论文概要
LIME
LIME (Local Interpretable Model-agnostic Explanations):一种新颖的解释技术,通过在预测周围局部学习一个可解释模型,以一种可解释的和可信赖的方法来解释任何分类器的预测。主要贡献总结如下:
- LIME:一种通过用可解释性模型对预测进行局部近似,以一种可信赖的方式对于任何分类器或回归器预测进行解释的算法。
- SP-LIME:该方法通过子模块优化,选择一组具有解释的代表性实例来解决“模型信任”问题。
Algorithmic process analysis
假设建立一个大眼仔与树蛙的分类器
f
(
x
)
f(x)
f(x),若想直接解释这个模型为什么这样分类是非常困难的。
LIME提供了一个局部解释的思路:选取一个被解释实例(下图中星星-玩具树蛙),并用简单的线性回归模型来拟合决策边界,从而解释模型
f
(
x
)
f(x)
f(x)在这条边界上是如何做决策的。
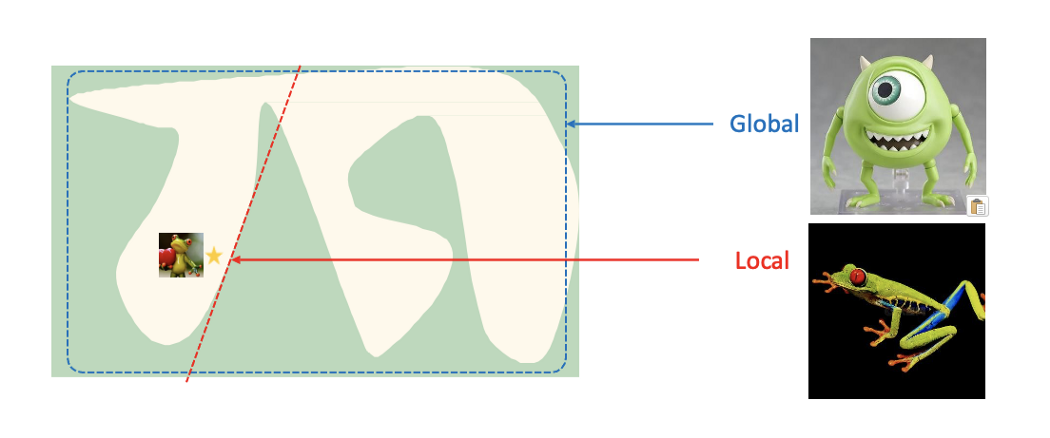
LIME算法过程
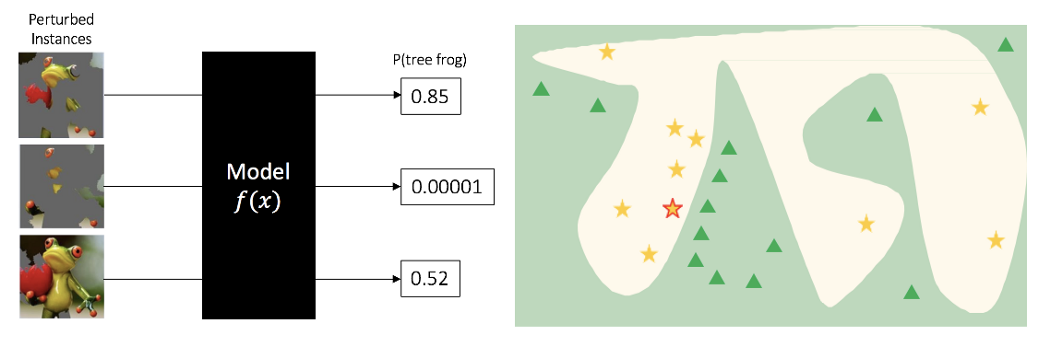
Step1:将数据分割成小区块,随机扰动被解释实例的小区块产生新样本,喂入模型 f ( x ) f(x) f(x)预测结果。
将玩具树蛙的图片喂入模型
f
(
x
)
f(x)
f(x)预测出为树蛙的概率为
0.54
0.54
0.54。为了了解该模型所做的决策,将此图片根据 超像素分割算法 切分成
M
M
M个
Super Pixel
(
S
P
1
,
S
P
2
,
…
,
S
P
M
)
text{Super Pixel }(SP_1, SP_2, dots, SP_M)
Super Pixel (SP1,SP2,…,SPM)。

注:
x
i
′
=
S
P
i
x'_i=SP_i
xi′=SPi,每个
Super Pixel
text{Super Pixel}
Super Pixel均有两个取值:0表示该块超像素被灰色覆盖;1表示该块超像素为原图块(刚划分好时,每个
x
i
′
=
1
x'_i=1
xi′=1,表示每个超像素块均为原始图块)。
z
′
z'
z′随机扰动
x
′
x'
x′,使
Super Pixel
text{Super Pixel}
Super Pixel的值随机指派为0或1。
根据上述可知,共有
M
M
M个
x
i
′
x'_i
xi′,而通过扰动,每个
z
i
′
z'_i
zi′具有两种取值。通过将
M
M
M个
z
i
′
z'_i
zi′随机指派为0或1,可以得到新的扰动样本
z
z
z,从而可到新的扰动数据集
Z
mathcal{Z}
Z。(具体理解见代码案例)
将扰动数据集
Z
mathcal{Z}
Z喂入分类模型
f
(
⋅
)
f(sdot)
f(⋅)中,就能得出结果
y
y
y(这里
y
y
y表示是树蛙的概率),从而了解到新数据集在分类模型的分布状况。
