3.8 练习题
数据集准备
import numpy as np
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
X,y = mnist["data"], mnist["target"]
y = y.astype(np.uint8) # 将字符型标记转换为数值型
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
1. 超过97%准确率的分类器
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
param_grid = [{'weights':["uniform","distance"], 'n_neighbors':[3,4,5]}]
grid_search = GridSearchCV(knn_clf, param_grid, cv=5, verbose=3)
grid_search.fit(X_train, y_train)
print(grid_search.best_params_)
print(grid_search.best_score_)
from sklearn.metrics import accuracy_score
y_pred = grid_search.predict(X_test)
print(accuracy_score(y_test, y_pred))
2. 数据增广
from scipy.ndimage.interpolation import shift
from sklearn.neighbors import KNeighborsClassifier
def shift_image(image, dx, dy):
image = image.reshape((28, 28))
shifted_image = shift(image, [dx, dy], cval=0, mode="constant")
return shifted_image.reshape([-1])
image = X_train[1000]
shifted_image_down = shift_image(image, 0, 5)
shifted_image_left = shift_image(image, -5, 0)
plt.figure(figsize=(12, 3))
plt.title("Original", fontsize=14)
plt.imshow(image.reshape(28, 28), interpolation="nearest", cmap="Greys")
plt.title("Shifted down", fontsize=14)
plt.imshow(shifted_image_down.reshape(28, 28), interpolation="nearest", cmap="Greys")
plt.title("Shifted left", fontsize=14)
plt.imshow(shifted_image_left.reshape(28, 28), interpolation="nearest", cmap="Greys")
plt.show()
X_train_augmented = [image for image in X_train]
y_train_augmented = [label for label in y_train]
for dx, dy in ((1, 0), (-1, 0), (0, 1), (0, -1)):
for image, label in zip(X_train, y_train):
X_train_augmented.append(shift_image(image, dx, dy))
y_train_augmented.append(label)
X_train_augmented = np.array(X_train_augmented)
y_train_augmented = np.array(y_train_augmented)
shuffle_idx = np.random.permutation(len(X_train_augmented))
X_train_augmented = X_train_augmented[shuffle_idx]
y_train_augmented = y_train_augmented[shuffle_idx]
knn_clf = KNeighborsClassifier(**grid_search.best_params_)
knn_clf.fit(X_train_augmented, y_train_augmented)
y_pred = knn_clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
3. 处理泰坦尼克号数据集
其目标是根据乘客的年龄、性别、乘客级别、出发地点等属性来预测他们是否幸存。
# -------------下载titanic数据集-------------
import os
import urllib.request
TITANIC_PATH = os.path.join("dataset", "titanic")
DOWNLOAD_URL = "https://raw.githubusercontent.com/ageron/handson-ml2/master/datasets/titanic/"
