数据字段阐述:
* *数据:* *
这个项目中使用的数据来自一个匿名组织的社交媒体广告活动。
1) ad_id:每个ad(广告)的唯一ID。
2) XYZ campaign ID: XYZ公司每一个广告活动的ID。
3) fbcampaigns:一个与Facebook如何追踪每个活动相关的ID。
4) age:显示AD的对象的年龄。
5) gender:性别
6) interest:指定个人兴趣所属类别的代码(个人的Facebook公开资料中提到的兴趣)。
7) Impressions:广告被播放的次数。
8) Clicks:点击量:该广告的点击量。
9) Spent:支出:xyz公司支付给Facebook的用于展示该广告的金额。
10) Total conversion:总转化率:在看到广告后询问产品的总人数。
11) Approved conversion:经批准的转化率:在看到广告后购买产品的总人数。
读取数据/查看数据异常值和dytpe/查看数据的各种统计数据
df=pd.read_csv("KAG_conversion_data.csv")
#%%
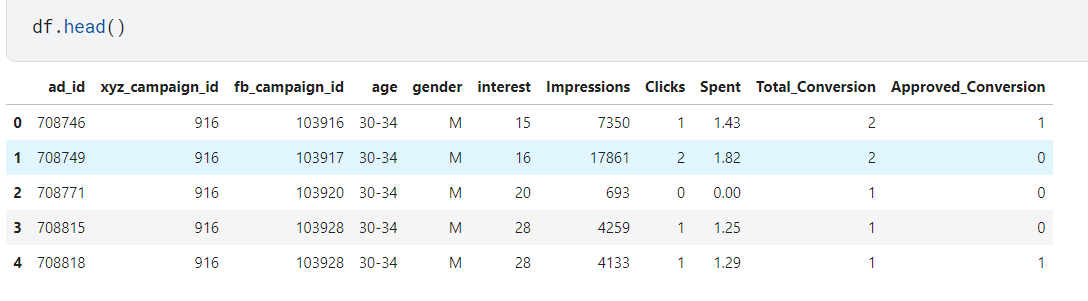
##查看前五行
df.head()
#%%
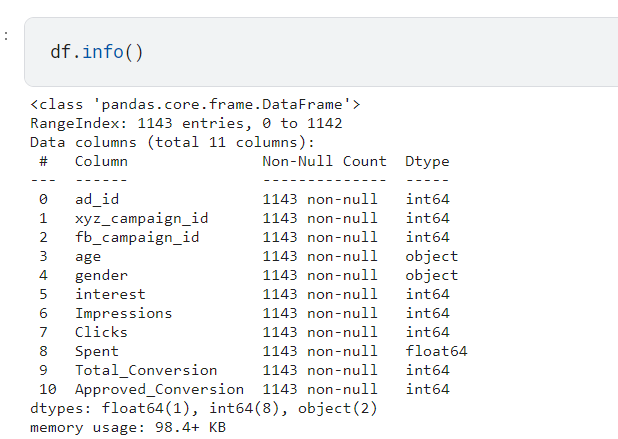
