计算机视觉与深度学习系列博客传送门
【计算机视觉与深度学习】线性分类器(一)
【计算机视觉与深度学习】线性分类器(二)
目录
- 从线性分类器到全连接神经网络
- 全连接神经网络的权值
- 全连接神经网络与线性不可分
- 激活函数
- 网络结构设计
- Softmax与交叉熵损失
- 计算图与反向传播
从线性分类器到全连接神经网络
首先让我们回到线性分类器的定义:
f
i
(
x
,
w
i
)
=
w
i
T
x
+
b
i
,
i
=
1
,
2
,
.
.
.
,
c
f_i(bm x, bm w_i)=bm w_i^T bm x+b_i,i=1,2,...,c
fi(x,wi)=wiTx+bi,i=1,2,...,c其中
x
bm x
x代表输入的
d
d
d维图像向量,
c
c
c为类别个数,
w
i
=
[
w
i
1
w
i
2
.
.
.
w
i
d
]
T
bm w_i=begin{gathered}begin{bmatrix} w_{i1} & w_{i2} & ... & w_{id} end{bmatrix}end{gathered}^T
wi=[wi1wi2...wid]T为第
i
i
i个类别的权值向量,
b
i
b_i
bi为偏置。如果
f
i
(
x
)
>
f
j
(
x
)
f_i(bm x)>f_j(bm x)
fi(x)>fj(x),则决策输入图像
x
bm x
x属于第
i
i
i类。
全连接神经网络通过级联多个变换来实现输入到输出的映射。如两层全连接网络的定义为
f
=
W
2
max
(
0
,
W
1
x
+
b
1
)
+
b
2
bm f=bm W_2 max(bm 0,bm W_1 bm x+bm b_1)+bm b_2
f=W2max(0,W1x+b1)+b2再如三层全连接网络定义为
f
=
W
3
max
(
0
,
W
2
max
(
0
,
W
1
x
+
b
1
)
+
b
2
)
+
b
3
bm f=bm W_3 max(bm 0,bm W_2 max(bm 0,bm W_1 bm x+bm b_1)+bm b_2)+bm b_3
f=W3max(0,W2max(0,W1x+b1)+b2)+b3上式中,
max
(
0
,
⋅
)
max(0,·)
max(0,⋅)是一个激活函数(即ReLU激活函数,修正线性单元),它对线性操作后的结果进行了一次非线性操作,这个非线性操作是不可以去掉的,否则将会退化为一个线性分类器。
全连接神经网络的权值
之前在学习线性分类器的时候曾经提到过,线性分类器中的
W
bm W
W可以看作模板,模板个数由类别个数决定。而在全连接神经网络中,以两层全连接网络为例,
W
1
bm W_1
W1也可以看作模板,模板个数是人为指定的,
W
2
bm W_2
W2融合多个模板的匹配结果来实现最终的类别打分。
以CIFAR-10数据集(每张图片样本的大小为32×32×3)为例,将线性分类器的模板矩阵resize并归化后以图片的形式展示,可以得到下图的结果:

其中,horse模板出现了两个马头,这是因为在训练集中,有的图片样本中马头朝向左,有的图片样本中马头朝向右。由于线性分类器的模板个数是由类别个数决定的,所以可以分配给horse类的模板数仅有1。而在全连接神经网络中,
W
1
bm W_1
W1模板个数是人为指定的,我们可以指定一个更大的模板个数,这样每一个类别就可以分配到更多的模板数,从而达到更好的分类效果。