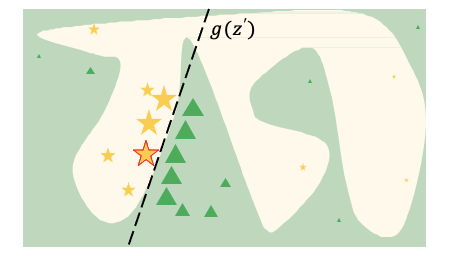
Step2:根据样本相似度(例如特征距离)给予样本权重。
利用核函数(kernel function)来计算新扰动样本
z
z
z与被解释实例
x
x
x的相似程度,与被解释实例越相似(越近)给与较大的权重,越不相似(越远)则给予较小的权重。
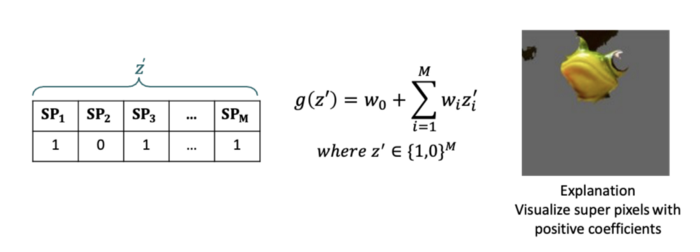
Step3:根据扰动样本训练一个简单的线性回归模型 g ( z ′ ) g(z') g(z′),并根据模型的系数解释实例。
如下图,可以理解模型会将玩具树蛙的照片判断为树蛙的原因,主要是因为玩具树蛙的头部特征。
**注:**对于结构性数据也是以上三个步骤,进行数据扰动(扰动的方式则是随机选择特征进行扰动) → rightarrow →定义相似度 → rightarrow →训练简单可解释的模型。
Local Interpretable Model-agnostic Explanations
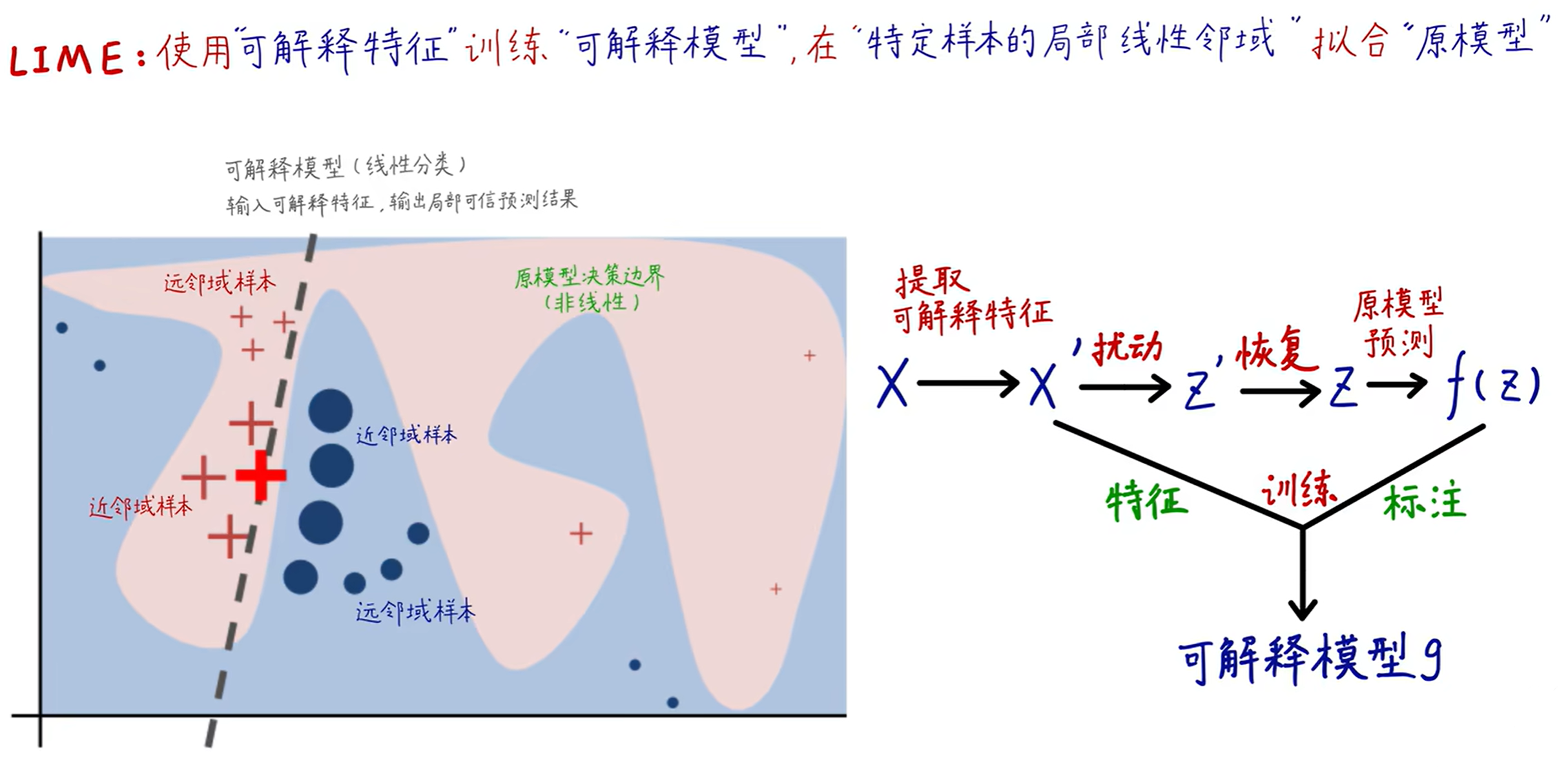
LIME的总体目标是在局部可信赖的分类器的可解释性表示上学习一个可解释性模型。
x
∈
R
d
xinmathbb{R}^d
x∈Rd:一个被解释实例的原始表示
x
′
∈
{
0
,
1
}
d
′
x'in{0,1}^{d'}
x′∈{0,1}d′:一个用于可解释性表示的二进制向量
- 对于图片而言,假设原始图片为 x x x,将 x x x划分为 m m m个超像素图块 x ′ x' x′
- 对于文字而言, x ′ x' x′指词袋(类似于one-hot)
g g g:可解释性模型(线性模型、决策树等其中一种)
- 这使得解释可以很容易地以视觉或文本形式呈现给用户
- 定义域: { 0 , 1 } d ′ {0,1}^{d'} {0,1}d′
G
G
G:表示一类潜在的可解释性模型,如线性模型、决策树或下降规则列表
Ω
(
g
)
Omega (g)
Ω(g):作为可解释性模型
g
∈
G
gin G
g∈G复杂性的度量
- 决策树: Ω ( g ) Omega (g) Ω(g)表示树深
- 线性模型: Ω ( g ) Omega (g) Ω(g)表示非零权重的数量
f
:
R
d
→
R
f:mathbb{R}^d rightarrow mathbb{R}
f:Rd→R:被解释模型
f
(
x
)
f(x)
f(x):在分类任务中,其表示
x
x
x属于一个确定类别的概率
π
x
(
z
)
pi_x(z)
πx(z):作为实例
z
z
z到
x
x
x之间的邻近度度量,以定义
x
x
x 周围的局部性
L
(
f
,
g
,
π
x
)
mathcal{L}(f, g, pi_x)
L(f,g,πx):度量
g
g
g在由
π
x
pi_x
πx定义的位置上逼近
f
f
f时的不可信程度
为了确保可解释性和局部保真度,需要在
Ω
