
线性概率模型
数据预处理:生成虚拟变量
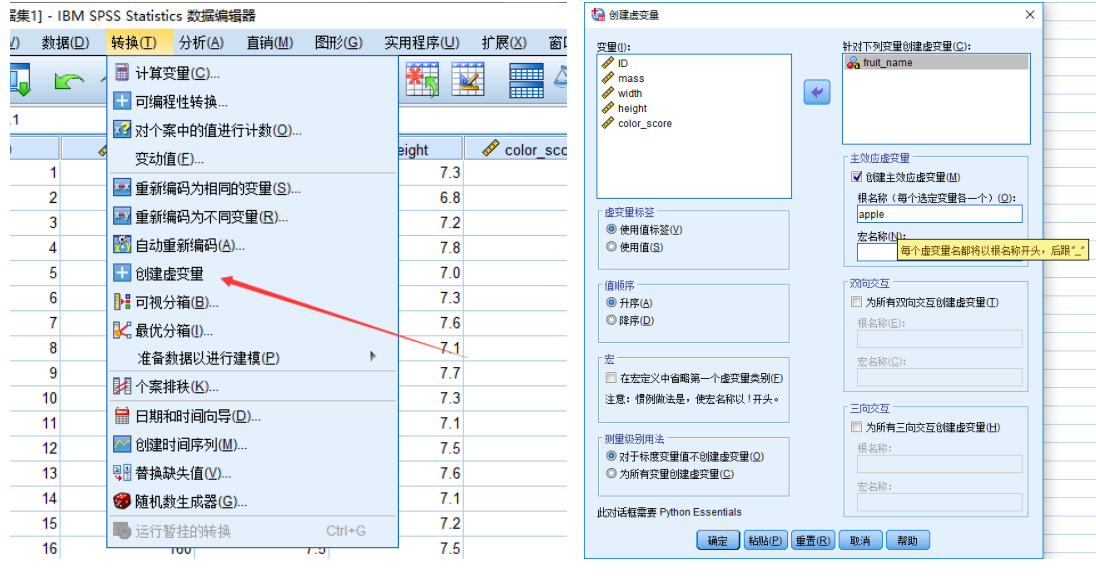
对于因变量为分类变量的情况,我们可以使用逻辑回归进行处理。
把y看成事件发生的概率,y>0.5表示发生;y<0.5表示不发生


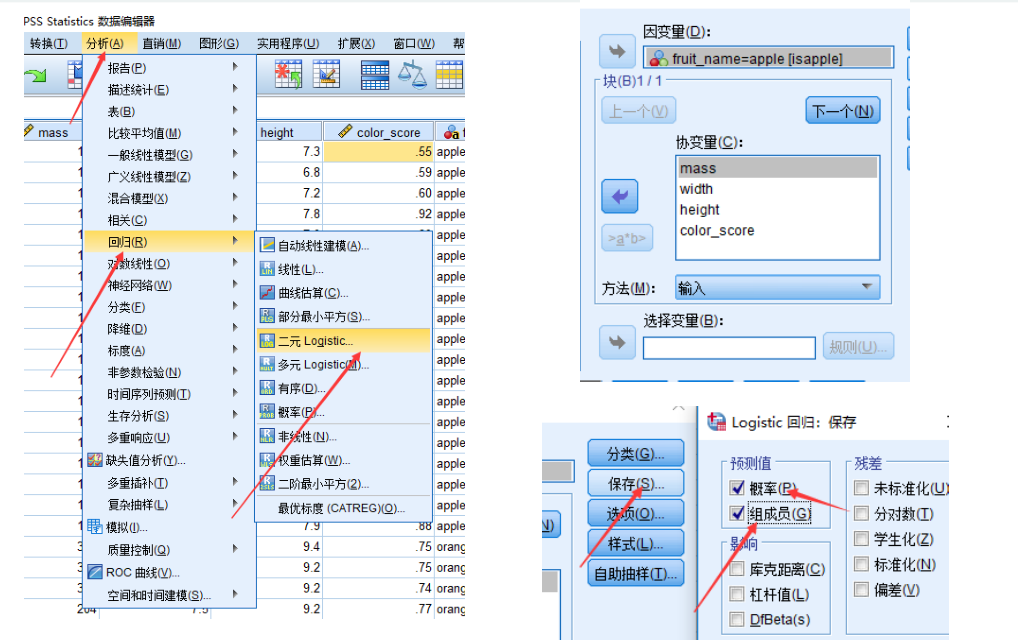
Spss求解逻辑回归
