在某些真实的应用场景如移动或者嵌入式设备,如此大而复杂的模型是难以被应用的。
(1)首先是模型过于庞大,面临着内存不足的问题。
(2)其次这些场景要求低延迟,或者说响应速度要快。
所以,研究小而高效的CNN模型在这些场景至关重要。
目前的研究总结来看分为两个方向:一是对训练好的复杂模型进行压缩得到小模型;二是直接设计小模型并进行训练。不管如何,其目标在保持模型性能(accuracy)的前提下降低模型大小(parameters size),同时提升模型速度(speed, low latency)。
【学习链接】
https://zhuanlan.zhihu.com/p/422258900
https://mp.weixin.qq.com/s/aNTLkjpV5UdJDhvuzJUD4w
【MobileNet V1】
CSDN:https://blog.csdn.net/c20081052/article/details/80703896
论文:https://arxiv.org/pdf/1704.04861.pdf
Google提出的移动端模型MobileNet,其核心是采用了可分解的depthwise separable convolution代替传统卷积,其不仅可以降低模型计算复杂度,而且可以大大降低模型大小。在真实的移动端应用场景,像MobileNet这样类似的网络将是持续研究的重点。
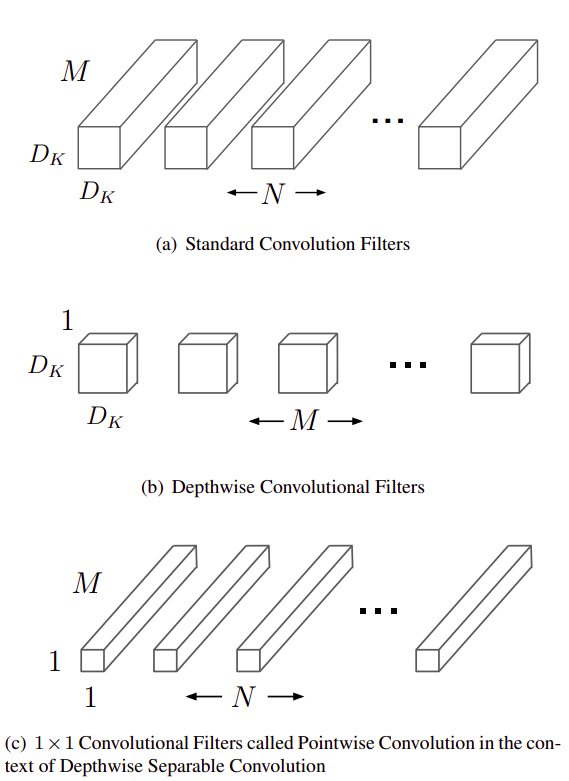
MobileNet的基本单元是深度级可分离卷积(depthwise separable convolution),其实这种结构之前已经被使用在Inception模型中
深度级可分离卷积其实是一种可分解卷积操作(factorized convolutions),其可以分解为两个更小的操作:depthwise convolution和pointwise convolution,如图3所示。
Depthwise convolution和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。
pointwise convolution其实就是普通的卷积,只不过其采用1x1的卷积核。图2中更清晰地展示了两种操作。