(
g
)
Omega (g)
Ω(g)足够低以至于人类可以解释的情况下,最小化
L
(
f
,
g
,
π
x
)
mathcal{L}(f, g, pi_x)
L(f,g,πx)。
ξ
(
x
)
=
argmin
g
∈
G
L
(
f
,
g
,
π
x
)
+
Ω
(
g
)
(
1
)
xi(x)=underset{g in G}{operatorname{argmin}} mathcal{L}left(f, g, pi_xright)+Omega(g)quad (1)
ξ(x)=g∈GargminL(f,g,πx)+Ω(g)(1)
该公式可用于不同的解释族
G
G
G、保真度函数
L
mathcal{L}
L和复杂性度量
Ω
Omega
Ω。
Sampling for Local Exploration
为了实现模型不可知性,本文在对
f
f
f不做任何假设的前提下,最小化邻近原则损失
L
(
f
,
g
,
π
x
)
mathcal{L}(f, g, pi_x)
L(f,g,πx)。因此,为了学习
f
f
f在可解释输入变化时的局部行为,本文通过抽取样本来近似
L
(
f
,
g
,
π
x
)
mathcal{L}(f, g, pi_x)
L(f,g,πx),并用
π
x
pi_x
πx进行加权。本文通过在随机处均匀地绘制
x
′
x'
x′的非零元素来采样
x
′
x'
x′周围的实例。给定一个扰动样本
z
′
∈
{
0
,
1
}
d
′
z'in{0,1}^{d'}
z′∈{0,1}d′(其中包含
x
′
x'
x′的非零元素的一部分),本文恢复原始表示
z
∈
R
d
zin R^d
z∈Rd中的样本,并且得到
f
(
z
)
f(z)
f(z),使其作为解释模型的标签。给定带有相关标签的扰动样本数据集
Z
mathcal{Z}
Z,本文优化上述损失方程得到一个解释。LIME的主要思想如下图所示,本文分别在
x
x
x的附近(由于
π
x
pi_x
πx而具有很高权重)和远离
x
x
x的地方(来自
π
x
pi_x
πx的低权重)采样实例。尽管原始模型可能过于复杂,无法进行全局解释,但LIME给出了一个局部可信赖的解释,其中局部性由
π
x
pi_x
πx捕获。
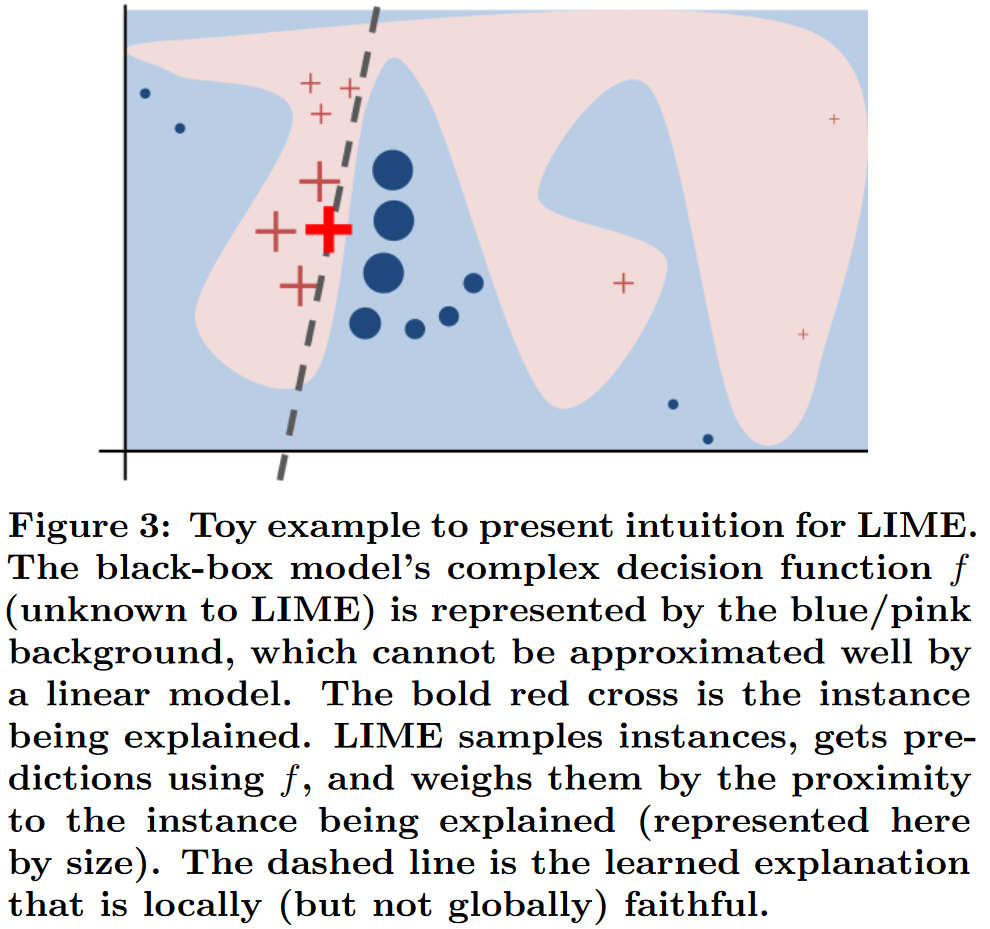
上图描述:黑盒模型复杂的决策函数 f f f(LIME对其不可知)被蓝色/粉色背景所表示,其不能被线性模型很好地表示。图中红十字表示被解释的实例。LIME对实例进行采样,使用 f f f得到预测,并通过与被解释实例的接近程度对它们加权。虚线是局部可信赖的学习到的解释。
Sparse Linear Explanations
假设
G
G
G为线性模型类,使得
g
(
z
′
)
=
w
g
⋅
z
′
g(z')=w_gsdot z'
g(z′)=wg⋅z′。使用局部加权平方损失作为
L
mathcal{L}
L,定义如下式所示。其中
π
x
(
