注:本系列是基于参考文献中的内容,并对其进行整理,注释形成的一系列关于深度学习的基本理论与实践的材料,基本内容与参考文献保持一致,并对这个专题起名为“利用Theano理解深度学习”系列,若文中有任何问题欢迎咨询。本文提供PDF版本,欢迎索取。
“利用Theano理解深度学习”系列分为 4 4 4个部分,这是第二部分,在第一部分中的算法主要是监督学习算法,在这部分中主要是无监督学习算法和半监督学习算法,主要包括:
- 利用Theano理解深度学习——Auto Encoder
- 利用Theano理解深度学习——Denoising Autoencoder
- 利用Theano理解深度学习——Stacked Denoising Auto Encoder
- 利用Theano理解深度学习——Restricted Boltzmann Machine
- 利用Theano理解深度学习——Deep Belief Network
一、自编码器(Autoencoders)的原理
自编码器是典型的无监督学习算法,其结构如下所示:
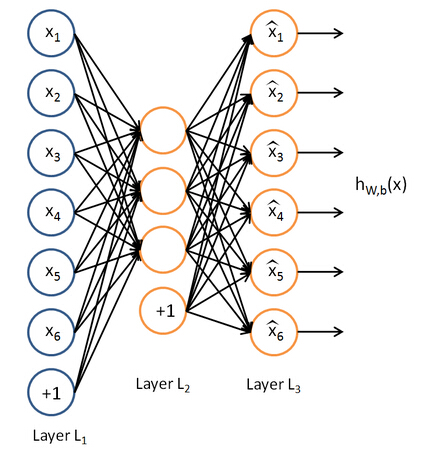
假设输入为 x ∈ [ 0 , 1 ] d mathbf{x}in left [ 0,1 right ]^d x∈[0,1]d,自编码器首先将其映射到一个隐含层,利用隐含层对其进行表示为 y ∈ [ 0 , 1 ] d ′ mathbf{y}in left [ 0,1 right ]^{{d}'} y∈[0,1]d′,这个过程称为编码(Encoder),如:
y = s ( W x + b ) mathbf{y}=sleft ( mathbf{W}mathbf{x}+mathbf{b} right ) y=s(Wx+b)
其中, s s s为一个非线性映射,如sigmoid函数。 y mathbf{y} y称为隐含的变量,该隐含的变量又会通过一个映射去重构 z mathbf{z} z,这里的 z mathbf{z} z与 x mathbf{x} x具有相同的结构,这个过程称为解码(Decoder)。其中映射的过程为:
z = s ( W ′ y + b ′ ) mathbf{z}=sleft ( mathbf{W}'mathbf{y}+mathbf{b}' right ) z=s(W′y+b′)
z
mathbf{z}
z可以看成是给定
y
mathbf{y}
y的条件下对
x
mathbf{x}
x的一个预测,重构部分的权重矩阵
W
′
mathbf{W}'
W′可以被看成是第一个映射的逆过程,即
W
′
=
W
T
mathbf{W}'=mathbf{W}^T
W′=WT。这被称为tied weights。模型的参数(即
W
mathbf{W}
W,
b
mathbf{b}
b,
b
′
mathbf{b}'
b′,如果不用tied weights,同样是
W
′
mathbf{W}'
W′)将被优化,以使得平均重构误差最小。
二、Autoencoder的损失函数
定义重构误差的方法有很多种,如传统的均方误差(squared error) L ( x z ) = ∥ x − z ∥ 2 Lleft ( mathbf{x}mathbf{z} right )=left | mathbf{x}-mathbf{z} right |^2 L(xz)=∥x−z∥2,如果输入被转换成位向量或者概率的向量,可以使用交叉熵(cross-entropy)的度量方法:
L H ( x , z ) = − ∑ k = 1 d [ x k l o g z k + ( 1 − x k ) l o g ( 1 − z k ) ] L_Hleft ( mathbf{x},mathbf{z} right )=-sum_{k=1}^{d}left [ mathbf{x}_klogmathbf{z}_k+left ( 1-mathbf{x}_k right )logleft ( 1-mathbf{z}_k right ) right ] LH(x,z)=−k=1∑d[xklogzk+(1−xk)log(1−zk)]
定义重构误差的方法取决于对输入的合适的假设。我们希望的是 y mathbf{y} y是一种分布式的表示,可以捕获在数据中的主要变化因素的坐标。这与映射到主要成分的方式相似,可以捕获数据中变化的主要因素。实际上,如果对于存在一个线性的隐含层,并且使用均方误差作为标准训练网络,则第 k k k个隐含层节点学到的是将输入映射到前 k k k个主要成分张成的空间。如果隐含层是非线性的,则auto-encoder与PCA不同,具有捕获输入分布中的多模态的能力。这种与PCA不一样的性质对于我们构建层叠式多个编码器(stacking multiply encoders)是非常重要的,如构建一个深度自编码器。
因为 y mathbf{y} y是被看成是 x mathbf{x} x的有损压缩,不可能对所有的 x mathbf{x} x都具有较好的压缩效果。优化的过程使得这样的 y mathbf{y} y对所有的训练样本来说是较好的,同时,希望对其他的输入同样也具有较好的压缩效果,但是不是对任意的输入都适用。在Auto Encoder算法中有如下的结论:
当测试样本与输入样本具有同样的分布时,auto-encoder具有较小的重构误差,但是对于从输入空间中随机选取的样本,通常具有较大的重构误差。
三、利用Theano实现Autoencoder
在Autoencoder的构建中主要包括以下几个部分:
3.1、导入数据集
在导入数据集中,主要使用的是在logistic_sgd中定义的load_data函数,其具体的导入形式如下所示:
#1、导入数据集#
datasets = load_data(dataset)#导入数据集,函数在logistic_sgd中定义
train_set_x, train_set_y = datasets[0]#得到训练数据
3.2、构建模型
构建模型的代码如下所示:
#2、构建模型
rng = numpy.random.RandomState(123)
