一、瞎扯
这是我2019年写的第一篇博客,开篇说点题外话,翻了一下博客的记录,上一遍新闻自动摘要生成(一)的博客还是去年7月写的,这大半年的时间里,忙着秋招,忙着找工作,忙着实习,忙着完成毕业设计,以及忙着完成毕业论文,月初提交了毕业论文,也总算有时间可以继续书写博客。记得也是在CSDN上结识的一位师姐说的很对,“书写是对思维的缓存”。写博客不仅是对自己学习过程的一些记录,而且在知识输出的书写过程中,也更加深了自己对于知识的熟悉和掌握程度。年初也给自己定下了写20篇博客的计划,虽然目标看似艰巨,但希望自己能够努力做到极致。
二、回顾
新闻自动摘要生成这个系列的博客,我暂时准备分为四篇来写,其中前两篇介绍抽取式摘要生成的两种算法:MMR和TextRank,第三篇介绍偏向工程实现的两种方法,最后介绍一下seq2seq + Attention Based Model的方法。
这里是第一篇:自动摘要生成(一):最大边界相关算法(MMR)
由于第一篇文章写于半年之前,距今年代久远,而在这半年之中我对抽取式和生成式的摘要生成方法又有了不同的了解和认识,加之第一篇文章中欠缺了许多对摘要生成算法的系统性概述,所以就在这里补上吧,以后在写博客时候也会系统性的根据计划来写,努力避免这种“事后回头擦屁股”的情况发生。
言归正传,为大家重新介绍一下文本摘要算法。
现阶段的文本摘要算法,主要分为两个大致的方向,分别为:抽取式和生成式。
抽取式摘要
抽取式摘要,是将文章中的每一个句子看作一个最小单位,从整篇文章中选取出个能够表达整个文章主题思想的句子,将其作为整个文章的摘要。
抽取式摘要实现起来较为简单,并且由于组成摘要的句子都是从原文章中选取出来的,所以句子的可读性就有了保障。抽取式摘要生成算法要解决的问题是选取哪些个句子来表达文章主题,所以它的本质其实是一个优化组合的问题。
生成式摘要
生成式摘要,可以理解为我们初中时候,语文课后作业中经常要求的首先阅读整个文章,再用自己的语言来对文章中的信息和内容进行总结的过程。由于生成式摘要中的语言语句都是是由自己来组织的(语言模型输出的),所以整个摘要的可读性是一个大问题,换句话说就是训练出的语言模型能不能说人话。生成式摘要首先需要提取文章中所包含的信息,再将这些信息用训练语言模型来输出,所以它的的本质是一个编解码问题。
自然语言处理中基本所有的任务都可分为四类:
分类任务:如文本分类,情感分类。
标注类任务:如实体命名识别(NER),词性标注,句法分析。
文本匹配类任务:如问答系统,文本搜索,推荐召回。
文本生成类任务:如机器翻译,Image Caption。
抽取式摘要属于文本匹配任务。
生成式摘要属于文本生成类任务。
三、TextRank算法
好了,终于到了我们今天要讲的主题,TextRank算法。首先简单的介绍一下TextRank算法,TextRank算法的前身是PageRank算法,PageRank算法是由Google在20世纪90年代提出的,用于进行网页搜索结果排序的算法。后来对PageRank的公式稍加改动,衍生出了TextRank算法。
从这里我们也可以看出用于抽取式摘要算法的MMR和TextRank算法都是有搜索算法改变而来的,而搜索算法本质上解决的就是根据搜索内容来排序的问题,这也就体现出了为什么抽取式摘要算法是属于文本匹配类任务的一个优化组合问题了。
好,下面我们就先来看看PageRank算法是如何来排序网页的。
PageRank
首先,现Po出公式来瞧瞧。
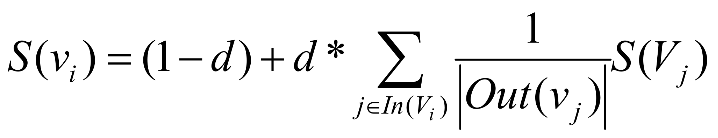
:每一个网页的分数
:阻尼系数,作用是确保每一个网页都有分数
:推荐网页
的页面
:网页
推荐的页面
:网页
推荐的页面的数量
其中网页的推荐例如网页A推荐了网页B的意思是:A网页中有B网页的链接,可以通过A网页到达B网页。
在计算每个页面的分数时,首先需要根据网页之间互相推荐的关系,构造出一个如下的邻接表出来。
| In/Out | A | B | C | D |
| A | 0 | 0 | 3 | 0 |
| B | 4 | 0 | 3 | 1 |
| C | 4 | 1 | 0 | 8 |
| D | 1 | 4 | 6 | 0 |
表中表明了所有网页之间的推荐关系。
接下来给所有网页的分数赋一个初值,再使用PageRank公式来计算每个页面的分数,对其依次进行更新迭代,如此反复计算,直到所有页面的分数值收敛趋于稳定,就得到了所有页面最终的分数。
最后根据分数的高低,将所有网页按照分数从高到低排列,得到的顺序就是最后输出的网页搜索排序顺序了。
TextRank
介绍了完了PageRank算法,现在来看看TextRank算法是如何对前者进行改进的。
PageRank算法中的最小单位为每一个网页,而TextRank中的最小单位为每一个句子。因此,TextRank首先需要解决的一个问题就是,如何来表达句子间的“相互推荐”?