对于depthwise separable convolution,其首先是采用depthwise convolution对不同输入通道分别进行卷积,然后采用pointwise convolution将上面的输出再进行结合,这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。
MobileNetV1模型中使用 ReLU6 作为非线性层,在低精度计算时能压缩动态范围,算法更稳健。
ReLU6 定义为:f(x) = min(max(x, 0), 6)

【MobileNet V2】
CSDN:https://blog.csdn.net/kangdi7547/article/details/81431572
MobileNetV1遗留的问题
1、结构问题:
MobileNet V1 的结构其实非常简单,论文里是一个非常复古的直筒结构,类似于VGG一样。
这种结构的性价比其实不高,后续一系列的 ResNet, DenseNet 等结构已经证明通过复用图像特征,使用 Concat/Eltwise+ 等操作进行融合,能极大提升网络的性价比。
2、Depthwise Convolution的潜在问题:
Depthwise Conv确实是大大降低了计算量,而且N×N Depthwise +1×1PointWise的结构在性能上也能接近N×N Conv。
在实际使用的时候,我们发现Depthwise部分的kernel比较容易训废掉:训练完之后发现Depthwise训出来的kernel有不少是空的。
当时我们认为,Depthwise每个kernel dim相对于普通Conv要小得多,过小的kernel_dim, 加上ReLU的激活影响下,使得神经元输出很容易变为0,所以就学废了。
ReLU对于0的输出的梯度为0,所以一旦陷入0输出,就没法恢复了。我们还发现,这个问题在定点化低精度训练的时候会进一步放大。
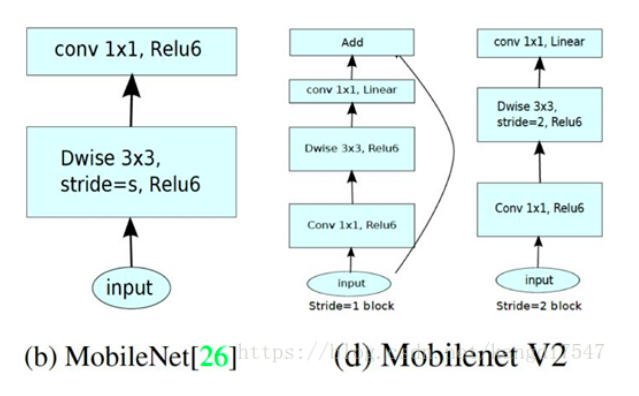
MobileNet V2的创新点
(1)采用inverse-residual结构,’’‘expand + depthwise + pointwise’’’。
(2)在depthwise卷积前加上了一层1x1卷积,先提升通道数。
(3)每层的最后一个1x1卷积后不再采用ReLU6,而是采用线性激活。
【MobileNet V3】
代码(torch):https://github.com/kuan-wang/pytorch-mobilenet-v3
