恢复数据?[单选题]
- A、将SecondaryNameNode中数据拷贝到NameNode存储数据的目录
- B、使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
- C、AB都可以
- D、AB都不可以
【参考答案】: C
【您的答案】: C
*【正确】 题目7:*
在mr计算过程中如何决定partition的个数?[单选题]
- A、maptask的个数
- B、reducetask的个数
- C、系统默认个数
- D、只有一个
【参考答案】: B
【您的答案】: B
*【正确】 题目8:*
配置机架感知的下面哪项正确:[多选]
- A、如果一个机架出问题,不会影响数据读写
- B、写入数据的时候会写到不同机架的 DataNode 中
- C、MapReduce 会根据机架获取离自己比较近的网络数据
- D、以上都不对
【参考答案】: ABC
【您的答案】: ABC
*【正确】 题目9:*
HDFS无法高效存储大量小文件,想让它能处理好小文件,比较可行的改进策略错误的是 [单选题]
- A、将多个小文件打包成一个HAR文件。
- B、使用CombineTextInputFormat 替代默认的策略。
- C、开启uber模式,实现jvm重用。
- D、提升网络带宽,加快小文件的传输。
【参考答案】: D
【您的答案】: D
*【正确】 题目10:*
Namenode在启动时自动进入安全模式,在安全模式阶段,说法错误的是 [单选题]
- A、安全模式目的是在系统启动时检查各个DataNode上数据块的有效性
- B、 根据策略对数据块进行必要的复制或删除
- C、当数据块最小百分比数满足的最小副本数条件时,会自动退出安全模式
- D、文件系统允许有修改
【参考答案】: D
【您的答案】: D
*【正确】 题目11:*
下面对MapReduce的优点描述不正确的是?
- A、MapReduce易于编程、MapReduce高容错性
- B、MapReduce有良好的扩展性
- C、MapReduce擅长DAG(有向图)计算
- D、MapReduce适合PB级以上海量数据离线处理
【参考答案】: C
【您的答案】: C
*【正确】 题目12:*
下面对MapReduce的缺点描述不正确的是?
- A、MapReduce不擅长实时计算
- B、MapReduce不擅长流失计算
- C、MapReduce不擅长DAG(有向图)计算
- D、MapReduce不适合PB级以上海量数据离线处理
【参考答案】: D
【您的答案】: D
*【正确】 题目13:*
一个完整的MapReduce程序在分布式运行时有哪几类实例进程?
- A、MrAppMaster:负责整个程序的过程调度及状态协调。
- B、MapTask:负责Map阶段的整个数据处理流程。
- C、ReduceTask:负责Reduce阶段的整 个数据处理流程。
- D、ABC都是
【参考答案】: D
【您的答案】: D
*【正确】 题目14:*
切片原理
FileInputFormat切片机制描述不正确的是?
- A、简单地按照文件的内容长度进行切片
- B、切片大小,默认等于Block大小
- C、切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
- D、maxsize(切片最大值):参数如果调得比blockSize小,但切片不变
【参考答案】: D
【您的答案】: D
*【正确】 题目15:*
CombineTextInputFormat切片机制描述不正确的是?
- A、框架默认的CombineTextInputFormat切片机制
- B、CombineTextInputFormat用于小文件过多的场景
- C、它可以将多个小文件从逻辑上规划到一个切片中
- D、多个小文件可以交给一个MapTask处理
【参考答案】: A
【您的答案】: A
*【正确】 题目16:*
对Shuffle中的缓冲区描述不正确的是?
- A、Shuffle中的缓冲区大小会影响到MapReduce程序的执行效率
- B、缓冲区越大,磁盘io的次数越少,执行速度就越慢。
- C、缓冲区越大,磁盘io的次数越少,执行速度就越快。
- D、缓冲区的大小可以通过参数调整,参数:io.sort.mb默认100M
【参考答案】: B
【您的答案】: B
*【正确】 题目17:*
MapTask工作机制描述不正确的是?
- A、Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
- B、Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
- C、Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作
- D、Merge阶段:在远程拷贝数据的同时,MapTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
【参考答案】: D
【您的答案】: D
*【正确】 题目18:*
ReduceTask工作机制描述不正确的是?
- A、Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
- B、Combine阶段:当所有数据处理完成后,ReduceTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
- C、Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
- D、Reduce阶段:reduce()函数将计算结果写到HDFS上。
【参考答案】: B
【您的答案】: B
*【错误】 题目19:*
对OutputFormat接口实现类描述正确的是?[多选]
- A、OutputFormat是MapReduce输出的基类
- B、所有实现MapReduce输出都实现了OutputFormat接口
- C、TextOutputFormat是默认的输出格式,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString()方法把它们转换为字符串。
- D、SequenceFileOutputF输出作为后续MapRedue任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很容易被压缩。
【参考答案】: ABCD
输出的KV可以是任意类型,因为KV泛型都是一个个的类或接口,其实现类都会重写toString,如果是默认的Text类型,则调用getBytes()方法
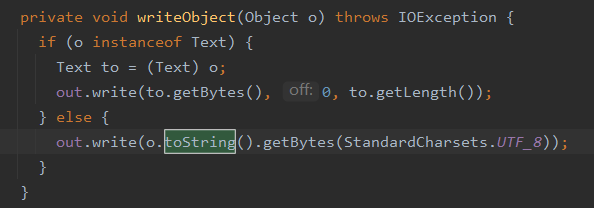
【您的答案】: ABD
*【正确】 题目20:*
HDFS小文件解决方案描述正确的是?[多选]
- A、在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS。
- B、在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并。
- C、在MapReduce处理时,可采用CombineTextInputFormat提高效率。
- D、开启jvm重用
【参考答案】: ABCD
【您的答案】: ABCD
最后
以上就是土豪荷花最近收集整理的关于hadoop阶段试题的全部内容,更多相关hadoop阶段试题内容请搜索靠谱客的其他文章。
![[转载]高通Android7.1 WIFI国家码问题](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)

![[转载]命令设置wifi国家码](https://www.shuijiaxian.com/files_image/reation/bcimg7.png)





发表评论 取消回复