分享一下前一段时间公司需要做的文章自动摘要。
一.摘要方法
目前来说,文章摘要自动生成主要分为两种方法:生成式和抽取式。
生成式采用sequence2sequence+Attention的模型,采用Encoder-Decoder的结构,具体方法可以阅读这篇论文:https://arxiv.org/pdf/1509.00685.pdf
抽取式则是通过关键词筛选等方法,从原文中截取句子组成摘要,目前的方法有MMR,TextRank,LDA等。
起初尝试了生成式摘要,使用文章的标题作为样本标签,对模型进行训练,但是效果不是很好,生成的摘要中包含了标题中的关键字,但是无法组成正确的语序。所以最终决定采用抽取式来生成新闻摘要。
后续两种方法在这里:
自动摘要生成(二):由PageRank转变而来的TextRank算法
自动摘要生成(三):词向量相似度与有效词含量
二.具体算法
经过测试后,决定采用MMR,TextRank,文章标题相似度,TextRank+Embedding,全文词向量叠加Embedding相似度,这几种方法的加权组合,筛选出新闻的摘要。
本篇重点讲解MMR算法的理论和实现。
MMR
1.MMR原理
MMR是Maximal Marginal Releuance的缩写,中文为最大边界相关算法或最大边缘相关算法。
设计之初是用来计算Query语句与被搜索文档之间的相似度,从而对文档进行rank排序的算法。
公式在这:

当我们将MMR用于新闻摘要提取时,可以将Query看做是整篇文档,对公式稍作修改,变成下面这个样子:
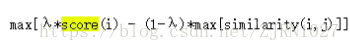
Sim(Q,di)变为了score(i),表示文章第i句的得分,得分即本句话与整个文章的相似度。中括号内第二项为当前句子i与已经成为候选摘要的句子j的相似度。lambda为需要调整的参数。
此处就很好的体现出了MMR算法的特点,就是注重抽取摘要内容的多样性,通过减去中括号内第二项,最小化选取摘要句子之间的相似性,使得生成的摘要多样化。
当然我们可以通过调节lambda参数来控制文章摘要的多样性:
----high lambda:Higher accuracy
---low lambda:Higher diversity
2.MMR实现
下面截取部分代码来说说MMR是怎么实现的。
首先是第一项score的计算
def calculateSimilarity(sentence, doc): # 根据句子和句子,句子和文档的余弦相似度
if doc == []:
return 0
vocab = {}
for word in sentence.split():
vocab[word] = 0 # 生成所在句子的单词字典,值为0
docInOneSentence = ''
for t in doc:
docInOneSentence += (t + ' ') # 所有剩余句子合并
for word in t.split():
vocab[word] = 0 # 所有剩余句子的单词字典,值为0
cv = CountVectorizer(vocabulary=vocab.keys())
docVector = cv.fit_transform([docInOneSentence])
sentenceVector = cv.fit_transform([sentence])
return cosine_similarity(docVector, sentenceVector)[0][0]score是表示当前句子和文档的相似度,这里使用了sklearn的词频统计模块,首先建立词表,然后根据词表,将句子和文章转换成one-hot形式的稀疏向量,再用sklearn自带的cosine_similarity模块计算他们的语义似度。
关于语义相似度计算可以看我之前写过的这篇文章https://blog.csdn.net/zjrn1027/article/details/80170966
同时Tips一下,使用gensim也可以完成如上的任务,具体可以参照gensim的官方文档看看。
下面是摘要生成的过程
n = 3
alpha = 0.9
summarySet = []
while n > 0:
mmr = {}
# kurangkan dengan set summary
for sentence in scores.keys():
if not sentence in summarySet:
mmr[sentence] = alpha * scores[sentence] - (1 - alpha) * calculateSimilarity(sentence, summarySet) # 公式
selected = max(mmr.items(), key=operator.itemgetter(1))[0]
summarySet.append(selected)
# print (summarySet)
n -= 1这里需要设置两个参数,n是抽取生成摘要的句子数量,alpha及公式中的lambda值,用于控制生成摘要的多样性。
依次计算所有句子的MMR值,最后选取MMR最大的三个值作为摘要输出。
这里有一点需要注意,第一次while时,由于还没有选取句子作为摘要,summarySet为空,所以第一句摘要的生成是从文章中选一条与整篇文章相似度最高的词作为摘要存入summarySet。
效果
我们输入两篇不同类型的文章来看看效果。
NEW1:
title:
20年来首次!四千吨级重载货车压桥抵御洪峰,宝成铁路大桥已平安。
context:
7月11日,连续强降雨,让四川登上了中央气象台“头条”,涪江绵阳段水位迅速上涨,洪水一度漫过了宝成铁路涪江大桥桥墩基座,超过封锁水位。洪水在即,中国铁路成都局集团公司紧急调集两列重载货物列车,一前一后开上涪江大桥,每一列货车重量约四千吨,用“重车压梁”的方式,增强桥梁自重,抵御汹涌的洪水。从11日凌晨开始,四川境内成都、绵阳、广元等地连续强降雨,而四川北向出川大动脉—宝成铁路,便主要途径成绵广这一区域。连续的强降雨天气下,绵阳市境内的涪江水位迅速上涨,一度危及到了宝成铁路涪江大桥的安全,上午10时,水位已经超过了涪江大桥上、下行大桥的封锁水位。记者从中国铁路成都局集团公司绵阳工务段了解到,上行线涪江大桥,全长393米,建成于1953年;下行线涪江大桥,全长438米,建成于1995年。“涪江大桥上游有一个水电站,由于洪水太大,水电站已无法发挥调节水位的作用。”情况紧急,铁路部门决定采用“重车压梁”的方式,增强桥梁自重,提高洪峰对桥墩冲刷时的梁体稳定性。简单来说,就是将重量大的货物列车开上涪江大桥,用货车的自重,帮助桥梁抵御汹涌的洪水。恰好,绵阳工务段近期正在进行线路大修,铁路专用的卸砟车,正好停放在绵阳附近。迎着汹涌的洪水,两列重载货车驶向宝成铁路涪江大桥。上午10时30分,第一列46052次货车,从绵阳北站开出进入上行涪江桥。上午11时15分,第二列22001次货车,从皂角铺站进入下行涪江桥。这是两列超过45节编组的重载货物列车,业内称铁路专用卸砟车,俗称“老K车”,车厢里装载的均为铁路道砟,每辆车的砟石的重量在70吨左右。记者从绵阳工务段了解到,货车里满载的砟石、加上一列货车的自重,两列“压桥”的货运列车,每一列的重量超过四千吨。“采用重车压梁的方式来应对水害,在平时的抢险中很少用到。”据了解,在绵阳工务段,上一次采用重车压梁,至少已经是二十年前的事。下午4时许,经铁路部门观测,洪峰过后,涪江水位开始下降,目前已经低于桥梁封锁水位。从下午4点37分开始,两列火车开始撤离涪江大桥。在桥上停留约6个小时后,两列重载货物列车成功完成了“保桥任务”,宝成铁路涪江大桥平安了!
