1.禁止f12和保存查看代码
这种办法一般就是禁止小白或者心血来潮想看源码的人
相关js代码
<script>
document.onkeydown = function() {
var e = window.event || arguments[0];
if (e.keyCode == 123) {
alert("F12被禁用");
return false;
}
if ((e.ctrlKey) && (e.keyCode == 83)) { //ctrl+s
alert("ctrl+s被禁用");
return false;
}
if ((e.ctrlKey) && (e.keyCode == 85)) { //ctrl+s
alert("ctrl+u被禁用");
return false;
}
if ((e.ctrlKey) && (e.keyCode == 73)) { //ctrl+s
alert("ctrl+shift+i被禁用");
return false;
}
}
document.oncontextmenu = function() {
alert('右键被禁用');
return false;
}
</script>

效果就是无法通过右键,f12,ctrl+s,ctrl+u保存代码。
2.js混淆加密
就是把你的js代码加密,就算别人拿到了代码也不知道你代码写的什么东西,无法研究你的代码,一般js混淆加密和动态页面ajxa渲染数据一起用会有很好的效果。
代码压缩:去除空格、换行等
代码加密:eval、emscripten、WebAssembly等
代码混淆:变量混淆、常量混淆、控制流扁平化、调试保护等
效果参见下图
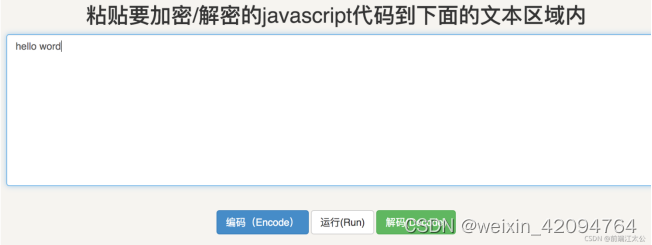
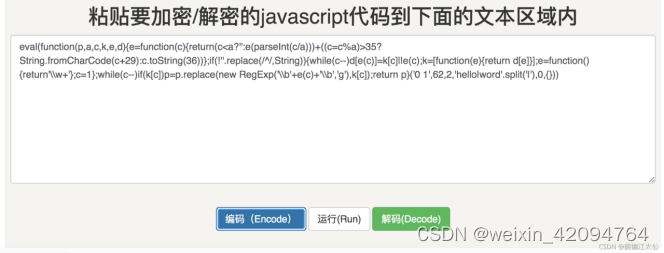
一段简单的hellow world被加密之后已经面目模糊了。推荐一个加密网址:https://www.jsjiami.com/
3.JS写cookie
原理:浏览器运行一段JS生成一个(或多个)cookie再带着这个cookie做二次请求。服务器那边收到这个cookie就认为你的访问是通过浏览器过来的合法访问。这样的话直接通过curl之类的方式就无法获取到页面了。
4.JS加密ajax请求参数
页面只有一个静态页面的框架,所有的数据都是通过ajax请求到数据之后再在页面上渲染的,然后前端和后端有一套加密的通信规则。于是无法直接通过请求页面的方式拿到浏览器展示的数据,只有先去破解js的加密,然后再伪装接口请求才能获得你想要爬取的数据。
这个和js混淆加密合起来用的话别人想要拿到的你的数据首先需要破解你的js加密,然后再看js代码破解你前后端的加密,大大提高了难度。
5.反Selenium爬虫
现在有一些工具可以直接通过浏览器打开页面然后获取页面数据,比如Selenium。由于是直接在浏览器内打开的,可以直接运行js,ajax渲染页面的方法就无法反这种爬虫了。但是,正因为它使用了工具,合直接在浏览器打开还是有区别的,找到这种区别你就可以防止这种直接打开浏览器的工具来爬取你的页面内容。
比如通过window.navigator.webdriver,它的作用是在用户打开浏览器时给当前窗口一个window属性来存放用户的各种信息,当我们使用selenium时值为true,正常用户访问网站时为false。
webdriver = window.navigator.webdriver;
if(webdriver){
console.log('你以为使用Selenium模拟浏览器就没事了?')
} else {
console.log('正常浏览器')
}
除了这些办法还有判断ua信息,ip限制,记录访问频率等等方式来反爬虫,没有完美的反爬方式,也没有能够爬到所有页面的爬虫,只有不断学习钻研才能继续在这条技术道路上走下去。
最后
以上就是忧虑万宝路最近收集整理的关于前端js反爬虫技术总结的全部内容,更多相关前端js反爬虫技术总结内容请搜索靠谱客的其他文章。








发表评论 取消回复