theano_rng = RandomStreams(rng.randint(2 ** 30))
#初始化模型的参数
da = auto_encoder(
numpy_rng=rng,
theano_rng=theano_rng,
input=x,
n_visible=28 * 28,
n_hidden=500
)
#定义模型的损失函数和更新规则
cost, updates = da.get_cost_updates(
corruption_level=0.,
learning_rate=learning_rate
)
#定义训练函数
train_da = theano.function(
[index],
cost,
updates=updates,
givens={
x: train_set_x[index * batch_size: (index + 1) * batch_size]
}
)
start_time = timeit.default_timer()#定义训练的初始时间
3.2.1、类的定义
首先是对模型中的参数进行初始化,这部分主要是一个auto_encoder的类,类的定义如下所示:
class auto_encoder(object):
def __init__(
self,
numpy_rng,
theano_rng=None,
input=None,
n_visible=784,#输入层节点的个数
n_hidden=500,#隐含层节点的个数
W=None,
bhid=None,
bvis=None
):
"""
:type numpy_rng: numpy.random.RandomState
:param numpy_rng: 用于随机产生权重和偏置
:type theano_rng: theano.tensor.shared_randomstreams.RandomStreams
:param theano_rng: Theano的随机数生成
:type input: theano.tensor.TensorType
:param input: 描述输入的参数,None表示的是单独的autoencoder
:type n_visible: int
:param n_visible: 输入层节点的个数
:type n_hidden: int
:param n_hidden: 隐含层节点的个数
:type W: theano.tensor.TensorType
:param W: 指示权重的参数,如果是None表示的是单独的Autoencoder
:type bhid: theano.tensor.TensorType
:param bhid: 指示隐含层偏置的参数,如果是None表示的是单独的Autoencoder
:type bvis: theano.tensor.TensorType
:param bvis: 指示输出层偏置的参数,如果是None表示的是单独的Autoencoder
"""
self.n_visible = n_visible#设置输入层的节点个数
self.n_hidden = n_hidden#设置隐含层的节点个数
if not theano_rng:
theano_rng = RandomStreams(numpy_rng.randint(2 ** 30))
if not W:#初始化权重
initial_W = numpy.asarray(
numpy_rng.uniform(
low=-4 * numpy.sqrt(6. / (n_hidden + n_visible)),#下界
high=4 * numpy.sqrt(6. / (n_hidden + n_visible)),#上界
size=(n_visible, n_hidden)
),
dtype=theano.config.floatX
)
W = theano.shared(value=initial_W, name='W', borrow=True)
if not bvis:#初始化偏置
bvis = theano.shared(
value=numpy.zeros(#初始化为0
n_visible,
dtype=theano.config.floatX
),
borrow=True
)
if not bhid:#初始化偏置
bhid = theano.shared(#初始化为0
value=numpy.zeros(
n_hidden,
dtype=theano.config.floatX
),
name='b',
borrow=True
)
self.W = W#输入层到隐含层的权重
self.b = bhid#输入层到隐含层的偏置
self.b_prime = bvis#隐含层到输出层的偏置
self.W_prime = self.W.T#隐含层到输出层的偏置
self.theano_rng = theano_rng
#将输入作为参数传入,可以方便后面堆叠成深层的网络
if input is None:
self.x = T.dmatrix(name='input')
else:
self.x = input
self.params = [self.W, self.b, self.b_prime]#声明参数
def get_corrupted_input(self, input, corruption_level):
return self.theano_rng.binomial(size=input.shape, n=1,
p=1 - corruption_level,
dtype=theano.config.floatX) * input
def get_hidden_values(self, input):#计算隐含层的输出
return T.nnet.sigmoid(T.dot(input, self.W) + self.b)
def get_reconstructed_input(self, hidden):#计算输出层的输出