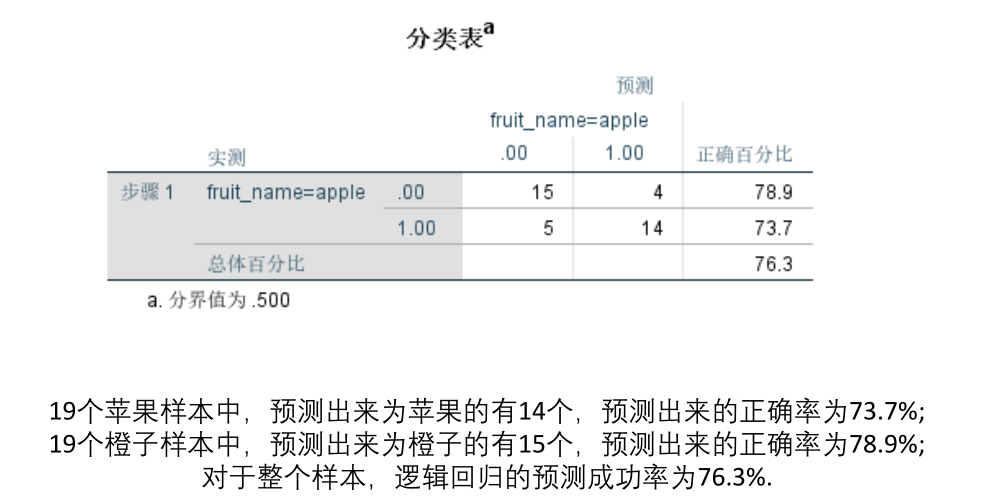
预测成功率

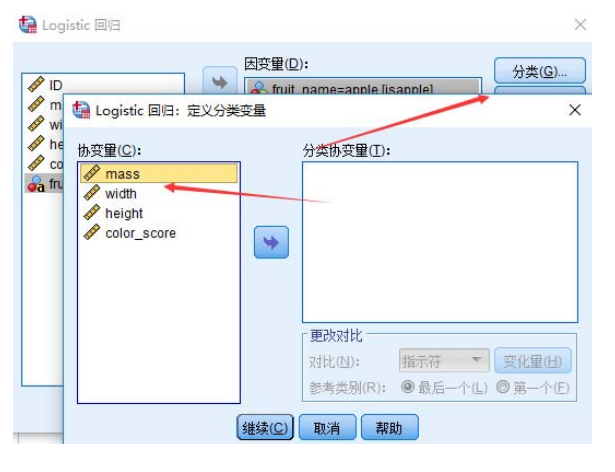
假如自变量有分类变量怎么办?
直接点击分类,然后定义分类协变量,Spss会自动帮我们生成
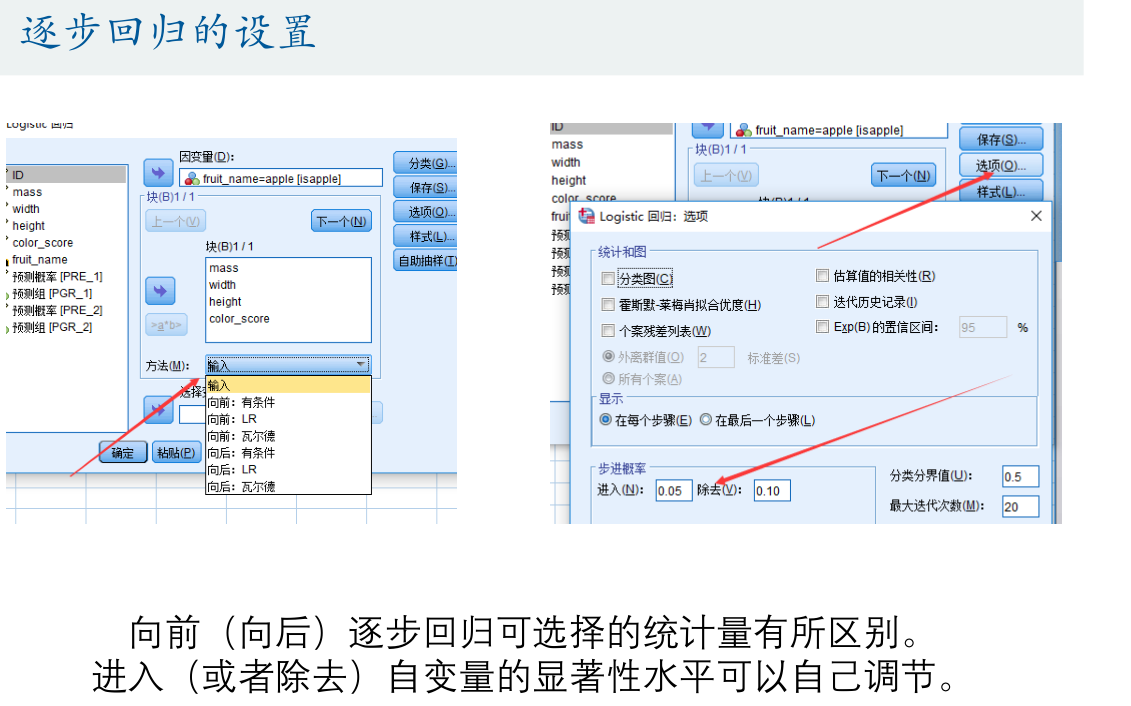
预测结果较差怎么办?