TextRank使用的方法是:用句子间的相似度来双向表示它们的推荐性。
而对于如何计算句子的相似度,TextRank使用的方法是计算共现词的出现次数:
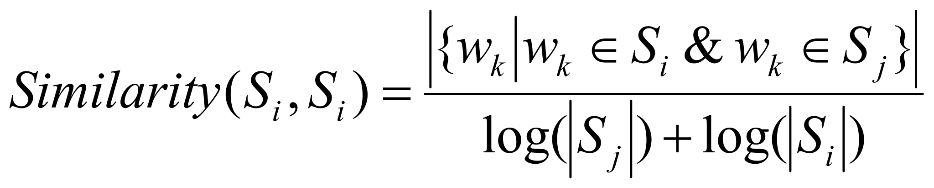
分母部分的对数函数用于降低句子长度过长,单词过多对相似度计算所带来的影响。
当然,随着word2vec和Glove等词语分布式的表示方法的出现,句子相似度也可以用句子中单词的词向量累加求平均,再通过计算余弦相似度的方法来实现。
接下来就是TextRank的公式了:
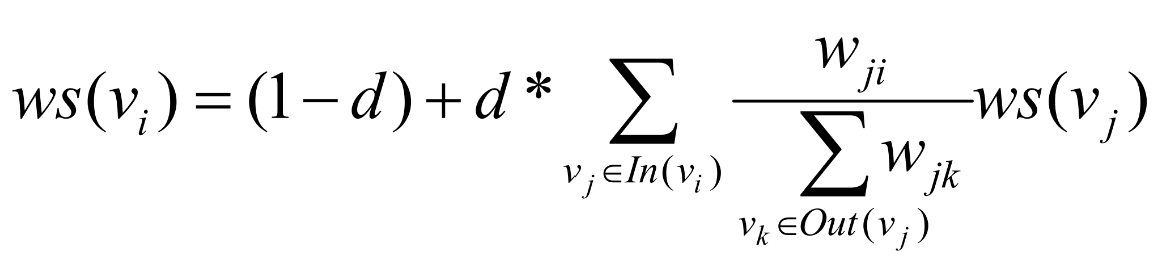
TextRank的公式长得跟PageRank非常像。其中:
:句子
的分数
:阻尼系数,作用是确保每一个句子都有分数
,
:除了
以外的句子
TextRank的计算方式也和PageRank相同,首先根据句子间的相似度,构造一个如下的邻接表:
| Similarity | A | B | C | D |
| A | None | 0.8 | 0.3 | 0.7 |
| B | 0.8 | None | 0.3 | 0.1 |
| C | 0.3 | 0.3 | None | 0.8 |
| D | 0.7 | 0.1 | 0.8 | None |
由于句子之间的相似度相同的,所以该邻接矩阵是关于主对角线对称的。
接下来给所有句子的分数赋一个初值,再使用TextRank公式来计算每个句子的分数,对其依次进行更新迭代,如此反复计算,直到所有句子的分数值收敛趋于稳定,就得到了所有句子最终的分数。
最后根据分数的高低,将所有句子按照分数从高到低排列,若初始设定的摘要中句子个数为,则前
个句子便为最终被选为摘要的句子。
四、代码实现
import math
from itertools import product,count
from string import punctuation
from heapq import nlargest
import jieba
import re
def calculate_similarity(sen1,sen2):
counter = 0
for word in sen1:
if word in sen2:
counter += 1
return counter / (math.log(len(sen1)) + math.log(len(sen2)))
def create_graph(word_sent):
num = len(word_sent)
board = [[0.0 for _ in range(num)] for _ in range(num)]
for i , j in product(range(num) , repeat=2):
if i != j:
board[i][j] = calculate_similarity(word_sent[i] , word_sent[j])
return board
"""
输入相似度邻接矩阵
返回各个句子的分数
"""
def weighted_pagerank(weight_graph):
# 把初始的分数值设置为0.5
scores = [0.5 for _ in range(len(weight_graph))]
old_scores = [0.0 for _ in range(len(weight_graph))]
# 开始迭代
while different(scores, old_scores):
for i in range(len(weight_graph)):
old_scores[i] = scores[i]
for i in range(len(weight_graph)):
scores[i] = calculate_score(weight_graph, scores, i)
return scores
"""
判断前后分数有没有变化
这里认为前后差距小于0.0001
分数就趋于稳定
"""
def different(scores, old_scores):
flag = False
for i in range(len(scores)):
if math.fabs(scores[i] - old_scores[i]) >= 0.0001:
flag = True
break
return flag
"""
根据公式求出指定句子的分数
"""
