针对分类问题,划分规则的评判可以分为两步:
1.如果一个节点上的数据都差不多是同一类别,那么,这个节点就几乎不需要再做划分了,否则想要针对该节点,生成新的划分规则。
2.如果新的规则能基本上把节点上不同类别的数据离开,使得每个子节点上都是类别比较单一的数据,那么这个规则就是一个好规则。
当前节点记为m,节点上一共有Nm个数据。定义类别i在该节点上的占比如下:
![]()
现在定义节点的不纯度,通常记为Hm。数值越接近0,数据类型越单一。常用指标如下:
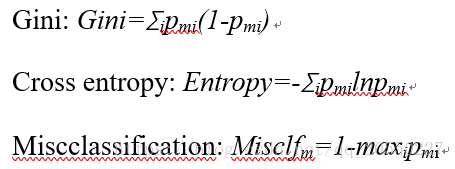
在节点不纯的基础上,进一步定义划分规则的不纯度。依旧以Gini为例,假设节点根据某种规则被划分为两个子节点,Ni![]() 为第i个子节点的数据个数,Ginii表示第i个子节点的Gini指标。权重为子节点的数据量占比。
为第i个子节点的数据个数,Ginii表示第i个子节点的Gini指标。权重为子节点的数据量占比。
![]()
接下来讨论划分规则的处理方法。
- 当节点的Gini指标小于等于某个阈值(不妨记作min_impurity_split)时,则表示该节点不需要进一步拆分,否则需要生成新的划分规则。
- 对于每一个需要再次划分的节点,选择Gini指标最低的划分规则来生成子节点,并不断重复这个过程,直至所有节点都不需要再次划分。决策树的划分规则其实就是贪心算法。
上面的讨论针对的是分类问题,其实决策树也能解决回归问题,具体过程和分类问题大同小异,唯一的区别就是将不纯度的评判标准改为距离误差,比如均方差(MSE)。
最后
以上就是爱撒娇路人最近收集整理的关于决策树评判标准的全部内容,更多相关决策树评判标准内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复