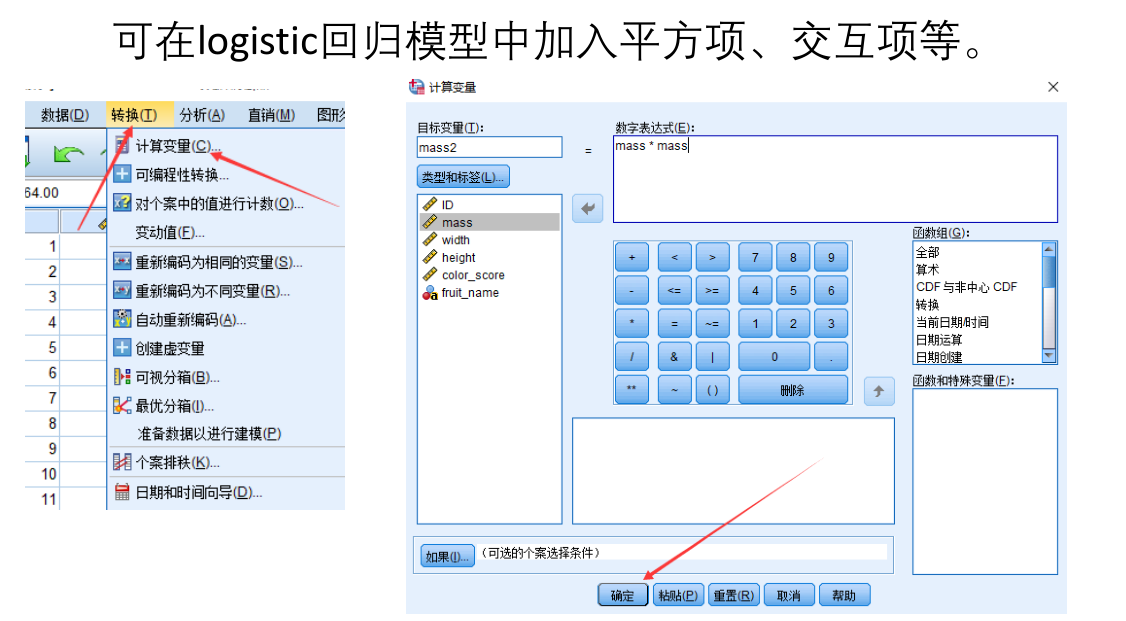
加入了平方项后,可能会过拟合
如何确定合适的模型?
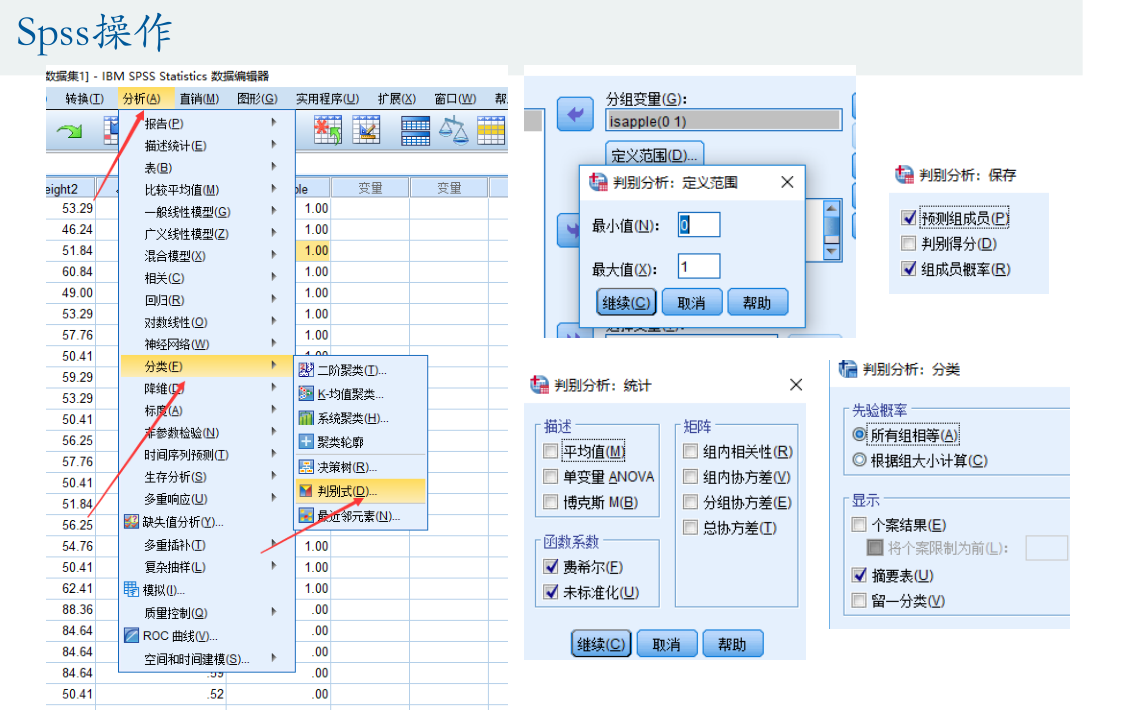
把数据分为训练组和测试组,用训练组的数据来估计出模型,再用测试组的数据来进行测试。(训练组和测试组的比例一般设置为80%和20%)已知分类结果的水果ID为1‐38,前19个为苹果,后19个为橙子。每类水果中随机抽出3个ID作为测试组,剩下的16个ID作为训练组。(比如:17‐19、36‐38这六个样本作为测试组)比较设置不同的自变量后的模型对于测试组的预测效果。
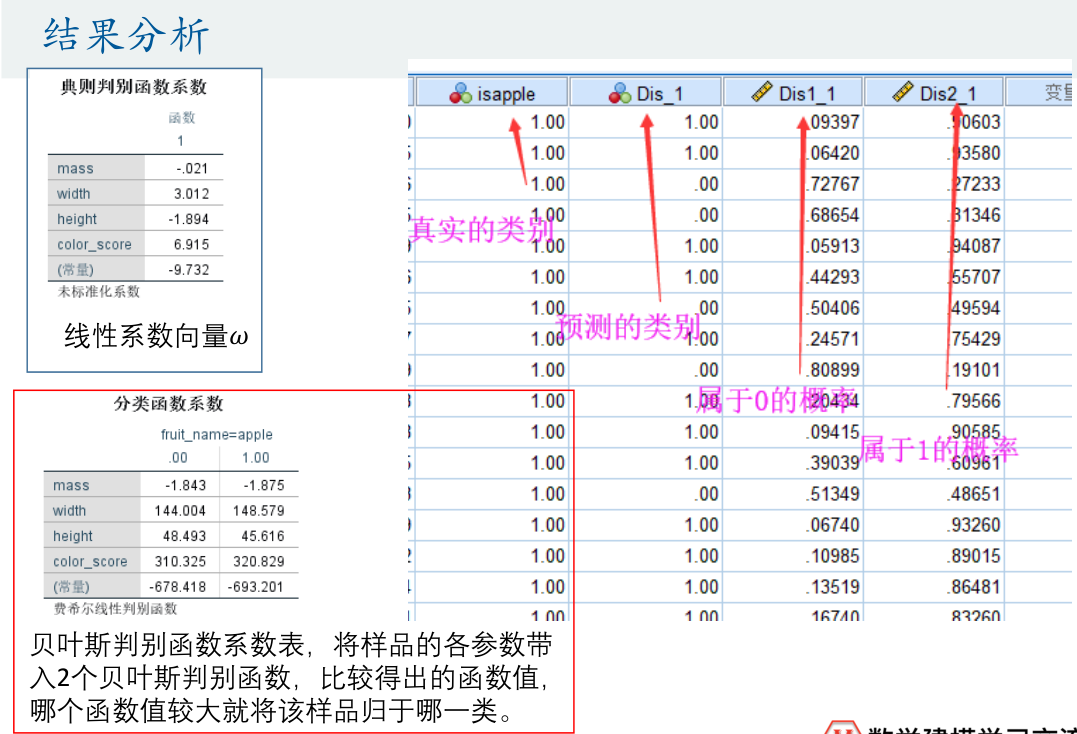
Fisher线性判别分析
详细证明和求解步骤:https://www.bilibili.com/video/av33101528/?p=3
LDA(Linear Discriminant Analysis)是一种经典的线性判别方法,又称Fisher判别分析。该方法思想比较简单:给定训练集样例,设法将样例投影到一维的直线上,使得同类样例的投影点尽可能接近和密集,异类投影点尽可能远离
多分类问题
现在水果的类别一共有四种

Logistic回归也可用于多分类
将连接函数:Sigmoid函数 推广为 Softmax函数
最后
以上就是耍酷铃铛最近收集整理的关于分类模型的全部内容,更多相关分类模型内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。






![[深度学习从入门到女装]3D U-JAPA-Net](https://www.shuijiaxian.com/files_image/reation/bcimg6.png)

发表评论 取消回复