def calculate_score(weight_graph, scores, i):
length = len(weight_graph)
d = 0.85
added_score = 0.0
for j in range(length):
fraction = 0.0
denominator = 0.0
# 先计算分子
fraction = weight_graph[j][i] * scores[j]
# 计算分母
for k in range(length):
denominator += weight_graph[j][k]
added_score += fraction / denominator
# 算出最终的分数
weighted_score = (1 - d) + d * added_score
return weighted_score
def Summarize(text, n):
# 首先分出句子
#sents = sent_tokenize(text)
for line in text:
sents = re.split('[。?!]',line)[:-1]
# 然后分出单词
# word_sent是一个二维的列表
# word_sent[i]代表的是第i句
# word_sent[i][j]代表的是
# 第i句中的第j个单词
word_sent = [list(jieba.cut(s)) for s in sents]
print(word_sent)
# 把停用词去除
#for i in range(len(word_sent)):
#for word in word_sent[i]:
#if word in stopwords:
#word_sent[i].remove(word)
similarity_graph = create_graph(word_sent)
scores = weighted_pagerank(similarity_graph)
sent_selected = nlargest(n, zip(scores, count()))
sent_index = []
for i in range(n):
sent_index.append(sent_selected[i][1])
return [sents[i] for i in sent_index]
texts = ["7月11日,连续强降雨,让四川登上了中央气象台“头条”,涪江绵阳段水位迅速上涨,洪水一度漫过了宝成铁路涪江大桥桥墩基座,超过封锁水位。洪水在即,中国铁路成都局集团公司紧急调集两列重载货物列车,一前一后开上涪江大桥,每一列货车重量约四千吨,用“重车压梁”的方式,增强桥梁自重,抵御汹涌的洪水。从11日凌晨开始,四川境内成都、绵阳、广元等地连续强降雨,而四川北向出川大动脉—宝成铁路,便主要途径成绵广这一区域。连续的强降雨天气下,绵阳市境内的涪江水位迅速上涨,一度危及到了宝成铁路涪江大桥的安全,上午10时,水位已经超过了涪江大桥上、下行大桥的封锁水位。记者从中国铁路成都局集团公司绵阳工务段了解到,上行线涪江大桥,全长393米,建成于1953年;下行线涪江大桥,全长438米,建成于1995年。“涪江大桥上游有一个水电站,由于洪水太大,水电站已无法发挥调节水位的作用。”情况紧急,铁路部门决定采用“重车压梁”的方式,增强桥梁自重,提高洪峰对桥墩冲刷时的梁体稳定性。简单来说,就是将重量大的货物列车开上涪江大桥,用货车的自重,帮助桥梁抵御汹涌的洪水。恰好,绵阳工务段近期正在进行线路大修,铁路专用的卸砟车,正好停放在绵阳附近。迎着汹涌的洪水,两列重载货车驶向宝成铁路涪江大桥。上午10时30分,第一列46052次货车,从绵阳北站开出进入上行涪江桥。上午11时15分,第二列22001次货车,从皂角铺站进入下行涪江桥。这是两列超过45节编组的重载货物列车,业内称铁路专用卸砟车,俗称“老K车”,车厢里装载的均为铁路道砟,每辆车的砟石的重量在70吨左右。记者从绵阳工务段了解到,货车里满载的砟石、加上一列货车的自重,两列“压桥”的货运列车,每一列的重量超过四千吨。“采用重车压梁的方式来应对水害,在平时的抢险中很少用到。”据了解,在绵阳工务段,上一次采用重车压梁,至少已经是二十年前的事。下午4时许,经铁路部门观测,洪峰过后,涪江水位开始下降,目前已经低于桥梁封锁水位。从下午4点37分开始,两列火车开始撤离涪江大桥。在桥上停留约6个小时后,两列重载货物列车成功完成了“保桥任务”,宝成铁路涪江大桥平安了!"]
