1. 模型可解释性
基于复杂数据挖掘方法构建的预测模型,通常存在“黑箱问题”,导致其可解释性与可利用性降低。目前,机器学习模型可解释性总体上可分为2类:
- 事前可解释性:指通过训练结构简单、可解释性好的模型或将可解释性结合到具体的模型结构中的自解释模型使模型本身具备可解释能力。
- 事后可解释性:指通过开发可解释性技术解释已训练好的机器学习模型。根据解释目标和解释对象的不同,事后可解释性又可分为全局可解释性和局部可解释性。全局可解释性旨在帮助人们理解复杂模型背后的整体逻辑以及内部的工作机制;局部可解释性旨在帮助人们理解机器学习模型针对每一个输入样本的决策过程和决策依据。
本篇博客主要介绍局部可解释方法:LIME(Local Interpretable Model-agnostic Explanations,模型无关局部可解释方法)
2. LIME方法
2.1 具体流程
对于每一个输入实例,LIME首先利用该实例以及该实例的一组近邻数据训练一个易于解释的线性模型来拟合待解释模型的局部边界,然后基于该线性模型解释待解释模型针对该实例的决策依据,其中,线性模型的权重系数直接体现了当前决策中该实例的每一维特征的重要性(可以只针对重要特征进行解释)。其具体流程如下:
- 选择需要进行解释的样本 x i x_{i} xi;
- 基于 x i x_{i} xi产生扰动样本,并获得扰动样本在黑盒模型上的预测值,组成新的数据集;
- 根据扰动样本与预测样本之间的距离或相似度对扰动样本进行加权:在这里可以使用所有的统计距离、相似性矩阵,比如用指定宽度的指数内核将欧式距离转化为相似度。
- 在新数据集上,训练可解释的简单模型(一般为线性回归模型),得到对复杂机器学习模型局部的良好近似。
- 通过解释局部近似模型来解释 x i x_{i} xi的预测结果。
对于样本 x i x_{i} xi,LIME使用如下目标函数来衡量解释模型与被解释模型之间的差异: e x p l a n a t i o n ( x i ) = a r g m i n g ∈ G L ( f , g , π x i ) + Ω ( g ) explanation(x_{i})=argmin_{gin G}L(f,g,pi_{x_{i}})+Omega(g) explanation(xi)=argming∈GL(f,g,πxi)+Ω(g)其中 G G G是一类可解释的模型,即简单模型的一个集合; f f f为需要解释的模型; L L L是使函数最小化的损失函数; π x i pi_{x_{i}} πxi是扰动样本与预测样本 x i x_{i} xi之间的距离或相似度; Ω x Omega_{x} Ωx是可选的正则项,用于控制模型复杂度。
2.2 LIME特点
- LIME作用在单个样本上;
- LIME不提供对模型整体的解释,而是对每一个单独样本进行解释;
- 即使机器学习模型训练过程会产生一些抽象的特征,但是LIME是基于输入变量的特征进行的解释;
- LIME通过局部建立简单模型进行预测对大多数重要特征进行解释;
3. Python实现
LIME给不同的数据类型提供了不同的模型解释类,主要包括以下三种:
- lime.lime_tabular.LimeTabularExplainer类:针对表格型的2维数据;
- lime.lime_tabular.LimeImageExplainer类:针对图片型的3维数据;
- lime.lime_text.LimeTextExplainer类:针对文本型的字符串数据;
本篇博客先以比较常见的第一类数据为例进行说明,其他两类遇到合适的案例会再进行补充。
3.1 LimeTabularExplainer类