##查看空行和数据类型
df.info()
#%%
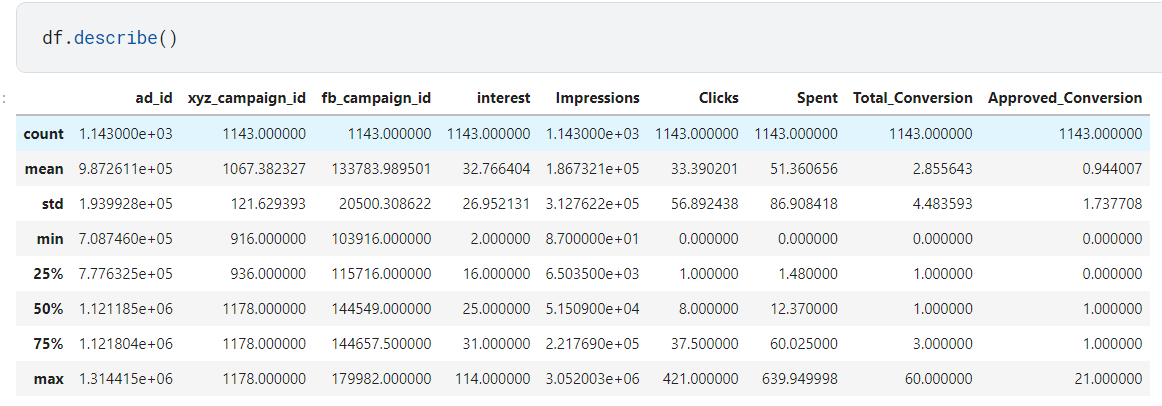
##查看各字段统计学参数
df.describe()
result:
导入matplotlib,查看pandas的自动生成的数据分析报告
import matplotlib.pyplot as plt
import seaborn as sns
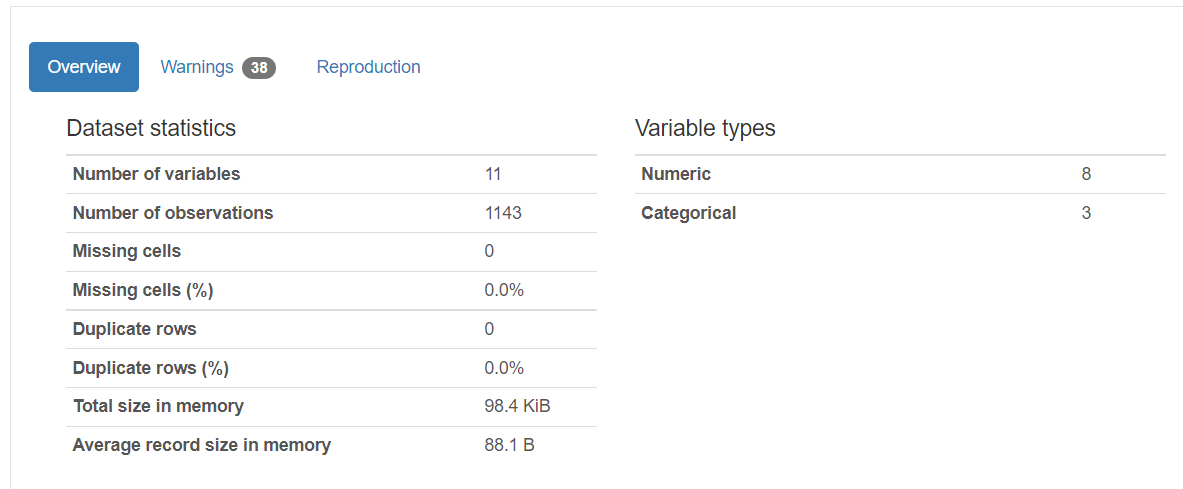
from pandas_profiling import ProfileReport
plt.ion()
profile = ProfileReport(df, title="Pandas Profiling Report")
profile
result
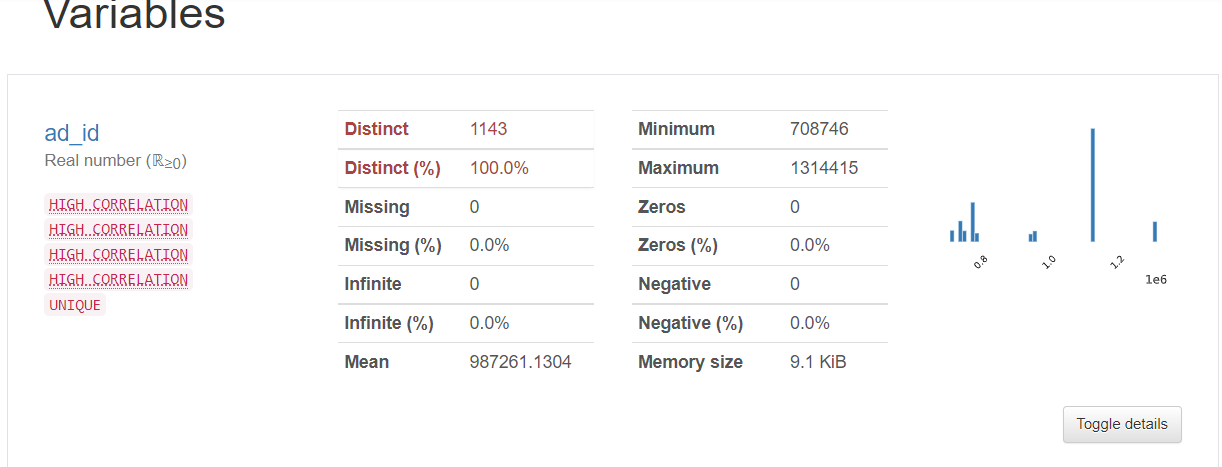
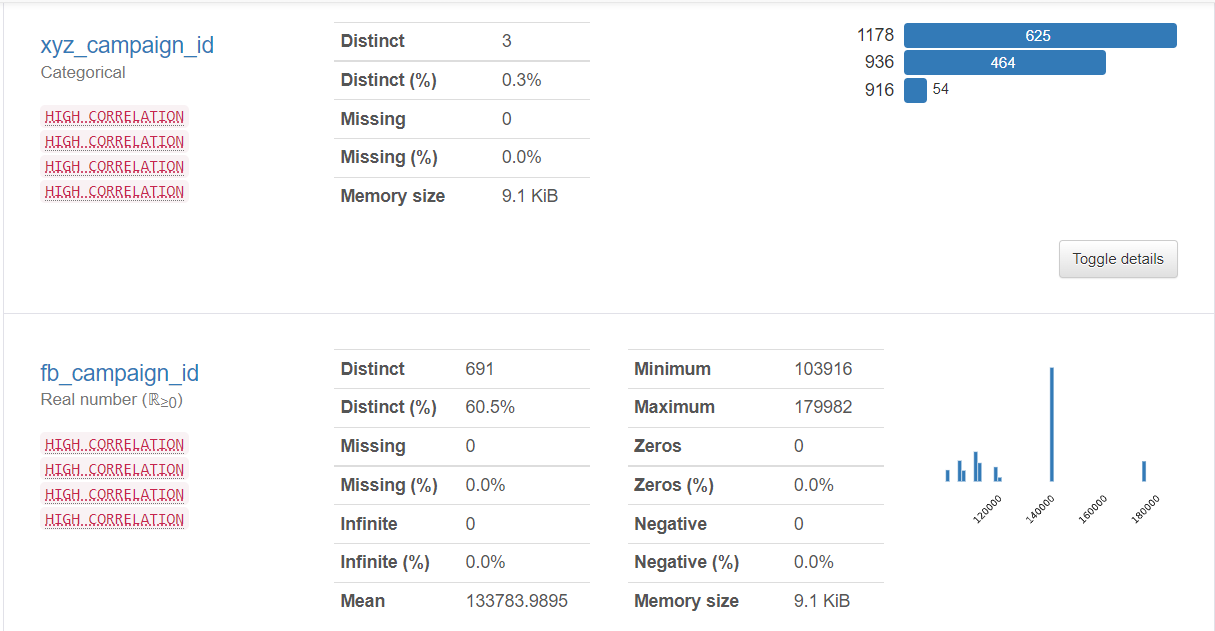
缺失值
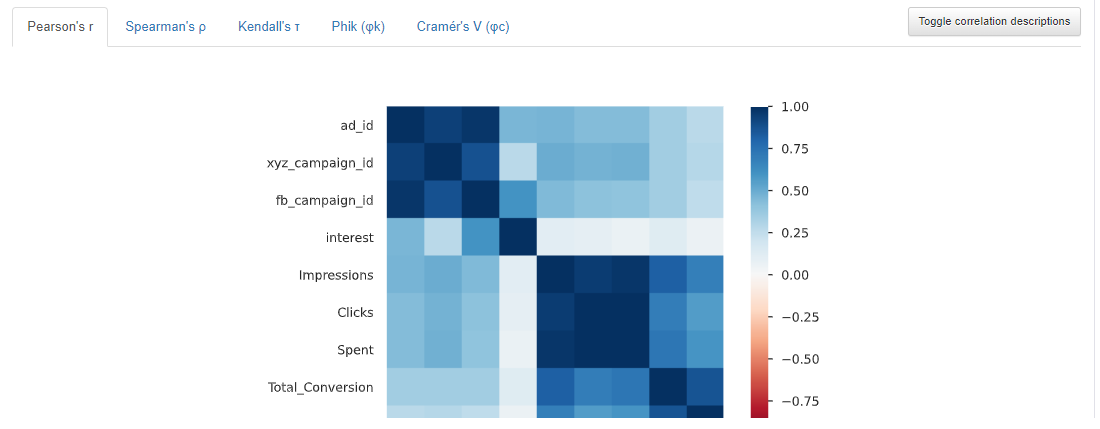
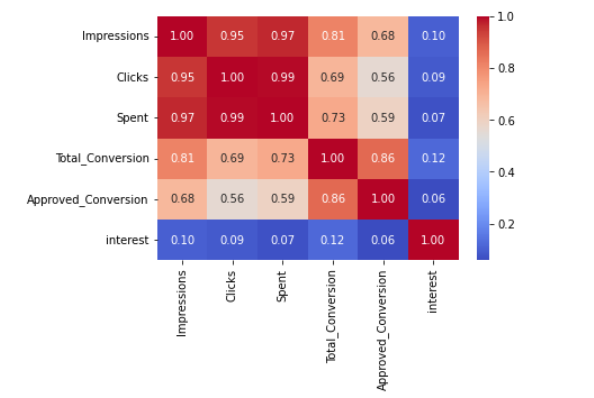
相关矩阵
#Correlation Matrix 观察列与列直接的相互关系
