这个项目主要是对目前的一些基于深度学习的点击率预测算法进行了实现,如PNN,WDL,DeepFM,MLR,DeepCross,AFM,NFM,DIN,DIEN,xDeepFM,AutoInt等,并且对外提供了一致的调用接口。 关于每种算法的介绍这里就不细说了,大家可以看论文,看知乎,看博客,讲的都很清楚。
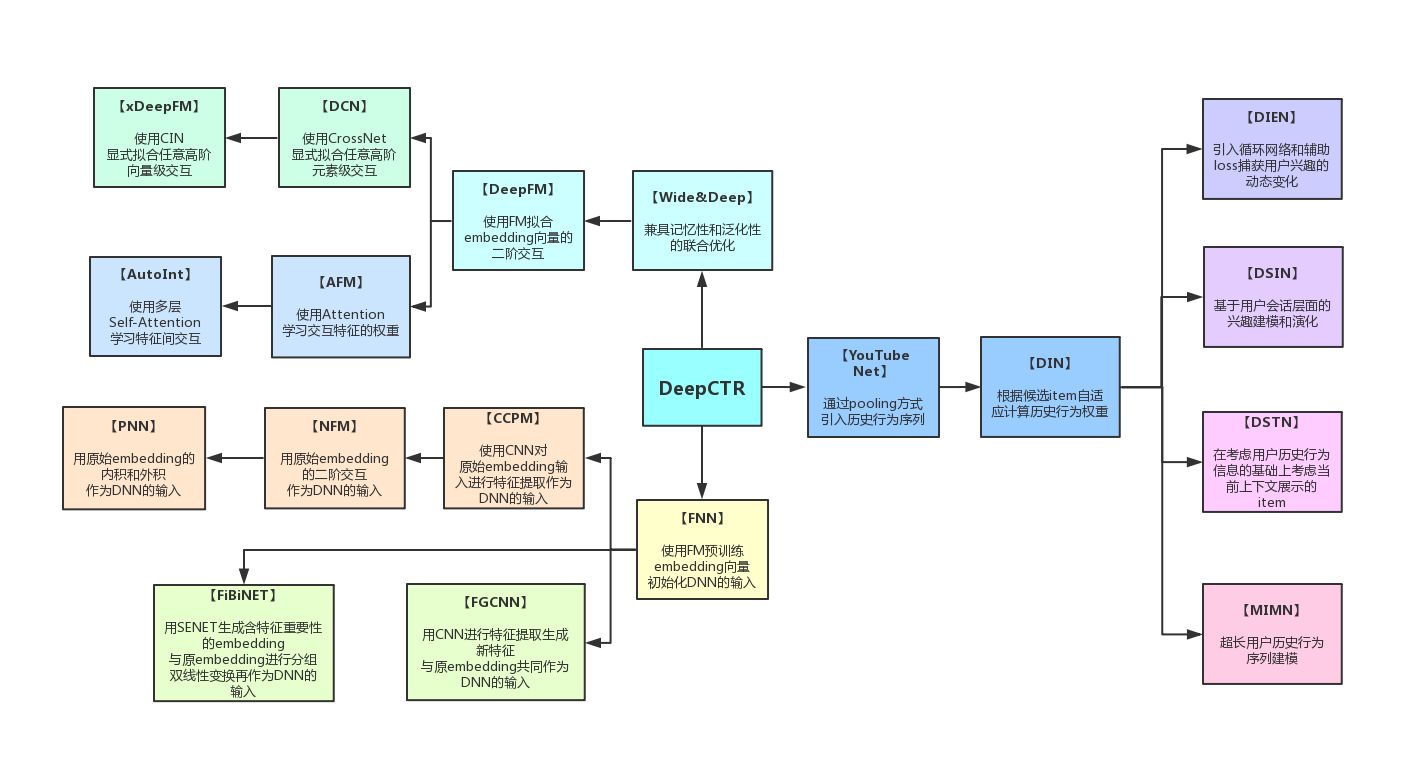
DeepCTR的设计主要是面向那些对深度学习以及CTR预测算法感兴趣的同学,使他们可以利用这个包:
- 从一个统一视角来看待各个模型
- 快速地进行简单的对比实验
- 利用已有的组件快速构建新的模型
统一视角
DeepCTR通过对现有的基于深度学习的点击率预测模型的结构进行抽象总结,在设计过程中采用模块化的思路,各个模块自身具有高复用性,各个模块之间互相独立。 基于深度学习的点击率预测模型按模型内部组件的功能可以划分成以下4个模块:输入模块,嵌入模块,特征提取模块,预测输出模块。
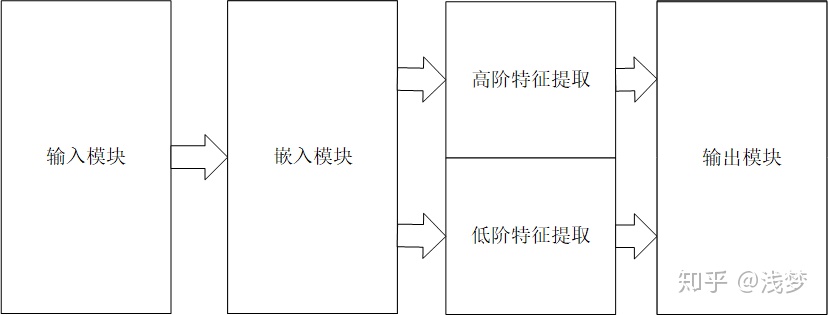
快速实验

下面是一个简单的用DeepFM模型在criteo数据集上训练的的例子。
import pandas as pd
from sklearn.metrics import log_loss, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from deepctr.models import DeepFM
from deepctr.feature_column import SparseFeat, DenseFeat, get_feature_names
if __name__ == "__main__":
data = pd.read_csv('./criteo_sample.txt')
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_features = ['I' + str(i) for i in range(1, 14)]
data[sparse_features] = data[sparse_features].fillna('-1', )
data[dense_features] = data[dense_features].fillna(0, )
target = ['label']
# 1.Label Encoding for sparse features,and do simple Transformation for dense features
for feat in sparse_features:
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
mms = MinMaxScaler(feature_range=(0, 1))
data[dense_features] = mms.fit_transform(data[dense_features])
# 2.count #unique features for each sparse field,and record dense feature field name
fixlen_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4 )
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
for feat in dense_features]
dnn_feature_columns = fixlen_feature_columns