LimeTabularExplainer类是lime包针对表结构数据提供的解释器。其常用参数如下:
| 参数 | 作用 |
|---|---|
| training_data | 2维数组。 |
| mode | 指定分类(‘classification’)还是回归(‘regression’)。 |
| training_labels | 非必须参数。指定训练数据的标记。 |
| feature_names | training_data数据的列名。 |
| categorical_features | training_data中的类别特征对应的列名。 |
| categorical_names | training_data中categorical_features中每个列中的值映射到其对应的名称上。 |
| kernel_width | 指数核的宽度。用于计算扰动后的样本与实例的相似度。 |
| kernel | 相似度核。 |
| class_names | 类别名称。 |
| feature_selection | 特征选择方法。可以使用这个参数控制输入简单模型的特征。 |
| discretize_continuous | 若设为True,则所有非类别变量都会被离散化。 |
| discretizer | 若discretize_continuos为True时,指定离散方法。除了指定的方法外可以自定义离散方法。 |
| sample_around_instance | |
| training_data_stats |
LimeTabularExplainer类中一个很重要的方法即为:explain_instance(),其主要参数如下:
| 参数 | 作用 |
|---|---|
| data_row | 要解释的单个样本; |
| predict_fn | 预测函数。对于分类问题,要求输出预测概率;对于回归问题,输出预测值; |
| labels | 需要解释的标记,该参数是个迭代器型的变量 |
| top_labels | 如果值不为空,则不收labels参数的限制,对预测概率最高的top K个标记进行解释; |
| num_features | 指定待解释的变量数; |
| num_samples | 线性模型中的训练数据量; |
| distance_metric | 用于权重计算的距离矩阵; |
| model_regressor | 指定线性回归模型; |
Tips:无论带解释模型是回归模型还是分类模型,针对单个样本训练的都是回归模型,所以predict_fn参数对于问题其预测函数要求输出的是预测概率而不是预测类别。
3.2 Python代码
本文以boston房价数据、wine红酒数据为例,使用lime包来分别对XGBoost的分类、回归模型的可解释性进行说明。在这里XGBoost模型的参数设置不是重点。其代码具体如下:
import pandas as pd
import numpy as np
from sklearn.datasets import load_boston,load_wine
from sklearn.model_selection import train_test_split
import lime
import lime.lime_tabular
from xgboost import XGBRegressor,XGBClassifier
#分类模型
wine=load_wine()
X=wine.data
y=wine.target
features=wine.feature_names
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)
