机器学习实践:提取文章摘要
1、实验描述
-
本实验利用自然语言处理提取新闻摘要:“关键字提取”算法和TextRank算法完成新闻摘要提取,旨在理解这两种算法的摘要原理和代码逻辑,从而掌握能够对自然语言文件进行处理的能力
-
实验时长:90分钟
-
主要步骤:
- 关键字摘要原理
- 关键词摘要代码编写
- TextRank摘要算法原理
- TextRank摘要代码编写
2、实验环境
-
虚拟机数量:1
-
系统版本:CentOS 7.5
-
Python版本:Python 3.5
3、相关技能
-
Python基础
-
“关键字提取”原理
-
TextRank原理
4、相关知识点
-
Pygame的基础操作
-
“关键字提取”算法
-
TextRank算法
5、效果图
- 脚本运行效果如下图

- 第二个脚本运行的效果如下图

6、实验步骤
6.1利用关键词法完成新闻摘要的提取
6.1.1我们在浏览新闻时一般都能很快的找到新闻内容的关键字,从而快速确定这一则新闻的主要内容是什么,本节实验我们就利用这一方法提取文本中的关键字,并根据关键字来完成新闻摘要的提取
6.2数据准备
6.2.1解压experiment/nltk目录下的nltk_data.tar.gz文件到/home/zkpk目录下
[zkpk@master ~]$ cd experiment/nltk
[zkpk@master nltk]$ tar -zxvf nltk_data.tar.gz -C ~/
[zkpk@master nltk]$ cd
6.3NLTK简介:NLTK是一个开源的项目,包含:Python模块,数据集和教程,用于NLP的研究和开发
6.4打开Linux终端,进入虚拟环境zkbc中(该环境在前面的实验中已经安装,若没有安装则按照前面的实验安装即可),安装NLTK;安装过程中,询问Proceed([y]/n)?,输入y回车,让安装继续下去
[zkpk@master ~]$ source activate zkbc
(zkbc)[zkpk@master ~]$ conda install nltk
6.5在/home/zkpk中用vim创建NewsSummary1.py文件
(zkbc)[zkpk@master ~]$ vim NewsSummary1.py
6.6在Python文件中编写我们的实验代码
6.6.1导入实验所需的相关jar包
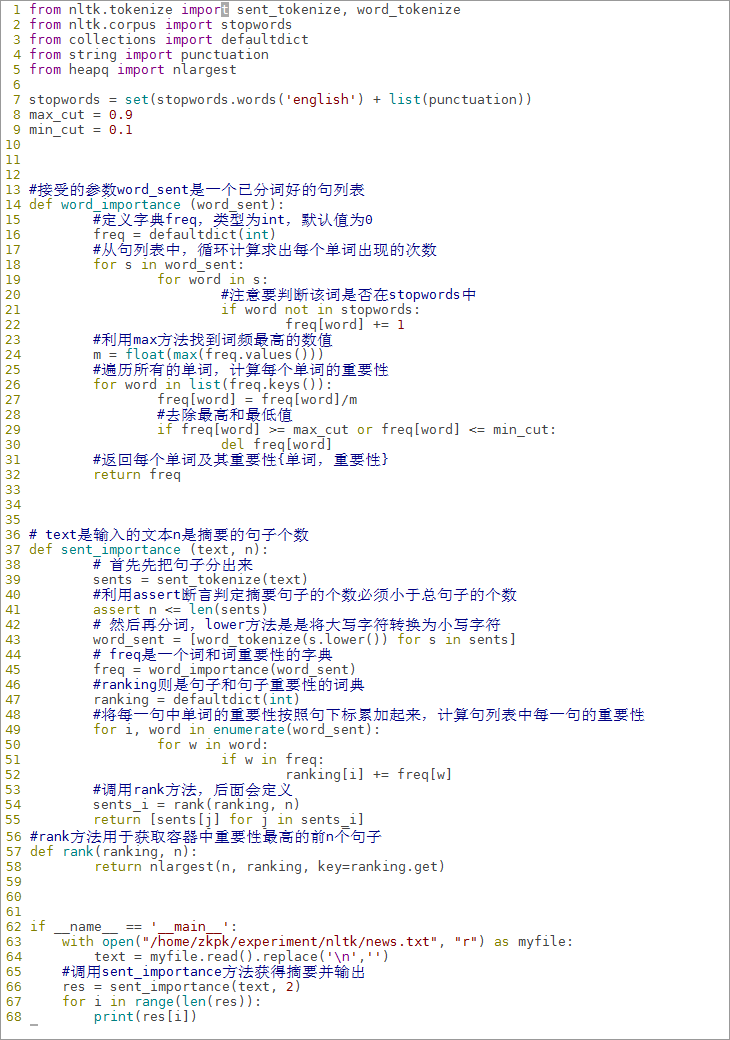
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
from collections import defaultdict
from string import punctuation
from heapq import nlargest
