在机器学习过程中,离不开大量的数据的训练和测试,而第三方库中所携带的数据库数量又是有限,当我们需要使用自己的数据时,如何将数据从外部读入,并将其转化为训练数据和测试数据?
本文将介绍一种数据读入及转化方式,本文以csv格式的文件为数据集作为例子进行读取测试。iris.csv数据集
(ps,若数据集需要积分,百度云链接)
首先看看iris.csv数据集长什么样子
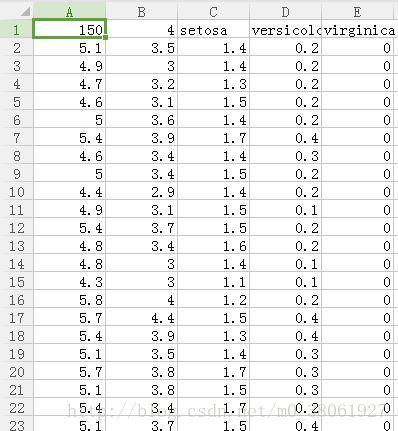
其为150*4的数据集,共150个样本,4个特征,最后一列为所属类别,现在我将取第一列和第三列的特征,作为训练样本。
实现:
import numpy as np
#open the file and read the data
path="E:pythonasklearniris.csv" #文件所在路径
f=open(path,'r',encoding='utf-8')
traindata=[] #存放训练数据
label=[] #存放测试数据
for line in f:
thisline=line.split(",")
traindata.append([thisline[0],thisline[3]]) #train sets
label.append(thisline[4].replace("n","")) #target sets至此得到了初始化的数据集,list类型

可以看出此时的数据存在几个问题:
1.数据比较乱,不方便观察
2.把开头索引部分也包括进去了,影响数据
3.目前数据是字符型,要将其转化成浮点型才能进行数据的下一步操作
面对这些问题,解决办法如下
1.首先去除无关部分索引 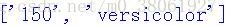
2.将列表转化成阵列
3.将阵列中的元素有字符型转化成浮点型
代码实现
traindata=traindata[ 1: ][:] #去除无关行数据
X=np.array(traindata) #将列表转化成阵列
n_samples=X.shape[0] #样本行数
n_features=X.shape[1] #样本列数
P=np.zeros((n_samples,n_features),np.float32)#存放数据
for i in range(n_samples):
for j in range(n_features):
P[i][j]=float(X[i][j]) #转化成float类型运行结果如下:
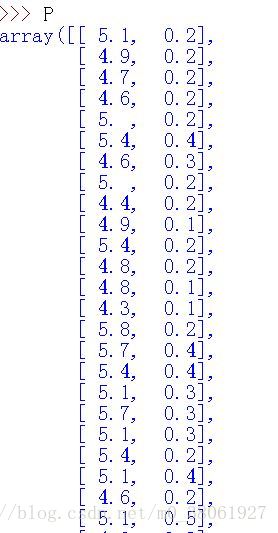
此时看起来就要舒服很多!
贴上源代码:
import numpy as np
path="E:pythonasklearniris.csv"
f=open(path , "r" , encoding="utf-8")
traindata=[]
label=[]
for line in f:
thisline=line.split(",")
traindata.append([thisline[0],thisline[3]])
label.append(thisline[4].replace("n",""))
traindata=traindata[1:][:]
label=label[1:]
X=np.array(traindata)
Y=np.array(label)
#build up the trainset
n_samples=X.shape[0]
n_features=X.shape[1]
P=np.zeros((n_samples,n_features),np.float)
for i in range(n_samples):
for j in range(n_features):
P[i][j] = round(float(X[i][j]),2)
print("trainset:" ,P)
#build up the targetset
Z=np.zeros((n_samples,1))
for i in range(150):
Z[i]=int(Y[i])
print("------------------------------------")
print("targetset:",Z)
以上便是关于数据读取的一点经验总结,欢迎大家一起交流讨论!
最后
以上就是畅快百褶裙最近收集整理的关于python中从外部读入数据并进行相应转换的全部内容,更多相关python中从外部读入数据并进行相应转换内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复