论文:https://arxiv.org/pdf/1905.02244.pdf
CSDN:MobileNetV3 学习1
CSDN:MobileNetV3 学习2
创新点:
(1)使用 AutoML 为给定的问题找到最佳的神经网络架构。
具体来说,MobileNetV3 利用了两种 AutoML 技术,即:
MnasNet(一种自动移动神经体系结构搜索(MNAS)方法,https://ai.google/research/pubs/pub47217
NetAdapt(适用于移动应用程序的平台感知型算法,https://arxiv.org/pdf/1804.03230.pdf
MobileNetV3 首先使用 MnasNet 进行粗略结构的搜索,然后使用强化学习从一组离散的选择中选择最优配置。之后,MobileNetV3 再使用 NetAdapt 对体系结构进行微调,这体现了 NetAdapt 的补充功能,它能够以较小的降幅对未充分利用的激活通道进行调整。
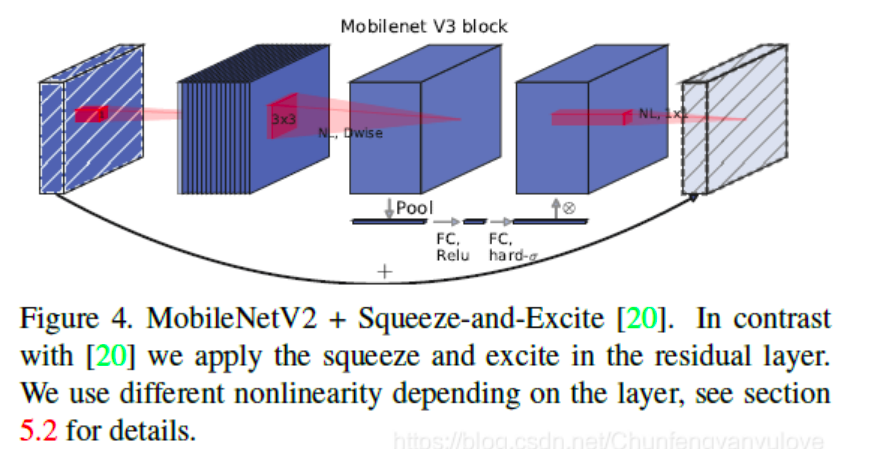
(2)引入SE结构
MobileNetV3 的另一个新颖想法是在核心架构中加入一种名为「Squeeze-and-Excitation」的神经网络(简称 SE-Net,也是 ImageNet 2017 图像分类冠军)。
该神经网络的核心思想是通过显式地建模网络卷积特征通道之间的相互依赖关系,来提高网络所产生表示的质量。具体而言,就是通过学习来自动获取到每个特征通道的重要程度,然后依照这一结果去提升有用的特征并抑制对当前任务用处不大的特征。
为此,开发者们提出了一种允许网络进行特征重新校准的机制。通过该机制,网络可以学习使用全局信息来选择性地强调信息性特征,并抑制不太有用的特征。
而在 MobileNetV3 的例子中,该架构扩展了 MobileNetV2,将 SE-Net 作为搜索空间的一部分,最终得到了更稳定的架构。
在bottlenet结构中加入了SE结构,并且放在了depthwise filter之后,如下图:
因为SE结构会消耗一定的时间,所以作者在含有SE的结构中,将expansion layer的channel变为原来的1/4,这样作者发现,即提高了精度,同时还没有增加时间消耗。
(3)修改头部channel数量
