Partitioner类:主要在Shuffle过程中按照Key值将中间结果分成R份,其中每份都有一个Reduce去负责。使用的时候可以通过job.setPartitionerClass()方法进行设置,
实现getPartition函数,默认的使用hashPartitioner类。
举一个简单的例子:
在Hdfs文件系统下有这样一个txt,txt的数据如下:红色方框是时间戳

时间戳的日期是从8月20到9月20。
需求:按日期把数据分成32份,比如第一份文件存的是时间戳对应日期是0820的数据,以此类推。
思路:最终结果需要32个part分别存32个日期的数据
代码如下:
首先Main里设置如下:
// 使用该类
job.setPartitionerClass(chaiwWjPartitioner.class);
// 设置reduce数为32
job.setNumReduceTasks(32);
chaiwWjPartitione类的代码:
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class chaiwWjPartitioner extends Partitioner<Text, Text>
{
public int getPartition(Text key, Text value, int numPartitions)
{
String day=key.toString();
if("20170820".equals(day)) {
return 0;
}else if("20170821".equals(day)) {
return 1;
}else if("20170822".equals(day)) {
return 2;
}else if("20170823".equals(day)) {
return 3;
}else if("20170824".equals(day)) {
return 4;
}else if("20170825".equals(day)) {
return 5;
}else if("20170826".equals(day)) {
return 6;
}else if("20170827".equals(day)) {
return 7;
}else if("20170828".equals(day)) {
return 8;
}else if("20170829".equals(day)) {
return 9;
}else if("20170830".equals(day)) {
return 10;
}else if("20170831".equals(day)) {
return 11;
}else if("20170901".equals(day)) {
return 12;
}else if("20170902".equals(day)) {
return 13;
}else if("20170903".equals(day)) {
return 14;
}else if("20170904".equals(day)) {
return 15;
}else if("20170905".equals(day)) {
return 16;
}else if("20170906".equals(day)) {
return 17;
}else if("20170907".equals(day)) {
return 18;
}else if("20170908".equals(day)) {
return 19;
}else if("20170909".equals(day)) {
return 20;
}else if("20170910".equals(day)) {
return 21;
}else if("20170911".equals(day)) {
return 22;
}else if("20170912".equals(day)) {
return 23;
}else if("20170913".equals(day)) {
return 24;
}else if("20170914".equals(day)) {
return 25;
}else if("20170915".equals(day)) {
return 26;
}else if("20170916".equals(day)) {
return 27;
}else if("20170917".equals(day)) {
return 28;
}else if("20170918".equals(day)) {
return 29;
}else if("20170919".equals(day)) {
return 30;
}else if("20170920".equals(day)) {
return 31;
}else {
return -1;
}
}
}
通过Partition代码,key值有32种返回结果,reduce任务数目又为32
结果如图:
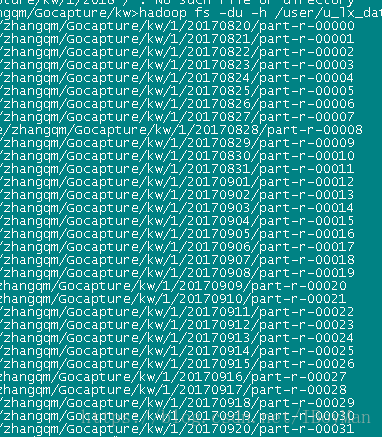
其中0820的数据在part0里,0821在part01里,以此类推。
应用场景:数据倾斜
最后
以上就是难过大山最近收集整理的关于MapReduce(MR)框架里shuffer过程中Partition的使用的全部内容,更多相关MapReduce(MR)框架里shuffer过程中Partition内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。

![[转载]命令设置wifi国家码](https://www.shuijiaxian.com/files_image/reation/bcimg7.png)






发表评论 取消回复