linear_feature_columns = fixlen_feature_columns
feature_names = get_feature_names(linear_feature_columns + dnn_feature_columns)
# 3.generate input data for model
train, test = train_test_split(data, test_size=0.2, random_state=2018)
train_model_input = {name:train[name] for name in feature_names}
test_model_input = {name:test[name] for name in feature_names}
# 4.Define Model,train,predict and evaluate
model = DeepFM(linear_feature_columns, dnn_feature_columns, task='binary')
model.compile("adam", "binary_crossentropy",
metrics=['binary_crossentropy'], )
history = model.fit(train_model_input, train[target].values,
batch_size=256, epochs=10, verbose=2, validation_split=0.2, )
pred_ans = model.predict(test_model_input, batch_size=256)
print("test LogLoss", round(log_loss(test[target].values, pred_ans), 4))
print("test AUC", round(roc_auc_score(test[target].values, pred_ans), 4))快速构建新模型
所有的模型都是严格按照4个模块进行搭建的,输入和嵌入以及输出基本都是公用的,每个模型的差异之处主要在特征提取部分。
下面是DeepFM模型的特征提取核心代码,大家也可以利用这些已有的组件去构建自己想要的模型。
fm_input = Concatenate(axis=1)(embed_list)#将输入拼接成FM层需要的shape
deep_input = Flatten()(fm_input)#将输入拼接成Deep网络需要的shape
fm_out = FM()(fm_input)#调用FM组件
deep_out = DNN(dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout,dnn_use_bn, seed)(deep_input)#调用Deep网络组件
deep_logit = Dense(1, use_bias=False, activation=None)(deep_out)如何使用呢!?
首先可以通过一下命令进行安装~
pip install deepctr[cpu]#CPU版本
pip install deepctr[gpu]#GPU版本DeepCTR:易用可扩展的深度学习点击率预测算法包 - 知乎
最后
以上就是糟糕金毛最近收集整理的关于DeepCTR:易用可扩展的深度学习点击率预测算法包的全部内容,更多相关DeepCTR:易用可扩展内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复