6.6.1.1nltk.tokenize 是NLTK提供的分词工具包。所谓的分词 (tokenize) 实际就是把段落分成句子,把句子分成一个个单词的过程。我们导入的 sent_tokenize() 函数对应的是分段为句。 word_tokenize()函数对应的是分句为词。
6.6.1.2stopwords 是一个列表,包含了英文中那些频繁出现的词,如am, is, are。
6.6.1.3defaultdict 是一个带有默认值的字典容器。
6.6.1.4puctuation 是一个列表,包含了英文中的标点和符号。
6.6.1.5nlargest() 函数可以很快地求出一个容器中最大的n个数字。
6.6.2要想利用关键词进行文章摘要提取,首先我们要计算出每个单词在文章中的重要性,如何计算单词的重要性呢?我们可以找到出现次数最多的词的出现次数 m ,我们把每个词出现的次数 mi 除以 m ,就可以算出每个词的“重要性”了
6.6.3先定一些我们需要的常量
stopwords = set(stopwords.words('english') + list(punctuation))
max_cut = 0.9
min_cut = 0.1
6.6.3.1stopwords停用词集合是用来存放日常生活中会遇到的出现频率很高的词,如he, I, you, is等等,这种词汇是不应该算关键字,标点符号(punctuation)也不能被算作是关键字。
6.6.3.2max_cut 和min_cut类似于比赛打分中的去除最高分和最低分,因为极端情况是很有可能出现的,我们需要避免这种情况
6.6.4编写计算单词重要性的函数word_importance
#接受的参数word_sent是一个已分词好的句列表
def word_importance (word_sent):
#定义字典freq,类型为int,默认值为0
freq = defaultdict(int)
#从句列表中,循环计算求出每个单词出现的次数
for s in word_sent:
for word in s:
#注意要判断该词是否在stopwords中
if word not in stopwords:
freq[word] += 1
#利用max方法找到词频最高的数值
m = float(max(freq.values()))
#遍历所有的单词,计算每个单词的重要性
for word in list(freq.keys()):
freq[word] = freq[word]/m
#去除最高和最低值
if freq[word] >= max_cut or freq[word] <= min_cut:
del freq[word]
#返回每个单词及其重要性{单词,重要性}
return freq