修改头部卷积核channel数量,mobilenet v2中使用的是32 x 3 x 3,
作者发现,其实32可以再降低一点,所以这里作者改成了16,在保证了精度的前提下,降低了3ms的速度。
作者提供了两个版本的v3,分别是large和small,对应于高资源和低资源的情况。两者都是使用NAS进行搜索出来的。
(4)非线性变换(新激活函数)的改变
作者发现一种新出的激活函数swish x(如下) 能有效改进网络精度,但是计算量太大了。
作者使用ReLU6(x+3)/6来近似替代sigmoid,进行了速度优化,具体如下:
【Shuffle Net】
知呼 : https://zhuanlan.zhihu.com/p/32304419
论文:https://arxiv.org/pdf/1707.01083.pdf
torch实现:https://github.com/xiaohu2015/DeepLearning_tutorials/blob/master/CNNs/ShuffleNet.py
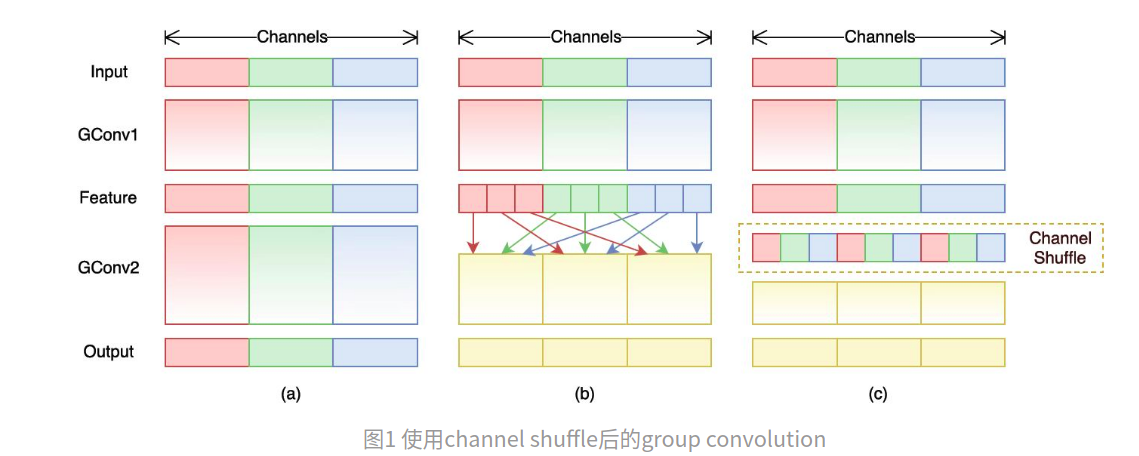
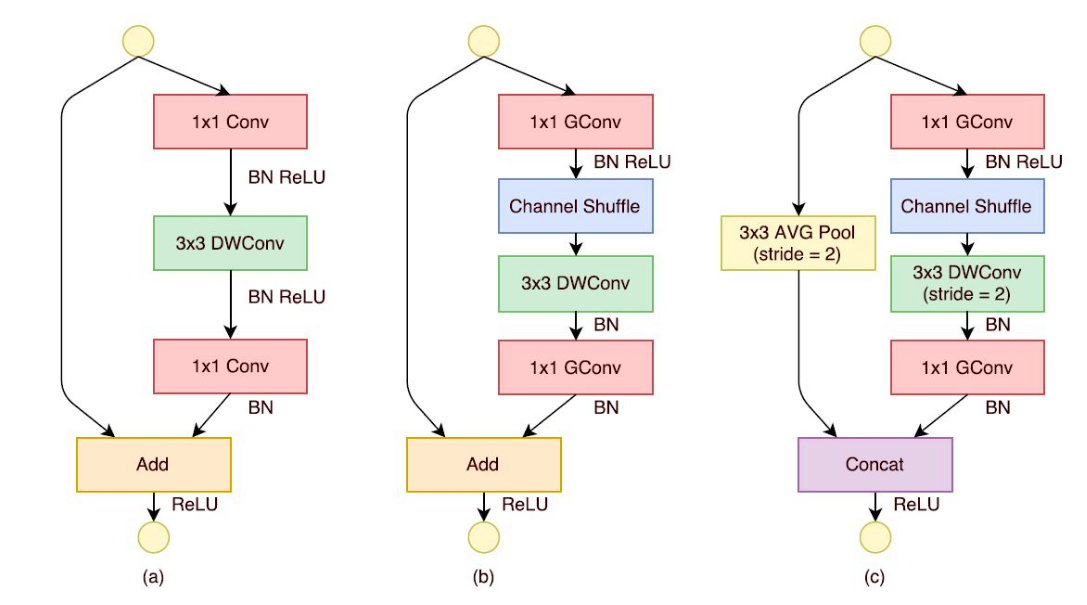
ShuffleNet的核心设计理念是对不同的channels进行shuffle来解决group convolution带来的弊端。
Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。
因为一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection)。
而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)。
但是group convolution存在另外一个弊端,如图1-a所示,其中GConv是group convolution,这里分组数是3。
可以看到当堆积GConv层后一个问题是不同组之间的特征图是不通信的,这就好像分了三个互不相干的路,大家各走各的,这目测会降低网络的特征提取能力。
这样你也可以理解为什么Xception,MobileNet等网络采用密集的1x1卷积,因为要保证group convolution之后不同组的特征图之间的信息交流。
但是达到上面那个目的,我们不一定非要采用dense pointwise convolution。