z
)
=
e
x
p
(
−
D
(
x
,
z
)
2
/
σ
2
)
)
pi_x(z)=exp(-D(x,z)^2/sigma^2))
πx(z)=exp(−D(x,z)2/σ2))是定义在某些宽度为
σ
sigma
σ的距离函数
D
D
D上的指数核。
L
(
f
,
g
,
π
x
)
=
∑
z
,
z
′
∈
Z
π
x
(
z
)
(
f
(
z
)
−
g
(
z
′
)
)
2
(
2
)
mathcal{L}left(f, g, pi_xright)=sum_{z, z^{prime} in mathcal{Z}} pi_x(z)left(f(z)-gleft(z^{prime}right)right)^2quad (2)
L(f,g,πx)=∑z,z′∈Zπx(z)(f(z)−g(z′))2(2)
对于文本分类,本文通过让可解释表示是词袋,并通过对词数设置一个限制
K
K
K,即
Ω
(
g
)
=
∞
1
[
∥
w
g
∥
0
>
K
]
Omega (g)=infin mathbb{1}[left| w_g right|_0gt K]
Ω(g)=∞1[∥wg∥0>K]来确保解释是可解释的。对于图片分类,使用相同的
Ω
Omega
Ω,同时使用“超像素”代替词,使图片的可解释性表示是一个二元变量:1表示原始超像素;0超像素灰度化。
Ω
Omega
Ω的特殊选取使得很难直接求解损失函数,但是我们通过先使用Lasso选择
K
K
K个特征,然后用最小二乘学习权重来近似它。

代码案例
完整代码
本案例使用Google的InceptionV3对被解释实例进行预测,其预测结果为:

Step1:建立超像素(Super Pixel)产生多个扰动样本
使用快速移位分割(quickshift)演算法生成超像素
在这一步,使用quickshift算法得到52个SuperPixelx ′ x' x′。之后,又通过随机扰动得到150个perturbationsz ′ z' z′。最后,将image,perturbations和superpixels传入perturb_image()得到扰动样本 z z z。
import skimage.segmentation as segmentation
# 将原始图片分块,superpixels.shape=(299,299)
# 在指定位置标记上所属块
superpixels = segmentation.quickshift(Xi[0], kernel_size=4, max_dist=200, ratio=0.2)
num_superpixels = np.unique(superpixels).shape[0] # 值为52
plt.imshow(segmentation.mark_boundaries(Xi[0]/2 + 0.5, superpixels))
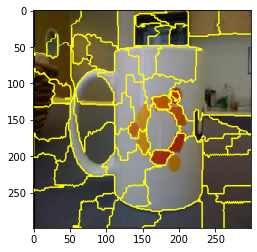