6.6.5此时我们已经获得了每个单词(排除常见单词、异常频率的单词和标点符号)重要性,现在我们计算出每一个句子的重要性,直接将一句中所有单词的重要性相加即可得到这一句子的重要性
6.6.5.1编写计算所有句子重要性的函数sent_importance
# text是输入的文本n是摘要的句子个数
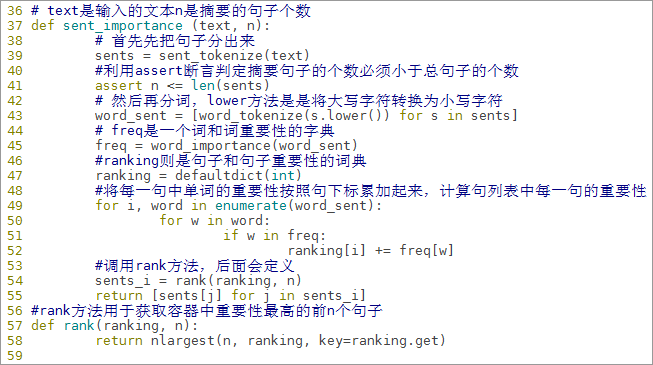
def sent_importance (text, n):
# 首先先把句子分出来
sents = sent_tokenize(text)
#利用assert断言判定摘要句子的个数必须小于总句子的个数
assert n <= len(sents)
# 然后再分词,lower方法是是将大写字符转换为小写字符
word_sent = [word_tokenize(s.lower()) for s in sents]
# freq是一个词和词重要性的字典
freq = word_importance(word_sent)
#ranking则是句子和句子重要性的词典
ranking = defaultdict(int)
#将每一句中单词的重要性按照句下标累加起来,计算句列表中每一句的重要性
for i, words in enumerate(word_sent):
for w in words:
if w in freq:
ranking[i] += freq[w]
#调用rank方法,后面会定义
sents_i = rank(ranking, n)
return [sents[j] for j in sents_i]
#rank方法用于获取容器中重要性最高的前n个句子
def rank(ranking, n):
return nlargest(n, ranking, key=ranking.get)
6.6.6编写main方法,main方法中打开/home/zkpk/experiment/nltk目录下的新闻样本news.txt用于测试摘要程序
if __name__ == '__main__':
with open("/home/zkpk/experiment/nltk/news.txt", "r") as myfile:
text = myfile.read().replace('n','')
#调用sent_importance方法获得摘要并输出
res = sent_importance(text, 2)
for i in range(len(res)):
print(res[i])