return T.nnet.sigmoid(T.dot(hidden, self.W_prime) + self.b_prime)
def get_cost_updates(self, corruption_level, learning_rate):#计算损失函数和更新
tilde_x = self.get_corrupted_input(self.x, corruption_level)
y = self.get_hidden_values(tilde_x)
z = self.get_reconstructed_input(y)
#损失函数
L = - T.sum(self.x * T.log(z) + (1 - self.x) * T.log(1 - z), axis=1)
cost = T.mean(L)#求出平均误差
# 对需要求解的参数求其梯度
gparams = T.grad(cost, self.params)
#基于梯度下降更新每个参数
updates = [
(param, param - learning_rate * gparam)
for param, gparam in zip(self.params, gparams)
]
return (cost, updates)
在该类的定义中,首先是参数的定义方法,在权重 W mathbf{W} W的定义中,是在区间 [ l o w , h i g h ] left [ low,high right ] [low,high]上均匀取得,其中, l o w low low和 h i g h high high分别为:
l o w = − 4 × 6 n h i d d e n + n v i s i b l e low=-4times sqrt{frac{6}{n_{hidden}+n_{visible}}} low=−4×nhidden+nvisible6
h i g h = 4 × 6 n h i d d e n + n v i s i b l e high=4times sqrt{frac{6}{n_{hidden}+n_{visible}}} high=4×nhidden+nvisible6
隐含层的偏置和输出层的偏置都设置为
0
0
0向量。get_hidden_values定义了隐含层的输出,get_reconstructed_input定义了输出层的输出,在函数get_cost_updates中定义了损失函数和对每个参数求偏导及更新的规则。计算的方法与前面算法类似。
3.3、训练模型
在模型的训练阶段,是根据每一批样本,利用梯度下降对参数进行求解,程序代码如下:
#3、训练模型
# go through training epochs
for epoch in xrange(training_epochs):
# go through trainng set
c = []
for batch_index in xrange(n_train_batches):
c.append(train_da(batch_index))
print 'Training epoch %d, cost ' % epoch, numpy.mean(c)
end_time = timeit.default_timer()
training_time = (end_time - start_time)
'''
print >> sys.stderr, ('The no corruption code for file ' +
os.path.split(__file__)[1] +
' ran for %.2fm' % ((training_time) / 60.))
image = Image.fromarray(
tile_raster_images(X=da.W.get_value(borrow=True).T,
img_shape=(28, 28), tile_shape=(10, 10),
tile_spacing=(1, 1)))
image.save('filters_corruption_0.png')
os.chdir('../')
'''
其中,在循环的过程中,对模型进行训练,最终的图像输出功能被注释了。我们的目的是求出模型的权重和偏置,利用输入层到隐含层的权重和偏置,在后面的堆叠自编码其中,可以将这两层通过堆叠的方式构建成深度的网络。
四、关于隐含层节点个数的几点论述
对于隐含层节点的个数,对于非线性的自编码器,如果隐含层的节点个数大于输入层的节点个数,通过随机梯度下降法训练得到的模型通常具有更好的表示能力,这里的表示能力是指模型具有较小的分类误差。
隐含层节点个数大于输入层节点个数,这样的自编码器具有更小的分类误差。
以上的现象可以解释为:随机梯度下降法加上early stopping策略相当于对模型中的参数进行 L 2 L2 L2正则约束。对于一个隐含层节点个数大于输入层节点个数的自编码器,还有一些其他的策略可以使其在隐含层学习到输入数据的更多有用的信息,包括:
- 增加稀疏性(Sparsity):使得隐含层节点为 0 0 0或者趋近于 0 0 0。
- 在输入到重构的过程中增加随机性(Randomness)。在Restricted Boltzmann Machines和Denoising Auto-Encoders中会涉及。
若需要PDF版本,请关注我的新浪博客@赵_志_勇,私信你的邮箱地址给我。
参考文献
Deep Learning Tutorialshttp://www.deeplearning.net/tutorial/
最后
以上就是动听寒风最近收集整理的关于利用Theano理解深度学习——Auto Encoder一、自编码器(Autoencoders)的原理二、Autoencoder的损失函数三、利用Theano实现Autoencoder四、关于隐含层节点个数的几点论述参考文献的全部内容,更多相关利用Theano理解深度学习——Auto内容请搜索靠谱客的其他文章。








发表评论 取消回复