xgbc=XGBClassifier(booster='gbtree',n_estimators=200,max_depth=3)
xgbc.fit(X_train,y_train)
explainer=lime.lime_tabular.LimeTabularExplainer(X_train,feature_names=features,
class_names=[0,1,2])
predict_fn_xgb=lambda x:xgbc.predict_proba(x).astype(float)
exp=explainer.explain_instance(X_test[0],predict_fn_xgb,num_features=13)
#在Spyder中可以使用这种方式输出图表
#如果是在jupyter中运行,可以使用exp.show_in_notebook()
exp.as_pyplot_figure()
#回归模型
boston=load_boston()
X=boston.data
y=boston.target
features=boston.feature_names
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)
xgbr=XGBRegressor(booster='gbtree',n_estimators=200,max_depth=3)
xgbr.fit(X_train,y_train)
explainer1=lime.lime_tabular.LimeTabularExplainer(X_train,mode='regression',
feature_names=features)
predict_fn_xgb=lambda x:xgbr.predict(x).astype(float)
exp1=explainer1.explain_instance(X_test[0],predict_fn_xgb,num_features=13)
exp1.as_pyplot_figure()
其结果如下:
分类模型:
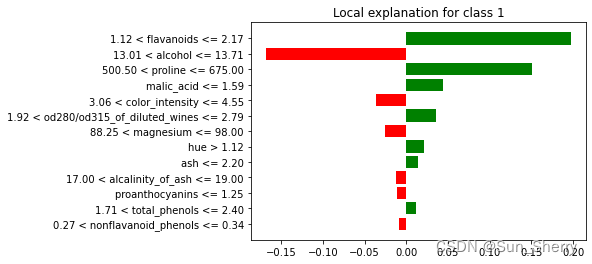
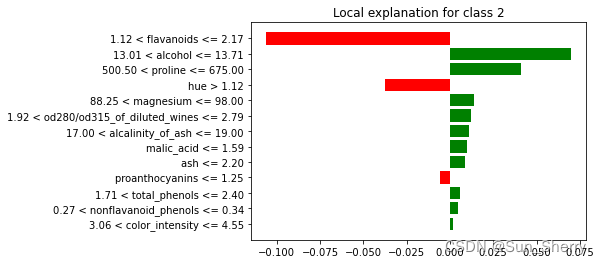
as_pyplot_figure()有个参数label(默认值为1),可以与explain_instance()配合展示针对指定标签的解释。具体代码如下:
exp=explainer.explain_instance(X_test[0],predict_fn_xgb,num_features=13,labels=[2])
exp.as_pyplot_figure(label=2)
其结果如下:
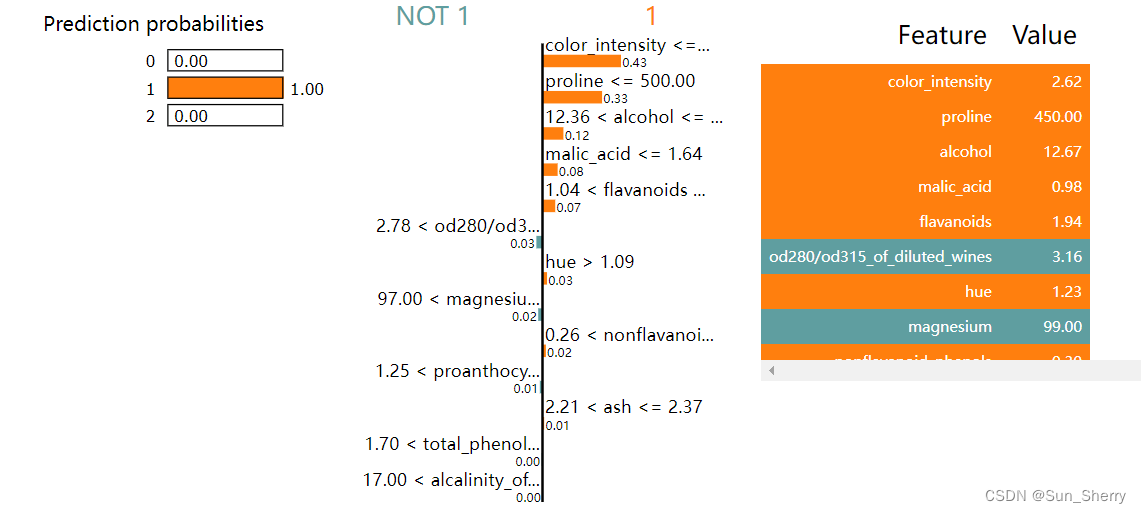
使用show_in_notebook()在其他样本上得到的结果如下:
回归模型:
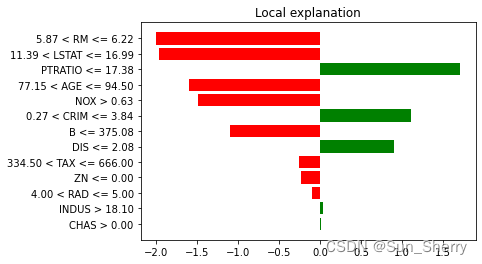
参考文献
- 《数据挖掘过程中的可解释性问题研究》
- 《机器学习模型可解释性方法、应用与安全研究综述》
- 《特征选择与模型可解释性在代谢综合征风险预测中的应用研究》
- 《机器学习模型的可解释性》
最后
以上就是鲤鱼篮球最近收集整理的关于模型解释性:Lime包的使用的全部内容,更多相关模型解释性:Lime包内容请搜索靠谱客的其他文章。

![[可解释机器学习]Task06:LIME算法学习一、 LIME算法讲解二、LIME论文逐句精读](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)






发表评论 取消回复