g=sns.heatmap(df[["Impressions","Clicks","Spent","Total_Conversion","Approved_Conversion","interest"]].corr(),annot=True ,fmt=".2f", cmap="coolwarm")
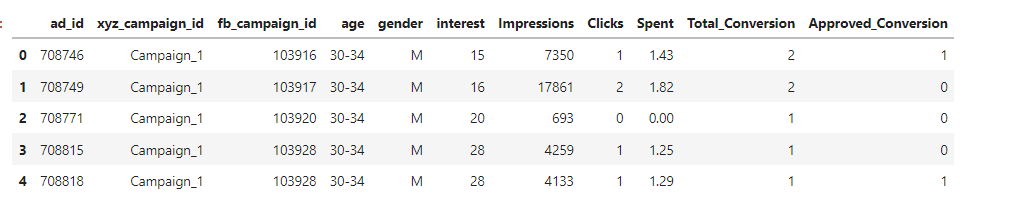
类别id转换
df["xyz_campaign_id"].replace({916:"Campaign_1",936:"Campaign_2",1178:"Campaign_3"}, inplace=True)
df.head()
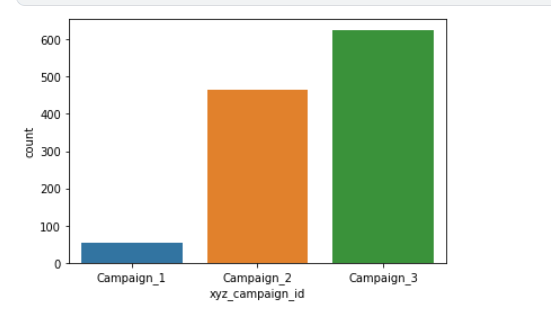
呈现xyz_campaign_id数据分布
# count plot on single categorical variable
sns.countplot(x ='xyz_campaign_id', data = df)
plt.show()
查看不同类别的最终转化数(Approved conversion )
plt.bar(df["xyz_campaign_id"], df["Approved_Conversion"])
plt.ylabel("Approved_Conversion")