def fecth_titanic_data(url=DOWNLOAD_URL, path=TITANIC_PATH):
if not os.path.isdir(path):
os.makedirs(path)
for filename in ('train.csv', 'test.csv'):
filepath = os.path.join(path, filename)
if not os.path.isfile(filepath):
print('Downloading', filename)
urllib.request.urlretrieve(url + filename, filepath)
# fecth_titanic_data()
# -------------加载并处理数据集-------------
import pandas as pd
import numpy as np
def load_titanic_data(filename, titanic_path=TITANIC_PATH):
csv_path = os.path.join(titanic_path, filename)
return pd.read_csv(csv_path)
train_data = load_titanic_data('train.csv')
test_data = load_titanic_data('test.csv')
# 将PassengerId设为索引
train_data = train_data.set_index("PassengerId")
test_data = test_data.set_index("PassengerId")
# 建立数据处理流水线
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
num_pipeline = Pipeline([ # 数值型数据处理流水线
('impute', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
cat_pipeline = Pipeline([ # 分类数据处理流水线
('impute', SimpleImputer(strategy='most_frequent')),
('cat_encoder', OneHotEncoder(sparse=False))
])
# 定义转换器
from sklearn.compose import ColumnTransformer
num_attribs = ["Age", "SibSp", "Parch", "Fare"]
cat_attribs = ["Pclass", "Sex", "Embarked"]
preprocess_pipeline = ColumnTransformer([
('num', num_pipeline, num_attribs),
('cat', cat_pipeline, cat_attribs),
])
# 处理数据
X_train = preprocess_pipeline.fit_transform(train_data[num_attribs+cat_attribs])
y_trian = train_data['Survived']
# -------------模型训练-------------
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(n_estimators=100, random_state=42)
forest_clf.fit(X_train, y_trian)
X_test = preprocess_pipeline.fit_transform(test_data[num_attribs+cat_attribs])
y_pred = forest_clf.predict(X_test)
# -------------模型评估和验证-------------
from sklearn.model_selection import cross_val_score
forest_score = cross_val_score(forest_clf, X_train, y_trian, cv=10)
print(forest_score.mean())
# 换一种模型然后评估
from sklearn.svm import SVC
svm_clf = SVC(gamma='auto')
svm_score = cross_val_score(svm_clf, X_train, y_trian, cv=10)
print(svm_score.mean())
svm_clf.fit(X_train, y_trian)
y_pred_svc = svm_clf.predict(X_test)
result = pd.DataFrame(y_pred_svc, index=test_data.index)
result.columns = ['Survived']
result.to_csv("gender submission.csv")
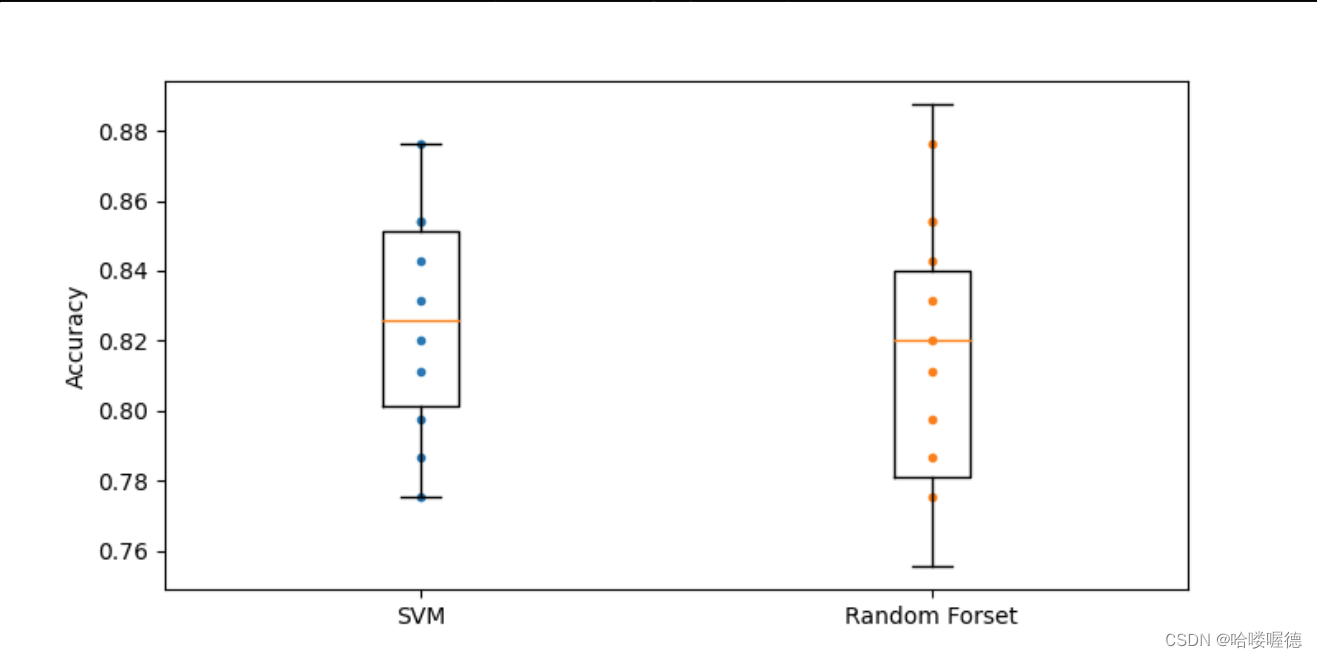
# 绘制箱型图
import matplotlib.pyplot as plt
plt.figure(figsize=(8,4))
plt.plot([1]*10, svm_score, '.')