如图1-b所示,你可以对group convolution之后的特征图进行“重组”,这样可以保证接下了采用的group convolution其输入来自不同的组,因此信息可以在不同组之间流转。
这个操作等价于图2-c,即group convolution之后对channels进行shuffle,但并不是随机的,其实是“均匀地打乱”。
【Squeeze Net】
CSDN:https://zhuanlan.zhihu.com/p/49465950
论文:https://arxiv.org/pdf/1602.07360v3.pdf
代码:https://github.com/senliuy/CNN-Structures/blob/master/SqueezeNet.ipynb
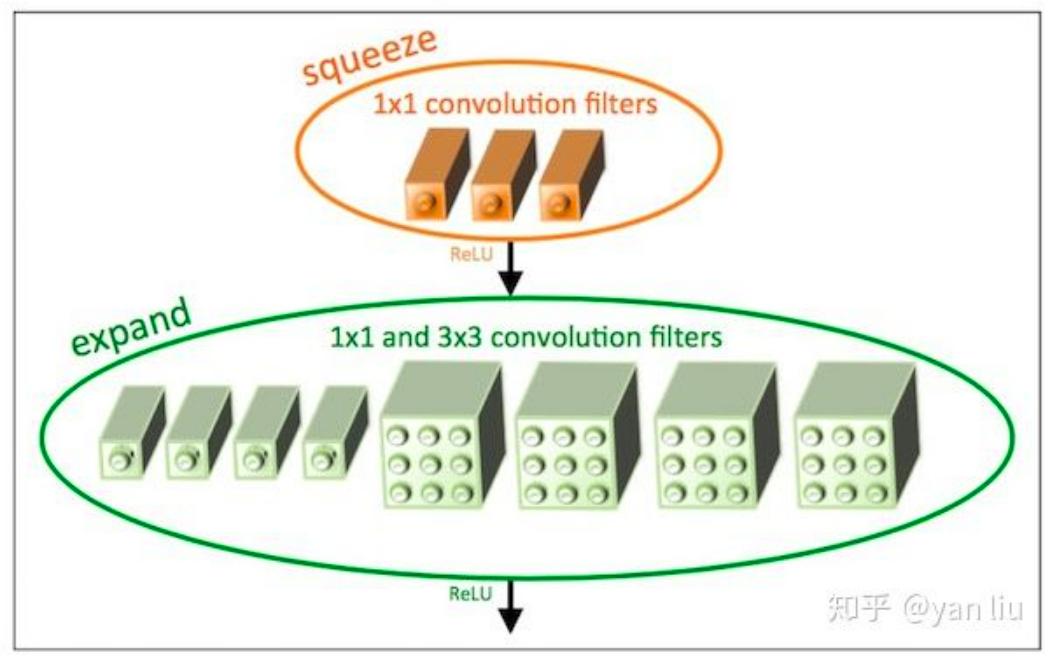
SqueezeNet的模型压缩使用了3个策略:
将 卷积替换成 卷积:通过这一步,一个卷积操作的参数数量减少了9倍;
减少 卷积的通道数:一个 卷积的计算量是 (其中 , 分别是输入Feature Map和输出Feature Map的通道数),作者任务这样一个计算量过于庞大,因此希望将 , 减小以减少参数数量;
将降采样后置:作者认为较大的Feature Map含有更多的信息,因此将降采样往分类层移动。注意这样的操作虽然会提升网络的精度,但是它有一个非常严重的缺点:即会增加网络的计算量。
【EfficientNet】
知乎:https://zhuanlan.zhihu.com/p/96773680/
代码:https://github.com/qubvel/efficientnet
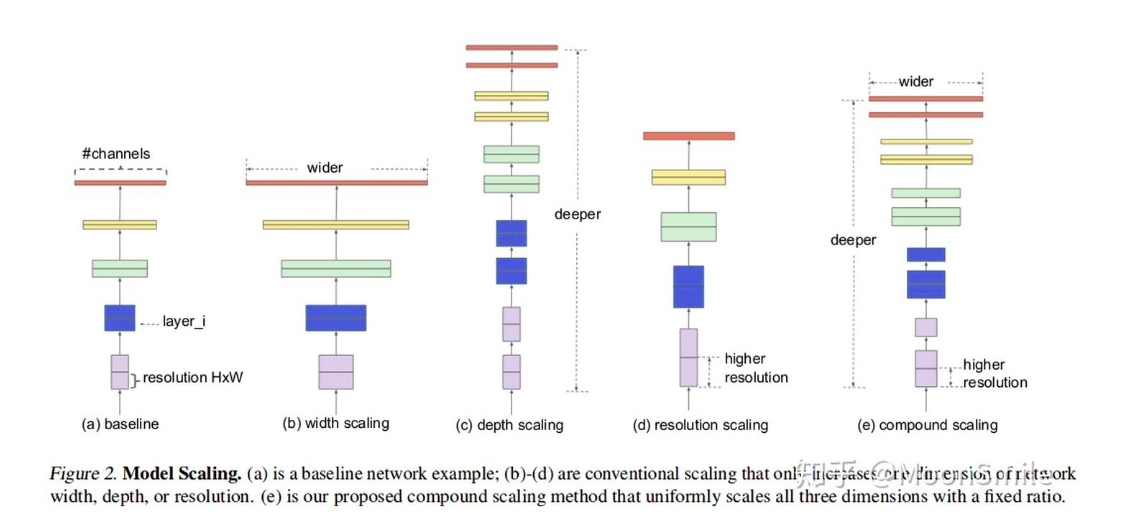
卷积神经网络(ConvNets)通常是在固定的资源预算下发展起来的,如果有更多的资源可用的话,则会扩大规模以获得更好的精度
比如可以提高网络深度(depth)、网络宽度(width)和输入图像分辨率 (resolution)大小。
但是通过人工去调整 depth, width, resolution 的放大或缩小的很困难的,在计算量受限时有放大哪个缩小哪个,这些都是很难去确定的,换句话说,这样的组合空间太大,人力无法穷举。