产生多个随机的扰动样本,对于每个超像素指派 { 0 , 1 } {0,1} {0,1}:0表示灰色;1表示原本色彩
num_perturb = 150 # 指定扰动样本个数为150
perturbations = np.random.binomial(1, 0.5, size=(num_perturb, num_superpixels)) # shape=(150, 52)
perturbations[0] # 显示第一个扰动样本
'''
array([1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0,
1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1,
1, 0, 1, 0, 1, 1, 0, 1])
'''
def perturb_image(img, perturbation, segments):
# 得到扰动样本
active_pixels = np.where(perturbation == 1)[0] # 指定perturbation值为1时的下标
mask = np.zeros(segments.shape) # (299,299) 全0
for active in active_pixels:
mask[segments == active] = 1 # 根据perturbation值为1所对应的区块,将mask对应的区块值设置为1
perturbed_image = copy.deepcopy(img)
perturbed_image = perturbed_image * mask[:, :, np.newaxis] # (299,299,3) * (299, 299, 1)
'''
以深度为0时为例
(299, 3) * (299, 1)表示前者(共有三列)每列都与后者(只有一列)的列相乘
'''
return perturbed_image
fig, ax = plt.subplots(2, 10, figsize=(30, 6),
subplot_kw={'xticks':[], 'yticks':[]},
gridspec_kw=dict(hspace=0.1, wspace=0.1))
for i in range(10):
ax[0, i].imshow(perturb_image(Xi[0]/2+0.5, perturbations[i], superpixels))
ax[1, i].imshow(perturb_image(Xi[0]/2+0.5, perturbations[i+9], superpixels))

Step2:使用ML分类器预测新生成的图像类别