全连接神经网络与线性不可分
线性可分指的是至少存在一个线性分界面能把两类样本没有错误地分开。线性分类器只能解决线性可分的问题,但在实际问题中,样本数据并不都是线性可分的。在这种情况下,我们只能依赖于一些非线性操作来实现线性不可分样本数据的学习,如全连接神经网络中的激活函数就是一种非线性操作。
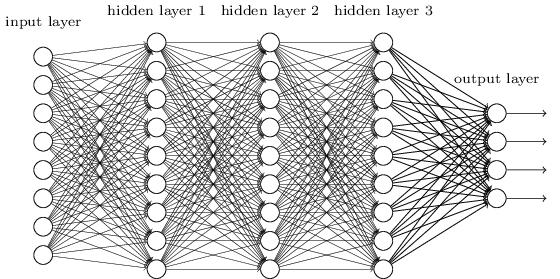
如上图所示,全连接神经网络由一个输入层 (input layer)、若干个隐藏层 (hidden layer) 以及一个输出层 (output layer) 组成。输入层的神经元数量由训练样本所决定,以CIFAR-10数据集为例,输入层的维度就是3072维(即32×32×3)。隐藏层的维度就是我们人为指定的“模板”的个数。输出层的个数由类别数来决定,以CIFAR-10数据集为例,输出层的个数就是10。除输入层外,其余所有层的所有神经元都要与前一层的所有神经元一一连接,这也是全连接神经网络名字的由来。连接两个神经元的边叫做权值,两层之间的所有权值组成权值矩阵
W
bm W
W。
N层全连接神经网络指的是除输入层外其余所有层的数量为N的全连接神经网络,如一个全连接网络有一个输入层、两个隐藏层和一个输出层,则称之为3层全连接神经网络(或者2隐层全连接神经网络)。
激活函数
以三层全连接网络
f
=
W
3
max
(
0
,
W
2
max
(
0
,
W
1
x
+
b
1
)
+
b
2
)
+
b
3
bm f=bm W_3 max(bm 0,bm W_2 max(bm 0,bm W_1 bm x+bm b_1)+bm b_2)+bm b_3
f=W3max(0,W2max(0,W1x+b1)+b2)+b3为例,若去掉激活函数
max
(
0
,
⋅
)
max(0,·)
max(0,⋅),
f
bm f
f的表达式变为
f
=
W
3
(
W
2
(
W
1
x
+
b
1
)
+
b
2
)
+
b
3
bm f=bm W_3(bm W_2(bm W_1 bm x+bm b_1)+bm b_2)+bm b_3
f=W3(W2(W1x+b1)+b2)+b3整理得
f
=
W
3
W
2
W
1
x
+
(
W
3
W
2
b
1
+
W
3
b
2
+
b
3
)
bm f=bm W_3bm W_2bm W_1 bm x+(bm W_3 bm W_2bm b_1+bm W_3bm b_2+bm b_3)
f=W3W2W1x+(W3W2b1+W3b2+b3)令
W
3
W
2
W
1
=
W
′
,
W
3
W
2
b
1
+
W
3
b
2
+
b
3
=
b
′
bm W_3bm W_2bm W_1=bm W',bm W_3 bm W_2bm b_1+bm W_3bm b_2+bm b_3=bm b'
W3W2W1=W′,W3W2b1+W3b2+b3=b′,有
f
=
W
′
x
+
b
′
bm f=bm W' bm x+bm b'
f=W′x+b′这也就解释了前面所提到的,若去掉非线性操作(激活函数),全连接神经网络将会退化为一个线性分类器。
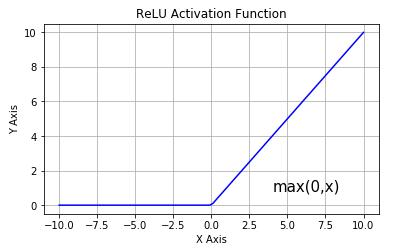
max
(
0
,
x
)
max(0,x)
max(0,x)是一种很常用的激活函数,叫做ReLU函数(修正线性单元,Rectified Linear Unit),函数图像如下所示:
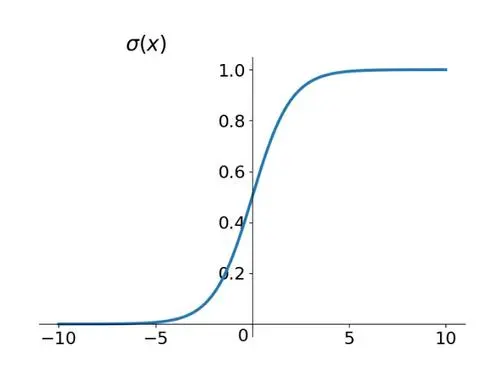
除此之外,还有一些常用的激活函数,如Sigmoid函数
1
1
+
e
−
x
frac{1}{1+e^{-x}}
1+e−x1
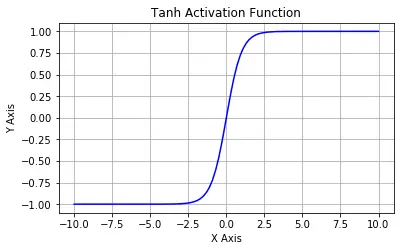
tanh函数
e
x
−
e
−
x
e
x
+
e
−
x
frac{e^x-e^{-x}}{e^x+e^{-x}}
ex+e−xex−e−x
Leaky ReLU函数
max
(
α
x
,
x
)
max(alpha x,x)
max(αx,x) 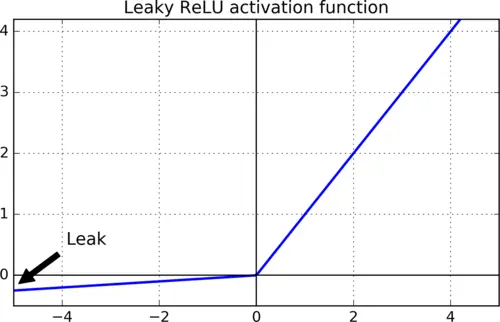
等。Sigmoid函数可以将输出结果转化到
(
0
,
1
)
(0,1)
(0,1)区间内,输出值大于0且不中心对称。tanh函数可以将输出结果转化到
(
−
1
,
1
)
(-1,1)
(−1,1)区间内,输出值是中心对称的。tanh函数的输出值有正有负,这是它与Sigmoid函数的最大区别。ReLU函数将小于0的部分直接置为0,大于0的部分保持原输出结果。然而,ReLU函数在训练过程中存在神经元“死亡”问题,Leaky ReLU函数是在ReLU函数的基础上加了一个“泄露”,在小于0的部分并不直接置0,而是给定一个很小的斜率,从而解决了这一问题。
网络结构设计
在设计神经网络的时候,我们需要考虑如下两个问题:
- 需要设计多少个隐藏层?
- 每个隐藏层需要设计多少个神经元?
事实上,这两个问题并没有统一的答案。
在实际问题中,分类任务越难,我们设计的神经网络结构就应该越深、越宽。但是,对训练集分类精度最高的模型,在真实场景下识别性能未必是最好的。从宽度设计的角度来看,隐藏层神经元的个数越多,分界面就可以越复杂,在这个集合上的分类能力就越强。但是分界面过于复杂,对数据集的划分过于出色对分类问题不一定是好事,可能会造成过拟合。
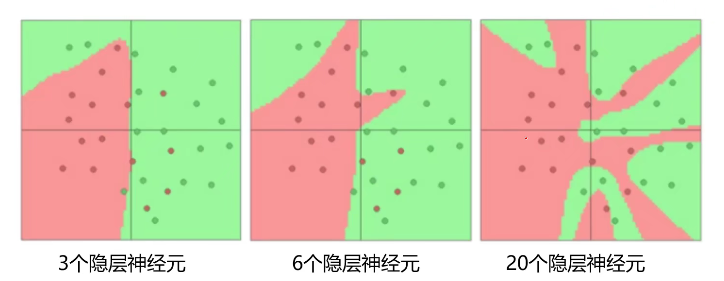
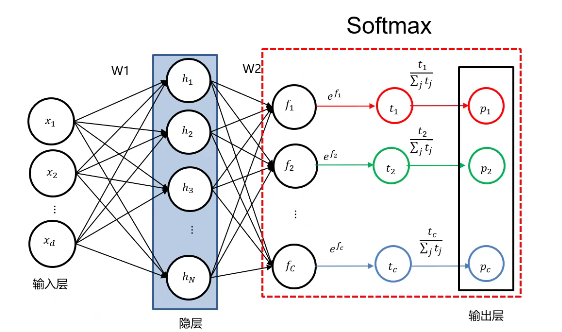
Softmax与交叉熵损失
Softmax操作是将全连接神经网络的输出取
e
e
e的幂次方,再进行归一化操作,从而得到
p
bm p
p。不难发现,
∑
i
=
1
c
p
i
=
1
sum_{i=1}^cp_i=1
∑i=1cpi=1。进行Softmax操作后,神经网络的输出带有了概率性质,
p
i
(
i
=
1
,
2
,
.
.
.
,
c
)
p_i(i=1,2,...,c)
pi(i=1,2,...,c)则代表样本属于第
i
i
i类的概率。
假设神经网络输出的预测分布
q
(
x
)
q(x)
q(x)为
[
0.21
0.01
0.78
]
begin{gathered}begin{bmatrix} 0.21 \ 0.01 \ 0.78 end{bmatrix}end{gathered}
⎣⎡0.210.010.78⎦⎤真实分布
p
(
x
)
p(x)
p(x)为
[
1
0
0
]
begin{gathered}begin{bmatrix} 1 \ 0 \ 0 end{bmatrix}end{gathered}
⎣⎡100⎦⎤那么,如何度量现在的分类器输出与真实值之间的距离?