6.6.7main方法编写完成后,回到vim命令模式利用wq保存代码文件,回到/home/zkpk目录下运行程序,查看命令行结果
(zkbc)[zkpk@master ~]$ python NewsSummary1.py

6.6.8可以看到通过关键字重要性,我们获取到了两条摘要内容
6.7利用TextRank算法提取摘要
6.7.1TextRank是一种用来做关键词提取的算法,也可以用于提取短语和自动摘要。TextRank是基于PageRank的,而PageRank设计之初是用于Google的网页排名,PageRank通过互联网中的超链接关系来确定一个网页的排名。其公式为:
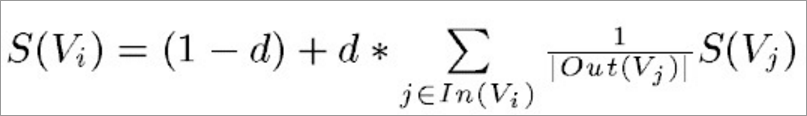
6.7.2PageRank公式中,Vi表示某个网页,Vj表示链接到Vi的网页(即Vi的入链),S(Vi)表示网页Vi的PageRank值,In(Vi)表示网页Vi的所有入链的集合,Out(Vj)表示网页Vj所有出链的集合,d表示阻尼系数用来确保每一个页面都至少有 (1-d) 的分数。可以看到每一个页面的分数 S(Vi) 都是依赖于别的页面的分数 S( Vj ) 的
6.7.3利用TextRank计算每个句子的分数(重要性),需要先计算每个句子之间的相似性,简单来说就是找到两个句子相同单词的个数m,再除以两个句子长度的常用对数的和,公式如下
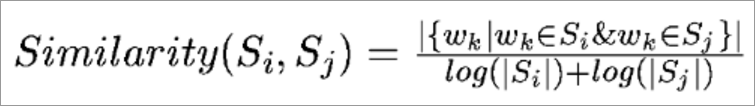
6.7.4TextRank是由PageRank改进而来,其公式有颇多相似之处,在利用上面得到的相似性计算出每一个句子的分数(重要性),这里给出TextRank的公式:
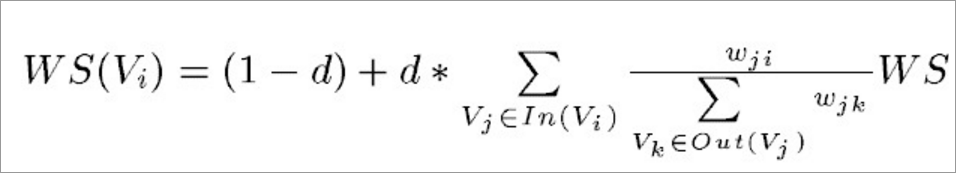
6.7.5可以看出,该公式仅仅比PageRank多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度,也就是相似度
6.7.6在本节实验中为了方便计算,我们定义每个句子的初始分数(重要性)也就是WS(Vi)为1,阻尼系数d为0.85,也就是说计算第一个句子的分数时,其他为计算过的句子初始分数都是1,如此迭代计算,直至所有句子的分数都不在改变时,就是每个句子的真实分数了
6.7.7这里只是对算法的简单介绍,详细算法内容请查看相关资料学习
6.8编写TextRank算法脚本文件
6.8.1在/home/zkpk/下用vim编辑器创建脚本文件NewsSummary2.py
(zkbc)[zkpk@master ~]$ vim /home/zkpk/NewsSummary2.py
6.8.2首先导入我们需要的包。基本和关键字提取实验中需要的包是一样的
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
import math
from itertools import product, count
from string import punctuation
from heapq import nlargest
6.8.3定义停用词集合stopwords排除常用单词和标点符号
stopwords = set(stopwords.words('english') + list(punctuation))
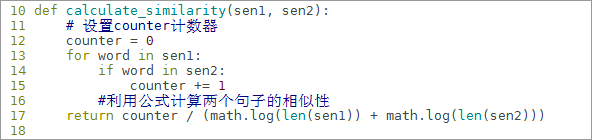
6.8.4定义计算相似性函数:这个函数接收两个句子,计算两个句子之间的相似性,计算公式为:
def calculate_similarity(sen1, sen2):
# 设置counter计数器
counter = 0
for word in sen1:
if word in sen2:
counter += 1
#利用公式计算两个句子的相似性
return counter / (math.log(len(sen1)) + math.log(len(sen2)))
6.8.5创建相似度邻接矩阵函数,该函数接收一个句列表参数
#传入句列表
def create_matrix (word_sent):
num = len(word_sent)
# 初始化一个num行和num列且每项默认为0.0的邻接矩阵
board = [[0.0 for _ in range(num)] for _ in range(num)]
#利用product生成repeat(生成序列重复次数)为2的笛卡尔积,并将笛卡尔积存储在对应的矩阵位置中
for i, j in product(range(num), repeat=2):
if i != j:
board[i][j] = calculate_similarity(word_sent[i], word_sent[j])
return board