将得到的扰动样本 z z z喂入InceptionV3模型中进行预测,计算Sparse Linear Explanations中临近损失函数 L ( f , g , π x ) = ∑ z , z ′ ∈ Z π x ( z ) ( f ( z ) − g ( z ′ ) ) 2 mathcal{L}left(f, g, pi_xright)=sum_{z, z^{prime} in mathcal{Z}} pi_x(z)left(f(z)-gleft(z^{prime}right)right)^2 L(f,g,πx)=∑z,z′∈Zπx(z)(f(z)−g(z′))2中的 f ( z ) f(z) f(z)。
predictions = []
# f(z)
for pert in perturbations: # 先得到z'
perturbed_img = perturb_image(Xi[0], pert, superpixels) # 还原出扰动样本z
pred = model.predict(np.expand_dims(perturbed_img, axis=0))
predictions.append(pred)
predictions = np.array(predictions)
predictions.shape
'''
(150, 1, 1000)
'''
Step3:计算原始图像与新生成图像之间的距离,并计算每个新生成图像的权重(相似性)
这一步使用核函数计算权重 π x ( z ) = e x p ( − D ( x , z ) 2 σ 2 ) pi_x(z)=exp(frac{-D(x,z)^2}{sigma^2}) πx(z)=exp(σ2−D(x,z)2)
from sklearn import metrics
original_image = np.expand_dims(np.ones(num_superpixels), axis=0) # 原始图片每个超像素块x'=1
distances = metrics.pairwise_distances(perturbations, original_image, metric='cosine').ravel()
# 核函数
kernel_width = 0.25
weights = np.sqrt(np.exp(-(distances**2)/kernel_width**2)) # kernel function
weights.shape
'''
(150,)
'''
Step4:使用
perturbations,predictions和weights去拟合可解释模型(线性)
计算Sparse Linear Explanations中临近损失函数 L ( f , g , π x ) = ∑ z , z ′ ∈ Z π x ( z ) ( f ( z ) − g ( z ′ ) ) 2 mathcal{L}left(f, g, pi_xright)=sum_{z, z^{prime} in mathcal{Z}} pi_x(z)left(f(z)-gleft(z^{prime}right)right)^2 L(f,g,πx)=∑z,z′∈Zπx(z)(f(z)−g(z′))2中的 g ( z ′ ) g(z') g(z′)。 