plt.title("company vs Approved_Conversion")
plt.show()
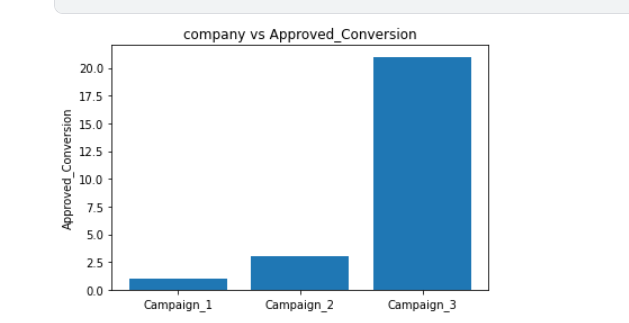
分析:在这里,我们看到这些列是有相关关系的
在广告数量较少的情况下,Campaign_3的核准转化数很高,而Campaign_1的核准转化率很好
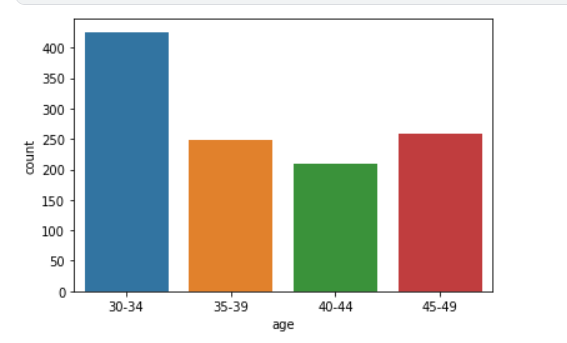
##查看年龄的分布
sns.countplot(x ='age', data = df)
plt.show()
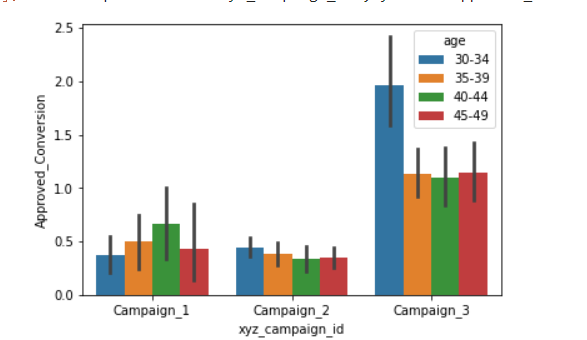
##查看不同年龄层的转化数
sns.barplot(x=df["xyz_campaign_id"], y=df["Approved_Conversion"], hue=df["age"], data=df)
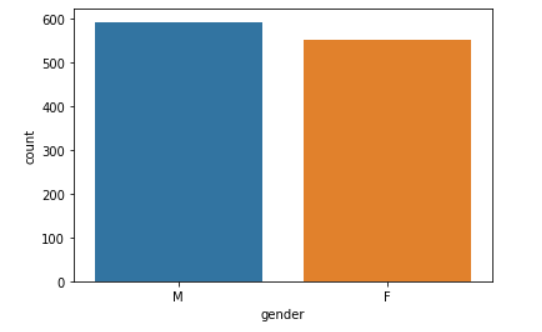
#查看男女比例
sns.countplot(x ='gender', data = df)
# Show the plot
plt.show()
#查看不同年龄层的转化数
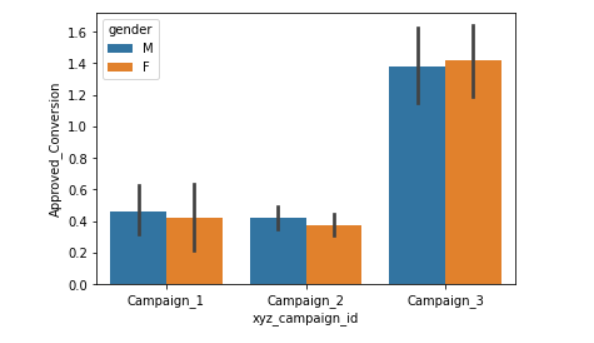