print('nSummary:n')
for sentence in Summarize(texts,3):
print(sentence)
print('=============================================================')
print('nOriginal Passages:n')效果
最后我们还是用之前的两篇文章来看看TextRank抽取摘要的效果吧。
NEW1:
title:
20年来首次!四千吨级重载货车压桥抵御洪峰,宝成铁路大桥已平安。
context:
7月11日,连续强降雨,让四川登上了中央气象台“头条”,涪江绵阳段水位迅速上涨,洪水一度漫过了宝成铁路涪江大桥桥墩基座,超过封锁水位。洪水在即,中国铁路成都局集团公司紧急调集两列重载货物列车,一前一后开上涪江大桥,每一列货车重量约四千吨,用“重车压梁”的方式,增强桥梁自重,抵御汹涌的洪水。从11日凌晨开始,四川境内成都、绵阳、广元等地连续强降雨,而四川北向出川大动脉—宝成铁路,便主要途径成绵广这一区域。连续的强降雨天气下,绵阳市境内的涪江水位迅速上涨,一度危及到了宝成铁路涪江大桥的安全,上午10时,水位已经超过了涪江大桥上、下行大桥的封锁水位。记者从中国铁路成都局集团公司绵阳工务段了解到,上行线涪江大桥,全长393米,建成于1953年;下行线涪江大桥,全长438米,建成于1995年。“涪江大桥上游有一个水电站,由于洪水太大,水电站已无法发挥调节水位的作用。”情况紧急,铁路部门决定采用“重车压梁”的方式,增强桥梁自重,提高洪峰对桥墩冲刷时的梁体稳定性。简单来说,就是将重量大的货物列车开上涪江大桥,用货车的自重,帮助桥梁抵御汹涌的洪水。恰好,绵阳工务段近期正在进行线路大修,铁路专用的卸砟车,正好停放在绵阳附近。迎着汹涌的洪水,两列重载货车驶向宝成铁路涪江大桥。上午10时30分,第一列46052次货车,从绵阳北站开出进入上行涪江桥。上午11时15分,第二列22001次货车,从皂角铺站进入下行涪江桥。这是两列超过45节编组的重载货物列车,业内称铁路专用卸砟车,俗称“老K车”,车厢里装载的均为铁路道砟,每辆车的砟石的重量在70吨左右。记者从绵阳工务段了解到,货车里满载的砟石、加上一列货车的自重,两列“压桥”的货运列车,每一列的重量超过四千吨。“采用重车压梁的方式来应对水害,在平时的抢险中很少用到。”据了解,在绵阳工务段,上一次采用重车压梁,至少已经是二十年前的事。下午4时许,经铁路部门观测,洪峰过后,涪江水位开始下降,目前已经低于桥梁封锁水位。从下午4点37分开始,两列火车开始撤离涪江大桥。在桥上停留约6个小时后,两列重载货物列车成功完成了“保桥任务”,宝成铁路涪江大桥平安了!