基于上述背景,该论文提出了一种新的模型缩放方法,它使用一个简单而高效的复合系数来从depth, width, resolution 三个维度放大网络,不会像传统的方法那样任意缩放网络的维度,基于神经结构搜索技术可以获得最优的一组参数(复合系数)。
对网络的扩展可以通过
(1)增加网络层数(depth,比如从 ResNet (He et al.)从resnet18到resnet200 )。
(2)通过增加宽度,比如WideResNet (Zagoruyko & Komodakis, 2016)和Mo-bileNets (Howard et al., 2017) 可以扩大网络的width (#channels),
(3)更大的输入图像尺寸(resolution)也可以帮助提高精度。
如下图所示: (a)是基本模型,(b)是增加宽度,(c)是增加深度,(d)是增大输入图像分辨率,(e)是EfficientNet,它从三个维度均扩大了。
但是扩大多少,就是通过作者提出来的复合模型扩张方法结合神经结构搜索技术获得的。
【复合扩张方法】
作者指出,模型扩张的各个维度之间并不是完全独立的,比如说,对于更大的分辨率图像,应该使用更深、更宽的网络,这就意味着需要平衡各个扩张维度,而不是在单一维度张扩张。
为了追求更好的精度和效率,在ConvNet缩放过程中平衡网络宽度、深度和分辨率的所有维度是至关重要的。bile 一样的搜索空间和优化目标。

【EfficientDet】
知呼:https://zhuanlan.zhihu.com/p/96773680/
代码:https://github.com/xuannianz/EfficientDet
模型效率在计算机视觉中的地位越来越重要,本文系统地研究了用于目标检测的各种神经网络结构设计选择,并提出了几种提高效率的关键优化方法。
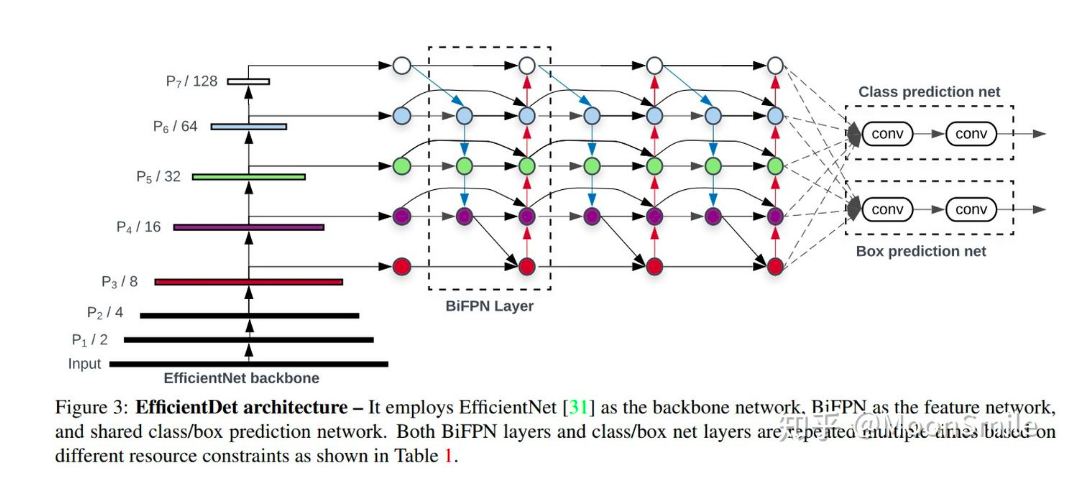
首先,我们提出了一个加权的双向特征金字塔网络(BiFPN),该网络允许简单快速的多尺度特征融合;
其次,我们提出了一种复合尺度扩张方法,该方法可以统一地对所有主干网、特征网络和预测网络的分辨率、深度和宽度进行缩放。
基于这些优化,我们开发了一个新的对象检测器家族,称为EfficientDet。
最后
以上就是执着大地最近收集整理的关于轻量CNN模型的全部内容,更多相关轻量CNN模型内容请搜索靠谱客的其他文章。








发表评论 取消回复