sns.barplot(x=df["xyz_campaign_id"], y=df["Approved_Conversion"], hue=df["gender"], data=df)
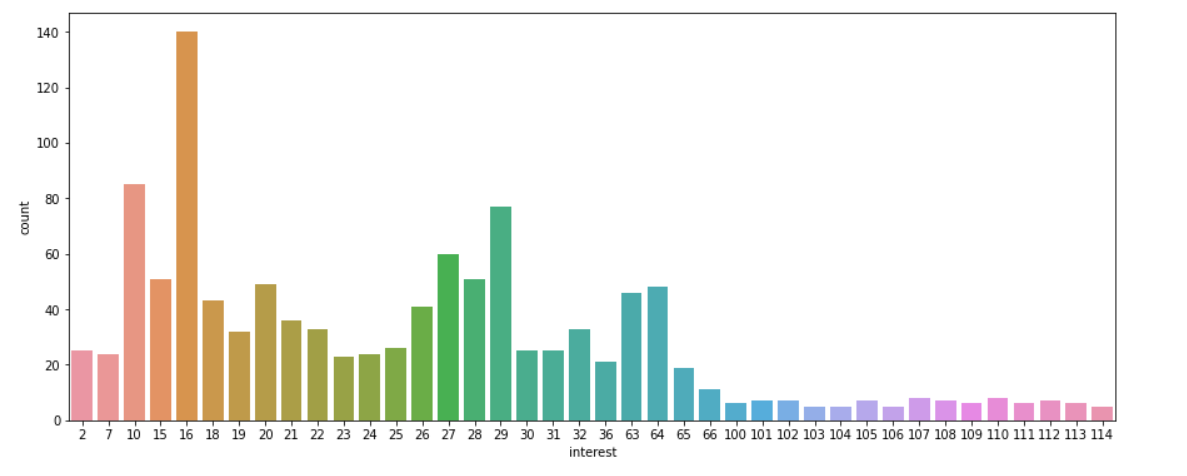
#查看兴趣的分布比例
fig, ax = plt.subplots(figsize=(15,6))
sns.countplot(x ='interest', data = df)
# Show the plot
plt.show()
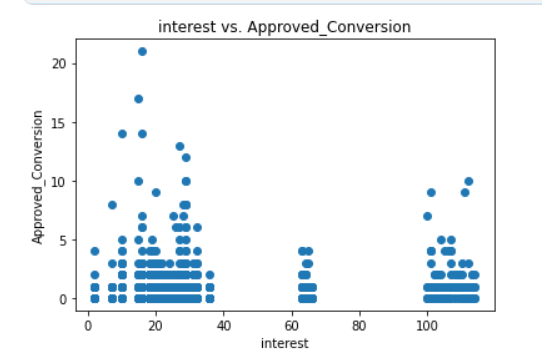
#查看不同兴趣的转化分布散点图
plt.scatter(df["interest"], df["Approved_Conversion"])
plt.title("interest vs. Approved_Conversion")
plt.xlabel("interest")
plt.ylabel("Approved_Conversion")
plt.show()
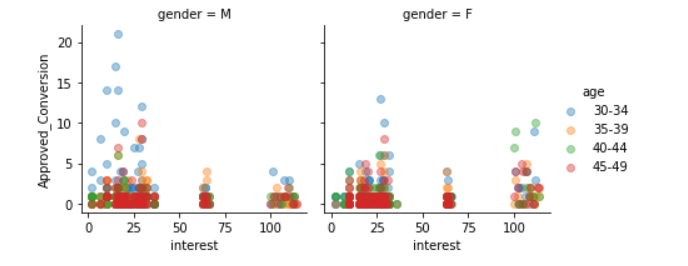
#对性别做分类作兴趣转化数分布图
g = sns.FacetGrid(df, col="gender",hue = 'age')
g.map(plt.scatter, "interest", "Approved_Conversion", alpha=.4)