从第5行代码可以看出,线性回归模型传入perturbations即 z ′ z' z′(因此其并没有通过perturb_image()函数去还原扰动样本 z z z)。且其标签 y y y对应的就是原始图片预测概率为 77.65 77.65% 77.65的标签coffee_mug,在perdictions中对150个扰动样本 z z z进行了预测,并输出了1000个预测项,其中coffee_mug对应的预测项下标为top_pred_classes[0],这就是为什么第5行代码中y=predictions[:,:,class_to_explain]。权重则是核函数计算的结果。
第10行代码找出线性回归模型中对预测起作用的前10个特征,并根据该特征重组处扰动 z ′ z' z′,之后根据该扰动 z ′ z' z′还原出扰动样本 z z z。最后,就呈现出解释图片。
from sklearn.linear_model import LinearRegression
class_to_explain = top_pred_classes[0]
simpler_model = LinearRegression()
# z' = perturbations
simpler_model.fit(X=perturbations, y=predictions[:,:,class_to_explain], sample_weight=weights)
coeff = simpler_model.coef_[0]
# 计算top features(superpixels)
# np.argsort()从小至大排序,返回值为下标
num_top_features = 10
top_features = np.argsort(coeff)[-num_top_features:]
# 显示LIME explanation(image with top features)
import skimage
mask = np.zeros(num_superpixels)
mask[top_features] = True
skimage.io.imshow(perturb_image(Xi[0]/2+0.5, mask, superpixels))
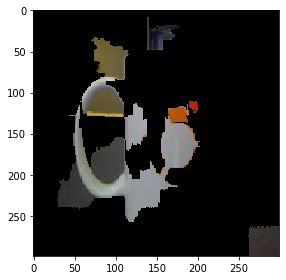
最后
以上就是迷路戒指最近收集整理的关于【论文阅读】LIME概要及代码案例论文概要代码案例的全部内容,更多相关【论文阅读】LIME概要及代码案例论文概要代码案例内容请搜索靠谱客的其他文章。



![[可解释机器学习]Task06:LIME算法学习一、 LIME算法讲解二、LIME论文逐句精读](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)




发表评论 取消回复