abstract:
7月11日,连续强降雨,让四川登上了中央气象台“头条”,涪江绵阳段水位迅速上涨,洪水一度漫过了宝成铁路涪江大桥桥墩基座,超过封锁水位
连续的强降雨天气下,绵阳市境内的涪江水位迅速上涨,一度危及到了宝成铁路涪江大桥的安全,上午10时,水位已经超过了涪江大桥上、下行大桥的封锁水位
洪水在即,中国铁路成都局集团公司紧急调集两列重载货物列车,一前一后开上涪江大桥,每一列货车重量约四千吨,用“重车压梁”的方式,增强桥梁自重,抵御汹涌的洪水
NEW2:
title:
姆巴佩夺冠后表忠心:留在巴黎 哪儿也不去!
context:
伴随着世界杯的落幕,俱乐部联赛筹备工作又成为主流,转会市场必然也会在世界杯的带动下风起云涌,不过对于在本届赛事上大放异彩的姆巴佩而言,大巴黎可以吃一颗定心丸,世界杯最佳新秀已经亲自表态:留在巴黎哪里也不去。在接受外媒采访时,姆巴佩表达了继续为巴黎效忠的决心。“我会留在巴黎,和他们一起继续我的路途,我的职业生涯不过刚刚开始”,姆巴佩说道。事实上,在巴黎这座俱乐部,充满了内部的你争我夺。上赛季,卡瓦尼和内马尔因为点球事件引发轩然大波,而内马尔联合阿尔维斯给姆巴佩起“忍者神龟”的绰号也让法国金童十分不爽,为此,姆巴佩的母亲还站出来替儿子解围。而早在二月份,一场与图卢兹的比赛,内马尔也因为传球问题赛后和姆巴佩产生口角。由此可见,巴黎内部虽然大牌云集,但是气氛并不和睦。内马尔离开球队的心思早就由来已久,而姆巴佩也常常与其它俱乐部联系在一起,在躲避过欧足联财政公平法案之后,巴黎正在为全力留下二人而不遗余力。好在姆巴佩已经下定决心,这对巴黎高层而言,也算是任务完成了一半。本届世界杯上,姆巴佩星光熠熠,长江后浪推前浪,大有将C罗、梅西压在脚下的趋势,他两次追赶贝利,一次是在1/8决赛完成梅开二度,另一次是在世界杯决赛中完成锁定胜局的一球,成为不满20岁球员的第二人。另外他在本届赛事中打进了4粒入球,和格列兹曼并列全队第一。而对巴黎而言,他们成功的标准只有一条:欧冠。而留下姆巴佩,可以说在争夺冠军的路上有了仰仗,卡瓦尼在本届世界杯同样表现不错,内马尔虽然内心波澜,但是之前皇马官方已经辟谣没有追求巴西天王,三人留守再度重来,剩下的就是图赫尔的技术战术与更衣室的威望,对图赫尔而言,战术板固然重要,但是德尚已经为他提供了更加成功的范本,像团结法国队一样去团结巴黎圣日耳曼,或许这才是巴黎取胜的钥匙。
abstract:
伴随着世界杯的落幕,俱乐部联赛筹备工作又成为主流,转会市场必然也会在世界杯的带动下风起云涌,不过对于在本届赛事上大放异彩的姆巴佩而言,大巴黎可以吃一颗定心丸,世界杯最佳新秀已经亲自表态:留在巴黎哪里也不去
“我会留在巴黎,和他们一起继续我的路途,我的职业生涯不过刚刚开始”,姆巴佩说道
好在姆巴佩已经下定决心,这对巴黎高层而言,也算是任务完成了一半
可以看出生成的摘要质量还是可以的,同时根据文章的长度以及不同的文章类型,对参数n和alpha进行调整,得到的文章摘要效果应该会更好。
在此种方法之上,可以根据Word2Vec训练的词向量进行累加生成句子向量和文章向量,或者使用Doc2Vec直接生成句子向量,对现有的one-hot形式的句子向量进行替代。后续也会对这种方法进行测试~
最后
以上就是瘦瘦电话最近收集整理的关于自动摘要生成(一):最大边界相关算法(MMR)一.摘要方法二.具体算法MMR效果NEW1:NEW2:的全部内容,更多相关自动摘要生成(一):最大边界相关算法(MMR)一内容请搜索靠谱客的其他文章。








发表评论 取消回复