爬虫介绍
- 网络爬虫介绍:
- 2.想要学爬虫先学习写爬虫必须要学会的技能 就是审查元素了
- 3.说了那么多开始写一点简单的代码吧!
网络爬虫介绍:
1.网络爬虫,又称为网页蜘蛛,它可以根据网页的URL爬去网页内的内容URL就是在浏览器里输入的网址,自动地抓取万维网信息的程序或者脚本.
例如:https://www.baidu.com
URL的格式由3部分来组成
1(protocol): // 2(hostname[:port]) /3(path) /
-
(1).第一部分就是协议,例如百度使用的就是https协议上面举得例子百度就是使用https协议的;
-
(2).第二部分是主机名还有端口号,协议为http的默认端口号为80
例如http://www.baidu.com:80这样也是可以访问百度的 而https的默认端口为443
例如https://www.baidu.com:443 -
(3).第三部分就是你要访问的地方的具体地址
例如 https://www.bilibili.com/ 这是哔哩哔哩的首页 在首页后面加上ranking https://www.bilibili.com/ranking/ 就是热播排行榜了
举个例子如果你想找你朋友一起去外面玩 但是你只知道他在xx小区但是你不知道在他在哪个几楼 单元 几零几
https://www.bilibili.com/这个首页就相当于你知道你朋友的家在的小区 而ranking是你朋友的详细地址
你只去你朋友在的小区是找不到你朋友的 如果你知道你朋友在几号楼哪个单元然后几零几(https://www.bilibili.com/ +
ranking)是不是就可以直接去你朋友家里找他了
2.想要学爬虫先学习写爬虫必须要学会的技能 就是审查元素了
审查元素是Google Chrome浏览器提供的一项服务功能,用户只需右键点击“审查元素”(名字),即可打开Chrome Inspector,获得网页各种元素的加载时间、javascript函数、object等信息。
(强烈推荐大家使用谷歌浏览器,不要用别的浏览器)
按F12可以出现这个界面
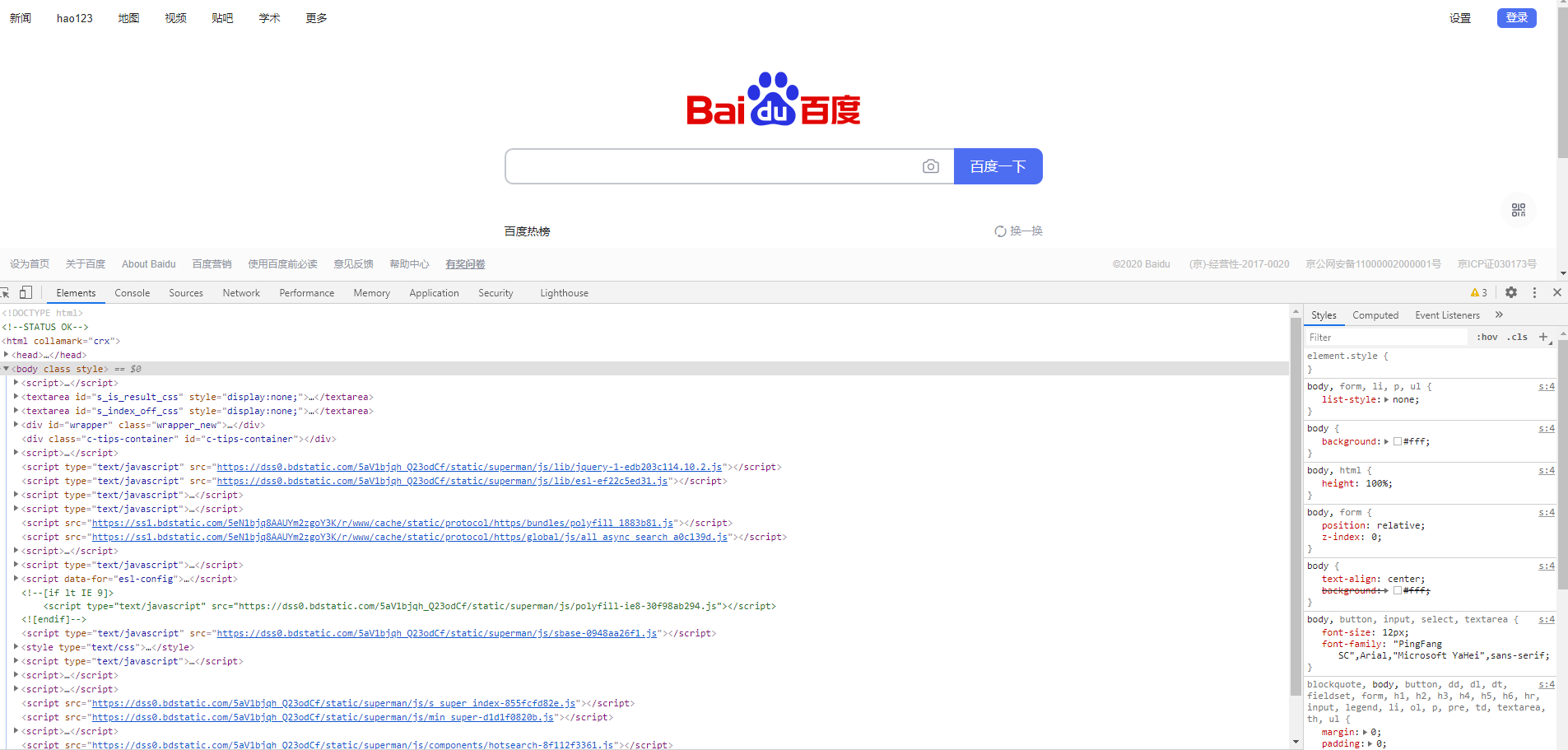
或者右键页面选择检查也可以打开审查元素
浏览器就是作为客户端从服务器端获取信息,然后将信息解析,并展示给我们的。审查元素是可以改变已经加载出来的代码的,但是我们修改的信息不会回传到服务器,服务器存储的 HTML 信息不会改变,只要你一刷新它你改的代码就会全部消失。
3.说了那么多开始写一点简单的代码吧!
- 首先大家先把requests安装了
在终端中输入pip install requests这里建议如果没改pip镜像源的话先去改一下镜像源,具体怎么改镜像源可以去查一查
或者可以使用pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple/这个是清华的镜像源
如果没改镜像源的话下载会很慢- requests库基本方法介绍
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑一下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML页面提交删除请求,对应于HTTP的DELETE |
# 导requests包
import requests
if __name__ == '__main__':
page = "https://tuijian.hao123.com/?type=rec/"
req = requests.get(page)
# 编码可以打开检查元素搜charset
req.encoding = 'utf-8'
print(req.text)
获取到了头条推荐的源代码,这就是一个最最最简单的爬虫了。
最后
以上就是大胆曲奇最近收集整理的关于从0开始学习爬虫的全部内容,更多相关从0开始学习爬虫内容请搜索靠谱客的其他文章。








发表评论 取消回复