plt.plot([2]*10, svm_score, '.')
plt.boxplot([svm_score, forest_score], labels=("SVM","Random Forset"))
plt.ylabel("Accuracy")
plt.show()
4. 处理垃圾邮件
# ------------下载邮件------------
import os
import tarfile
import urllib.request
DOWNLOAD_ROOT = "http://spamassassin.apache.org/old/publiccorpus/"
HAM_URL = DOWNLOAD_ROOT + "20030228_easy_ham.tar.bz2"
SPAM_URL = DOWNLOAD_ROOT + "20030228_spam.tar.bz2"
SPAM_PATH = os.path.join("dataset", "spam")
def fetch_spam_data(ham_url=HAM_URL, spam_url=SPAM_URL, spam_path=SPAM_PATH):
if not os.path.isdir(spam_path):
os.makedirs(spam_path)
for filename, url in (("ham.tar.bz2", ham_url), ("spam.tar.bz2", spam_url)):
path = os.path.join(spam_path, filename)
if not os.path.isfile(path):
urllib.request.urlretrieve(url, path)
tar_bz2_file = tarfile.open(path)
tar_bz2_file.extractall(path=spam_path)
tar_bz2_file.close()
# fetch_spam_data()
# ------------加载数据集------------
HAM_DIR = os.path.join(SPAM_PATH, "easy_ham")
SPAM_DIR = os.path.join(SPAM_PATH, "spam")
ham_filenames = [name for name in sorted(os.listdir(HAM_DIR)) if len(name) > 20]
spam_filenames = [name for name in sorted(os.listdir(SPAM_DIR)) if len(name) > 20]
# ------------解析邮件------------
import email
import email.parser
import email.policy
def load_email(is_spam, filename, spam_path=SPAM_PATH):
directory = "spam" if is_spam else "easy_ham"
with open(os.path.join(spam_path, directory, filename), "rb") as f:
return email.parser.BytesParser(policy=email.policy.default).parse(f)
ham_emails = [load_email(is_spam=False, filename=name) for name in ham_filenames]
spam_emails = [load_email(is_spam=True, filename=name) for name in spam_filenames]
# ------------分析电子邮件结构------------
def get_email_structure(email):
if isinstance(email, str):
return email
payload = email.get_payload()
if isinstance(payload, list):
return "multipart({})".format(", ".join([
get_email_structure(sub_email)
for sub_email in payload
]))
else:
return email.get_content_type()
from collections import Counter
def structures_counter(emails):
structures = Counter()
for email in emails:
structure = get_email_structure(email)
structures[structure] += 1
return structures
# print(structures_counter(ham_emails).most_common())
# print(structures_counter(spam_emails).most_common())
# 正常电子邮件更多的是纯文本,而垃圾邮件有相当多的HTML。
# 此外,相当多的正常是用PGP签名的,而垃圾邮件是没有的。
# 简而言之,电子邮件结构似乎是有用的信息。
# ------------切分数据集------------
import numpy as np
from sklearn.model_selection import train_test_split
X = np.array(ham_emails + spam_emails, dtype=object)
y = np.array([0] * len(ham_emails) + [1] * len(spam_emails))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ------------处理邮件格式------------
# 使用BeautifulSoup或正则表达式,下面使用后者
import re
from html import unescape
def html_to_plain_text(html): # 将html格式的邮件处理为文本格式
text = re.sub('<head.*?>.*?</head>', '', html, flags=re.M | re.S | re.I)
text = re.sub('<as.*?>', ' HYPERLINK ', text, flags=re.M | re.S | re.I)
text = re.sub('<.*?>', '', text, flags=re.M | re.S)
text = re.sub(r'(s*n)+', 'n', text, flags=re.M | re.S)
return unescape(text)
def email_to_text(email): # 定义一个无论何种格式email输入都输出文本格式的函数
html = None
for part in email.walk():
ctype = part.get_content_type()
if not ctype in ("text/plain", "text/html"):
continue
try:
content = part.get_content()
except:
content = str(part.get_payload())
if ctype == "text/plain":
return content
else:
html = content
if html:
return html_to_plain_text(html)
# ------------将派生词转化为词干------------
try:
import nltk
stemmer = nltk.PorterStemmer()