abstract:
连续的强降雨天气下,绵阳市境内的涪江水位迅速上涨,一度危及到了宝成铁路涪江大桥的安全,上午10时,水位已经超过了涪江大桥上、下行大桥的封锁水位
洪水在即,中国铁路成都局集团公司紧急调集两列重载货物列车,一前一后开上涪江大桥,每一列货车重量约四千吨,用“重车压梁”的方式,增强桥梁自重,抵御汹涌的洪水
简单来说,就是将重量大的货物列车开上涪江大桥,用货车的自重,帮助桥梁抵御汹涌的洪水
NEW2:
title:
姆巴佩夺冠后表忠心:留在巴黎 哪儿也不去!
context:
伴随着世界杯的落幕,俱乐部联赛筹备工作又成为主流,转会市场必然也会在世界杯的带动下风起云涌,不过对于在本届赛事上大放异彩的姆巴佩而言,大巴黎可以吃一颗定心丸,世界杯最佳新秀已经亲自表态:留在巴黎哪里也不去。在接受外媒采访时,姆巴佩表达了继续为巴黎效忠的决心。“我会留在巴黎,和他们一起继续我的路途,我的职业生涯不过刚刚开始”,姆巴佩说道。事实上,在巴黎这座俱乐部,充满了内部的你争我夺。上赛季,卡瓦尼和内马尔因为点球事件引发轩然大波,而内马尔联合阿尔维斯给姆巴佩起“忍者神龟”的绰号也让法国金童十分不爽,为此,姆巴佩的母亲还站出来替儿子解围。而早在二月份,一场与图卢兹的比赛,内马尔也因为传球问题赛后和姆巴佩产生口角。由此可见,巴黎内部虽然大牌云集,但是气氛并不和睦。内马尔离开球队的心思早就由来已久,而姆巴佩也常常与其它俱乐部联系在一起,在躲避过欧足联财政公平法案之后,巴黎正在为全力留下二人而不遗余力。好在姆巴佩已经下定决心,这对巴黎高层而言,也算是任务完成了一半。本届世界杯上,姆巴佩星光熠熠,长江后浪推前浪,大有将C罗、梅西压在脚下的趋势,他两次追赶贝利,一次是在1/8决赛完成梅开二度,另一次是在世界杯决赛中完成锁定胜局的一球,成为不满20岁球员的第二人。另外他在本届赛事中打进了4粒入球,和格列兹曼并列全队第一。而对巴黎而言,他们成功的标准只有一条:欧冠。而留下姆巴佩,可以说在争夺冠军的路上有了仰仗,卡瓦尼在本届世界杯同样表现不错,内马尔虽然内心波澜,但是之前皇马官方已经辟谣没有追求巴西天王,三人留守再度重来,剩下的就是图赫尔的技术战术与更衣室的威望,对图赫尔而言,战术板固然重要,但是德尚已经为他提供了更加成功的范本,像团结法国队一样去团结巴黎圣日耳曼,或许这才是巴黎取胜的钥匙。
abstract:
在接受外媒采访时,姆巴佩表达了继续为巴黎效忠的决心。
而留下姆巴佩,可以说在争夺冠军的路上有了仰仗,卡瓦尼在本届世界杯同样表现不错,内马尔虽然内心波澜,但是之前皇马官方已经辟谣没有追求巴西天王,三人留守再度重来,剩下的就是图赫尔的技术战术与更衣室的威望,对图赫尔而言,战术板固然重要,但是德尚已经为他提供了更加成功的范本,像团结法国队一样去团结巴黎圣日耳曼,或许这才是巴黎取胜的钥匙。
内马尔离开球队的心思早就由来已久,而姆巴佩也常常与其它俱乐部联系在一起,在躲避过欧足联财政公平法案之后,巴黎正在为全力留下二人而不遗余力。
五、总结一下
将以上由TextRank抽取出的摘要与新闻自动摘要生成(一):最大边界相关算法(MMR)中由MMR算法抽取的摘要进行对比。
可以看出,TextRank抽取出的摘要更加贴近全文的主旨或中心思想,从另一个方面来说,也就是摘要更加单调。而MMR算法由于超参的存在,可以人工对摘要的多样性进行控制,抽取出的摘要的多样性更好,内容更加丰富。
最后
以上就是光亮火最近收集整理的关于自动摘要生成(二):由PageRank转变而来的TextRank算法的全部内容,更多相关自动摘要生成(二):由PageRank转变而来内容请搜索靠谱客的其他文章。








发表评论 取消回复