1.使用jieba库 对中文文本进行分词
2.使用字典表达词频
(与hamlet案例相似)
import jieba
txt = open("threekingdoms.txt","r",encoding="utf-8").read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0)+1
items = list(counts.items())
items.sort(key = lambda y:y[1],reverse = True)
for i in range(15):
word , count = items[i]
print("{}{}".format(word,count))
但是结果…
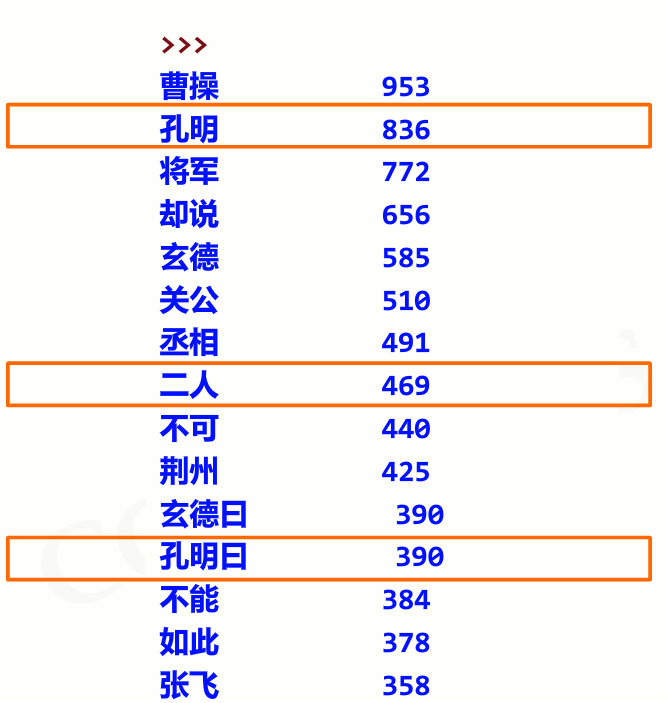
优化–>扩展程序

设置额外的库对非人名词汇进行删除(不断尝试优化),对统一含义名称进行统一
import jieba
txt = open("threekingdoms.txt","r",encoding="utf-8").read()
words = jieba.lcut(txt)
excludes = {"将军","却说","荆州","二人","不可","不能","如何","如此",
"主公","商议","军士","左右","引兵","于是","今日","军马",
"次日","天下","东吴","大喜"}
counts = {}
for word in words:
if len(word) == 1:
continue
elif word =="诸葛亮" or word =="孔明曰":
rword = "孔明"
elif word =="关公" or word =="云长":
rword = "关羽"
elif word =="玄德" or word =="玄德曰" :
rword = "刘备"
elif word =="孟德" or word =="丞相":
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword,0)+1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key = lambda y:y[1],reverse = True)
for i in range(8):
word , count = items[i]
print("{}{}".format(word,count))

最后
以上就是纯情外套最近收集整理的关于三国演义人物出场顺序统计(文本词频统计)的全部内容,更多相关三国演义人物出场顺序统计(文本词频统计)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复