for word in ("Computations", "Computation", "Computing", "Computed", "Compute", "Compulsive"):
print(word, "=>", stemmer.stem(word))
except ImportError:
print("缺失NLTK模块")
stemmer = None
# ------------替换URL------------
try:
import urlextract
url_extractor = urlextract.URLExtract()
print(url_extractor.find_urls("是否能识别 github.com 和 https://youtu.be/7Pq-S557XQU?t=3m32s"))
except ImportError:
print("缺失urlextract模块")
url_extractor = None
# ------------定义转换器------------
from sklearn.base import BaseEstimator, TransformerMixin
from scipy.sparse import csr_matrix
# 转换器一:单词计数器
class EmailToWordCounterTransformer(BaseEstimator, TransformerMixin):
def __init__(self, strip_headers=True, lower_case=True, remove_punctuation=True, replace_url=True,
replace_number=True, stemming=True):
self.strip_headers = strip_headers
self.lower_case = lower_case
self.remove_punctuation = remove_punctuation
self.replace_url = replace_url
self.replace_number = replace_number
self.stemming = stemming
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
X_transformed = []
for email in X:
text = email_to_text(email) or ""
if self.lower_case:
text = text.lower()
if self.replace_url and url_extractor is not None:
urls = list(set(url_extractor.find_urls(text)))
urls.sort(key=lambda url: len(url), reverse=True)
for url in urls:
text = text.replace(url, "URL ")
if self.replace_number:
text = re.sub(r'd+(?:.d*)?(?:[eE][+-]?d+)?', 'NUMBER', text)
if self.remove_punctuation:
text = re.sub(r'W+', ' ', text, flags=re.M)
word_counts = Counter()
if self.stemming and stemmer is not None:
stemed_word_counts = Counter()
for word, count in word_counts.items():
stemed_word = stemmer.stem(word)
stemed_word_counts[stemed_word] += count
word_counts = stemed_word_counts
X_transformed.append(word_counts)
return np.array(X_transformed)
# 转换器二:单机计数器转向量
class WordCounterToVectorTransformer(BaseEstimator, TransformerMixin):
def __init__(self, vocabulary_size=1000):
self.vocabulary_size = vocabulary_size
def fit(self, X, y=None):
total_count = Counter()
for word_count in X:
for word, count in word_count.items():
total_count[word] += min(count, 10)
most_common = total_count.most_common()[:self.vocabulary_size]
self.vocabulary_ = {word: index + 1 for index, (word, count) in enumerate(most_common)}
return self
def transform(self, X, y=None):
rows = []
cols = []
data = []
for row, word_count in enumerate(X):
for word, count in word_count.items():
rows.append(row)
cols.append(self.vocabulary_.get(word, 0))
data.append(count)
return csr_matrix((data, (rows, cols)), shape=(len(X), self.vocabulary_size+1))
# ------------训练分类器------------
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
preprocess_line = Pipeline([
("email_to_wordcount", EmailToWordCounterTransformer()),
("wordcount_to_vector", WordCounterToVectorTransformer())
])
X_train_transformed = preprocess_line.fit_transform(X_train)
log_clf = LogisticRegression(solver="lbfgs", max_iter=1000, random_state=42)
from sklearn.metrics import precision_score, recall_score
X_test_transformed = preprocess_line.transform(X_test)
log_clf = LogisticRegression(solver="lbfgs", max_iter=1000, random_state=42)
log_clf.fit(X_train_transformed, y_train)
y_pred = log_clf.predict(X_test_transformed)
print("精确度: {:.2f}%".format(100 * precision_score(y_test, y_pred)))
print("召回率: {:.2f}%".format(100 * recall_score(y_test, y_pred)))
最后
以上就是拉长西牛最近收集整理的关于机器学习实战第三章课后练习答案的全部内容,更多相关机器学习实战第三章课后练习答案内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复