首先介绍几个定义。
- 熵:用来度量信息量的大小。熵越大,信息量越大;熵越小,信息量越小。 H ( p ) = − ∑ x p ( x ) log p ( x ) H(p)=-sum_xp(x)log p(x) H(p)=−x∑p(x)logp(x)
- 交叉熵。 H ( p , q ) = − ∑ x p ( x ) log q ( x ) H(p,q)=-sum_xp(x)log q(x) H(p,q)=−x∑p(x)logq(x)
- 相对熵:也叫KL散度 (KL divergence),用来度量两个分布之间的不相似性 (dissimilarity)。 K L ( p ∣ ∣ q ) = − ∑ x p ( x ) log q ( x ) p ( x ) KL(p||q)=-sum_xp(x)log frac{q(x)}{p(x)} KL(p∣∣q)=−x∑p(x)logp(x)q(x)
根据上述定义,不难推导出
H
(
p
,
q
)
=
H
(
p
)
+
K
L
(
p
∣
∣
q
)
H(p,q)=H(p)+KL(p||q)
H(p,q)=H(p)+KL(p∣∣q)因此,交叉熵可以用来度量两个分布之间的距离。
对于上面给出的数据,交叉熵
H
(
p
,
q
)
=
−
∑
i
=
1
c
p
(
x
i
)
log
q
(
x
i
)
=
log
0.21
H(p,q)=-sum_{i=1}^cp(x_i)log q(x_i)=log0.21
H(p,q)=−i=1∑cp(xi)logq(xi)=log0.21上面的
p
(
x
)
p(x)
p(x)只有一项为
1
1
1,其余项均为
0
0
0,这种形式称为one-hot。当真实分布为one-hot形式时,交叉熵损失函数可以简化为
L
i
=
−
log
q
j
L_i=-log q_j
Li=−logqj其中
j
j
j为真实类别。
下面我们将交叉熵损失和多类支持向量机损失进行对比。假设我们有三个分类器,这三个分类器对于某个样本的类别分数分别为
f
1
=
[
10
−
2
3
]
bm f_1=begin{gathered}begin{bmatrix} 10 & -2 & 3 end{bmatrix}end{gathered}
f1=[10−23]
f
2
=
[
10
9
9
]
bm f_2=begin{gathered}begin{bmatrix} 10 & 9 & 9 end{bmatrix}end{gathered}
f2=[1099]
f
3
=
[
10
−
100
−
100
]
bm f_3=begin{gathered}begin{bmatrix} 10 & -100 & -100 end{bmatrix}end{gathered}
f3=[10−100−100]根据多类支持向量机损失定义
L
i
=
∑
j
≠
y
i
max
(
0
,
s
i
j
−
s
y
i
+
1
)
L_i=sum_{jneq y_i}max(0,s_{ij}-s_{y_i}+1)
Li=j=yi∑max(0,sij−syi+1)易得
L
1
多
类
支
持
向
量
机
=
L
2
多
类
支
持
向