g.add_legend();
#同理,对年龄作分类作兴趣转化数分布图
g = sns.FacetGrid(df, col="age",hue = 'gender')
g.map(plt.scatter, "interest", "Approved_Conversion", alpha=.4)
g.add_legend();
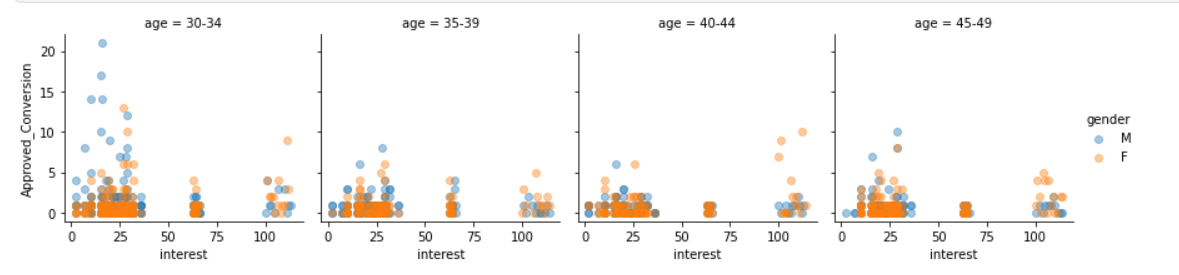
结论
相关性:
所有列之间都有相关关系。
关于campaign_3:
campaign_3有最多的广告ad。
campaign_3有最好的Approved_conversion数。
年龄组: 在campaigns _3和campaigns _2中,30-34岁年龄组表现出更多的兴趣,而在campaigns _1中,40-44岁年龄组表现出更多的兴趣。
性别: 两种性别在这三种运动中都表现出相似的兴趣。
兴趣 interest:虽然100之后的兴趣次数少了,但是100之后实际购买该产品的用户增加了,其余的分配是根据预期的。
最后
以上就是干净发夹最近收集整理的关于销售转化率分析的全部内容,更多相关销售转化率分析内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复