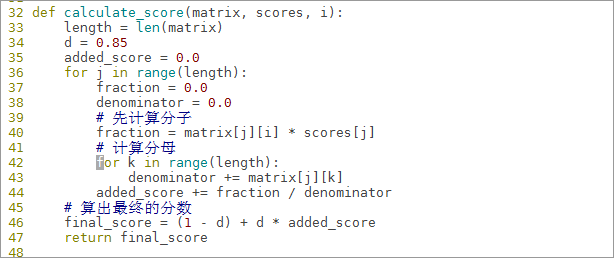
6.8.6定义计算分数函数calculate_score,根据公式求出指定句子的分数
def calculate_score(matrix, scores, i):
length = len(matrix)
d = 0.85
added_score = 0.0
for j in range(length):
fraction = 0.0
denominator = 0.0
# 先计算分子
fraction = matrix[j][i] * scores[j]
# 计算分母
for k in range(length):
denominator += matrix[j][k]
added_score += fraction / denominator
# 算出最终的分数
final_score = (1 - d) + d * added_score
return final_score
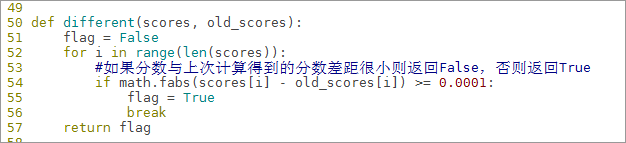
6.8.7定义different方法判断前后分数有没有变化,这里认为前后差距小于0.0001分数就趋于稳定
def different(scores, old_scores):
flag = False
for i in range(len(scores)):
#如果分数与上次计算得到的分数差距很小则返回False,否则返回True
if math.fabs(scores[i] - old_scores[i]) >= 0.0001:#fabs求绝对值
flag = True
break
return flag
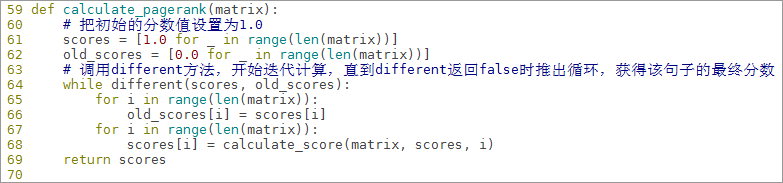
6.8.8定义函数calculate_pagerank得到所有句子最终分数的矩阵
def calculate_pagerank(matrix):
# 把初始的分数值设置为1.0
scores = [1.0 for _ in range(len(matrix))]
old_scores = [0.0 for _ in range(len(matrix))]
# 调用different方法,开始迭代计算,直到different返回false时推出循环,获得该句子的最终分数
while different(scores, old_scores):
for i in range(len(matrix)):
old_scores[i] = scores[i]
for i in range(len(matrix)):
scores[i] = calculate_score(matrix, scores, i)
return scores
6.8.9定义主要函数Function,传入句列表,计算并找出分数最高的两个句子
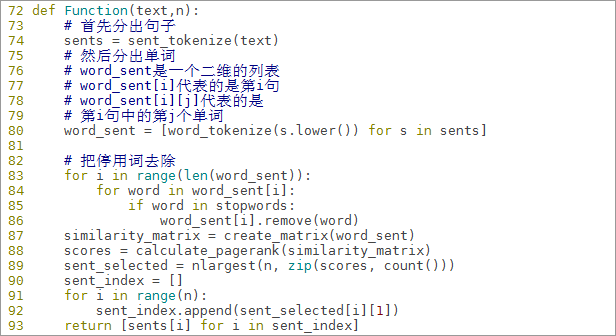
def Function(text,n):
# 首先分出句子
sents = sent_tokenize(text)
# 然后分出单词
# word_sent是一个二维的列表
# word_sent[i]代表的是第i句
# word_sent[i][j]代表的是第i句中的第j个单词
word_sent = [word_tokenize(s.lower()) for s in sents]
# 把停用词去除
for i in range(len(word_sent)):
for word in word_sent[i]:
if word in stopwords:
word_sent[i].remove(word)
similarity_matrix = create_matrix(word_sent)
scores = calculate_pagerank(similarity_matrix)
sent_selected = nlargest(n, zip(scores, count()))
sent_index = []
for i in range(n):
sent_index.append(sent_selected[i][1])
return [sents[i] for i in sent_index]
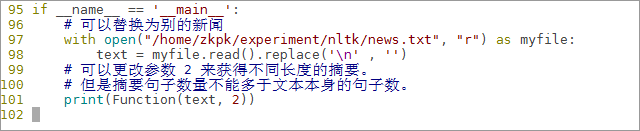
6.8.10编写main方法,打开/home/zkpk/experiment目录下的新闻样本news.txt用于测试摘要程序
if __name__ == '__main__':
# 可以替换为别的新闻
with open("/home/zkpk/experiment/nltk/news.txt", "r") as myfile:
text = myfile.read().replace('n' , '')
# 可以更改参数 2 来获得不同长度的摘要。
# 但是摘要句子数量不能多于文本本身的句子数。
print(Function(text, 2))
6.8.11代码编写完毕,vim编辑器回到命令模式利用:wq保存退出
6.8.12运行程序,在终端查看结果
(zkbc)[zkpk@master ~]$ python NewsSummary2.py

6.8.13可以看到TextRank算法对文本摘要的内容,与关键词提取新闻摘要的结果是不同的,也就是说不同算法最后计算出的句子的重要性是不一样的
7、参考答案
- 代码清单NewsSummary1.py
- 代码清单NewsSummary2.py

8、总结
本实验基于关键字算法和TextRank算法完成的新闻摘要实验,相比较而言,比较简单的关键字提取算法可能选出的摘要要更加贴切一些。通过本节实验的学习,我们应当理解了关键词摘要和TextRank算法摘要的原理,并且能够独立完成这两种摘要算法的编写,能够根据实际业务数据编写灵活的摘要算法代码。
最后
以上就是机灵纸鹤最近收集整理的关于机器学习实践:提取文章-6的全部内容,更多相关机器学习实践内容请搜索靠谱客的其他文章。








发表评论 取消回复