上一篇说到windows下面的Theano安装,在前面的文章中也介绍了几种常见的神经网络形式,今天就使用Theano来编写一个简单的神经网络
我把Theano形容成一个模子,这个模子提供了一些计算方法,然后我们只需要定义模子的形状和填充数据就可以了,且慢慢看:
首先我们定义初始数据集:
np.random.seed(0)
train_X, train_y = datasets.make_moons(300, noise=0.20)
train_X = train_X.astype(np.float32)
train_y = train_y.astype(np.int32)
num_example=len(train_X)train_X是随机产生的二维的数,train_y是一个随机产生一维的数(只有0和1这两个值),train_y算是一个标签,train_X和train_y的长度都是300
然后设置神经网络的基本参数:
#设置参数
nn_input_dim=2 #输入神经元个数
nn_output_dim=2 #输出神经元个数
nn_hdim=100
#梯度下降参数
epsilon=0.01 #learning rate
reg_lambda=0.01 #正则化长度也就是 2*100*2的三层神经网络,学习率是0.01,正则化因子lambda值是0.01
接下来是重点,因为在迭代过程中,w1,b1,w2,b2都是共享变量,这就需要使用Theano的share变量
w1=theano.shared(np.random.randn(nn_input_dim,nn_hdim),name="W1")
b1=theano.shared(np.zeros(nn_hdim),name="b1")
w2=theano.shared(np.random.randn(nn_hdim,nn_output_dim),name="W2")
b2=theano.shared(np.zeros(nn_output_dim),name="b2")这表明这四个参数在训练过程中是共享的
OK,数据的事情已经具备了,我们现在可以来“雕刻模子”了:
#前馈算法
X=T.matrix('X') #double类型的矩阵
y=T.lvector('y') #int64类型的向量
z1=X.dot(w1)+b1 #1
a1=T.tanh(z1) #2
z2=a1.dot(w2)+b2 #3
y_hat=T.nnet.softmax(z2) #4
#正则化项
loss_reg=1./num_example * reg_lambda/2 * (T.sum(T.square(w1))+T.sum(T.square(w2))) #5
loss=T.nnet.categorical_crossentropy(y_hat,y).mean()+loss_reg #6
#预测结果
prediction=T.argmax(y_hat,axis=1) #7首先我们定义一个输入矩阵的模子,名字叫X
然后定义一个标签数据的模子,名字叫做y
#1~#4定义的是神经网络的前馈过程
#5是正则项的计算值
#6是计算交叉熵的损失值和正则项损失值的和
这些都是我们定义的模子,一旦我们填入数据之后就能算了,那么现在问题来了,这些模子如何和python code联系起来,下面的代码可以解决:
forword_prop=theano.function([X],y_hat)
calculate_loss=theano.function([X,y],loss)
predict=theano.function([X],prediction)以forword_prop=theano.function([X],y_hat)为例,我们在模子中计算了y_hat,而y_hat只需要输入数据X,因此我们在python中可以直接使用forward_prop(X)来计算,其他的都同理。
接下来,Theano最爽的事情来了,就是求导。不要太简单:
#求导
dw2=T.grad(loss,w2)
db2=T.grad(loss,b2)
dw1=T.grad(loss,w1)
db1=T.grad(loss,b1)
#更新值
gradient_step=theano.function(
[X,y],
updates=(
(w2,w2-epsilon*dw2),
(b2,b2-epsilon*db2),
(w1,w1-epsilon*dw1),
(b1,b1-epsilon*db1)
)
)
好了现在我们可以建立神经网络模型了:
def build_model(num_passes=20000,print_loss=False):
w1.set_value(np.random.randn(nn_input_dim, nn_hdim) / np.sqrt(nn_input_dim))
b1.set_value(np.zeros(nn_hdim))
w2.set_value(np.random.randn(nn_hdim, nn_output_dim) / np.sqrt(nn_hdim))
b2.set_value(np.zeros(nn_output_dim))
for i in xrange(0,num_passes):
gradient_step(train_X,train_y)
if print_loss and i%1000==0:
print "Loss after iteration %i: %f" %(i,calculate_loss(train_X,train_y))这段代码就是进行迭代的过程
看下结果:
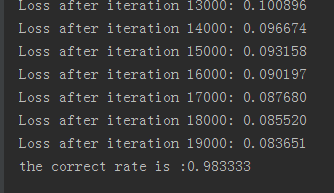
正确率还是很高的。
总结:Theano提供了比较简单而实用的深度学习框架,其模型简单求导简便等很多的优势使得在处理神经网络参数时候特别有用,完整代码见下面链接。
最后
以上就是幽默芒果最近收集整理的关于深度学习之四:使用Theano编写神经网络的全部内容,更多相关深度学习之四内容请搜索靠谱客的其他文章。








发表评论 取消回复