量
机
=
L
3
多
类
支
持
向
量
机
=
0
L_{1多类支持向量机}=L_{2多类支持向量机}=L_{3多类支持向量机}=0
L1多类支持向量机=L2多类支持向量机=L3多类支持向量机=0根据交叉熵损失定义
L
i
=
−
log
(
e
s
y
i
∑
j
e
s
j
)
L_i=-log (frac{e^{s_{y_i}}}{sum_je^{s_j}})
Li=−log(∑jesjesyi)易得
L
1
交
叉
熵
=
0.0004
L_{1交叉熵}=0.0004
L1交叉熵=0.0004
L
2
交
叉
熵
=
0.2395
L_{2交叉熵}=0.2395
L2交叉熵=0.2395
L
3
交
叉
熵
=
1.5
×
1
0
−
48
L_{3交叉熵}=1.5times10^{-48}
L3交叉熵=1.5×10−48这样,我们就可以根据交叉熵损失决策出最好的模型是分类器3。
计算图与反向传播
任意复杂的函数都可以用计算图的形式表示。在整个计算图中,每个门单元都会得到一些输入,然后进行下面两个计算:
- 这个门的输出;
- 其输出关于输入的局部梯度。
利用链式法则,门单元应该将回传的梯度乘以对其输入的局部梯度,从而得到整个网络的输出对该门单元每个输入值的梯度。
以函数
f
(
w
,
x
)
=
1
1
+
e
−
(
w
0
x
0
+
w
1
x
1
+
w
2
)
f(w,x)=frac{1}{1+e^{-(w_0x_0+w_1x_1+w_2)}}
f(w,x)=1+e−(w0x0+w1x1+w2)1为例,其计算图如下:
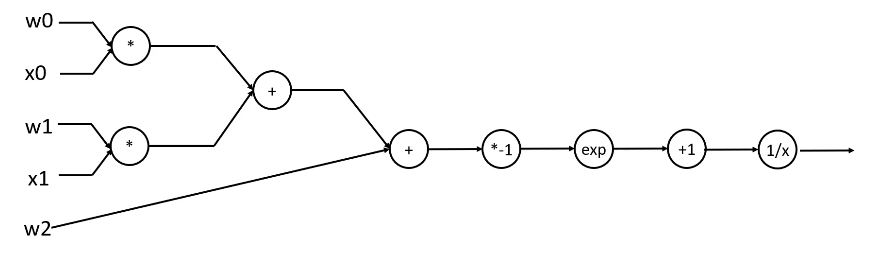
给定一组输入,根据计算图,我们可以很轻松地计算出函数的输出:
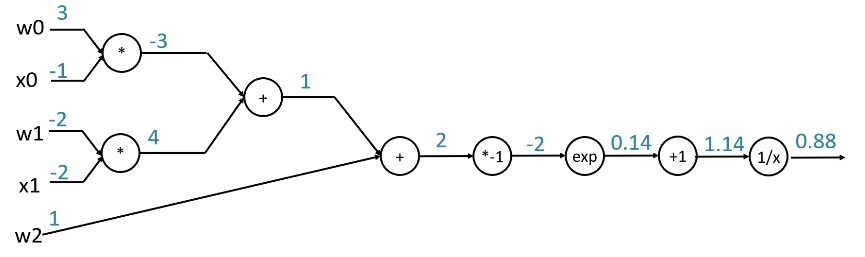
以下图红框处为例,计算该处的梯度。
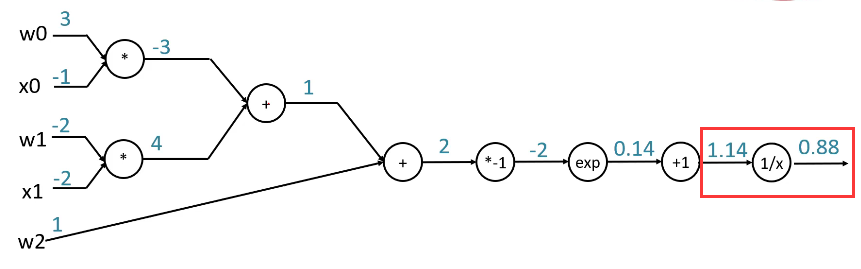
根据链式法则,该处的梯度等于其上游梯度与局部梯度之积。易知上游梯度为
1
1
1。根据函数的求导法则
f
(
x
)
=
1
x
f(x)=frac{1}{x}
f(x)=x1
d
f
d
x
=
−
1
x
2
frac{mathrm{d}f}{mathrm{d}x}=-frac{1}{x^2}
dxdf=−x21可以计算出局部梯度为
−
1
1.1
4
2
-frac{1}{1.14^2}
−1.1421。则该处的梯度等于
1
×
(
−
1
1.1
4
2
)
=
−
0.77
1times (-frac{1}{1.14^2})=-0.77
1×(−1.1421)=−0.77再继续向前传播同理,此处不再赘述。
最后
以上就是欢呼日记本最近收集整理的关于【计算机视觉与深度学习】全连接神经网络(一)从线性分类器到全连接神经网络全连接神经网络的权值全连接神经网络与线性不可分激活函数网络结构设计Softmax与交叉熵损失计算图与反向传播的全部内容,更多相关【计算机视觉与深度学习】全连接神经网络(一)从线性分类器到全连接神经网络全连接神经网络内容请搜索靠谱客的其他文章。








发表评论 取消回复