关注公众号 【离心计划】呀,一起逃离地球表面
专栏链接:Redis专栏 https://link.juejin.cn/?target=https%3A%2F%2Fmp.weixin.qq.com%2Fmp%2Fappmsgalbum%3F__biz%3DMzkzOTM4MzYwNQ%3D%3D%26action%3Dgetalbum%26album_id%3D2642660048770744323%26scene%3D173%26from_msgid%3D2247483787%26from_itemidx%3D1%26count%3D3%26nolastread%3D1%23wechat_redirect
https://link.juejin.cn/?target=https%3A%2F%2Fmp.weixin.qq.com%2Fmp%2Fappmsgalbum%3F__biz%3DMzkzOTM4MzYwNQ%3D%3D%26action%3Dgetalbum%26album_id%3D2642660048770744323%26scene%3D173%26from_msgid%3D2247483787%26from_itemidx%3D1%26count%3D3%26nolastread%3D1%23wechat_redirect
前言
这一章我们进入Redis的正式篇,问起Redis的作用是什么,相信很多人会回答:缓存。确实Redis最主要的功能就是为服务提供数据缓存,很经典的案例就是在DB前加上Redis,应对大流量的DB请求,缓解DB压力。而Redis的缓存也叫做旁路缓存,或者说第三方缓存,因为Redis本身是一个数据服务,部署在和我们应用不同的进程环境下,而缓存其实在我们的计算机中也非常常见,所以在说Redis之前我们可以先看看计算机中有哪些缓存机制。
计算机中的缓存
CPU缓存是计算机中非常重要的缓存机制,提供了CPU工作时指令级别的缓存,这个缓存是按块来的,叫做Cache-Line,也叫做缓存行,避免CPU频繁去内存中获取执行指令,对于CPU来说从缓存和内存去拿数据,是两个不同量级的耗时,在成千上万次的操作面前,细微的问题会被放大。普遍的计算机有三级缓存(L1、L2、L3):
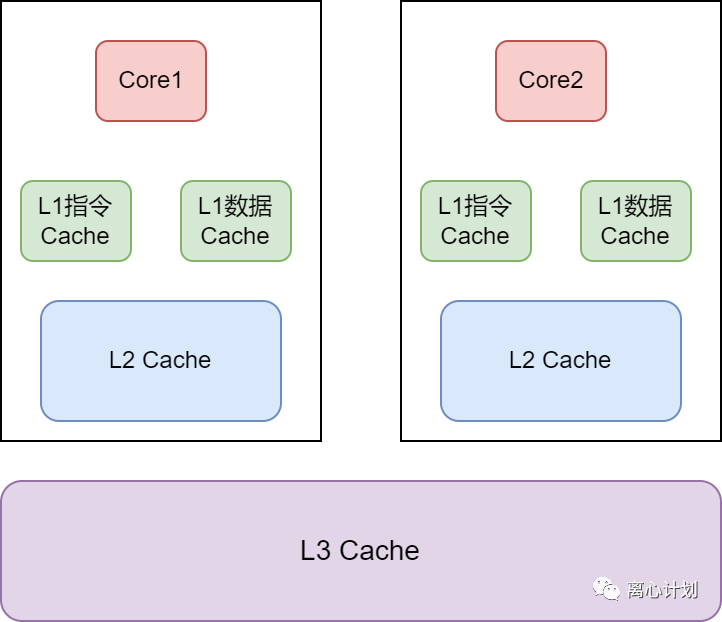
L1和L2是核内私有的,L3是核间共享的。一个经典的Java面试题:Volatile的作用是什么?而由于CPU缓存和线程内存空间之间的数据不一致导致的可见性问题便是Volatile解决的问题之一。
文件系统缓存则是计算机处理磁盘IO下的优化,由于频繁的随机访问磁盘会有大量的寻道、旋转以及数据传输时间,因此在read/write文件时在操作系统和磁盘之间的缓冲区就十分重要。Linux下文件系统Cache分为Page Cache和Buffer Cache两个层面,其中一个Page Cache包含多个Buffer Cache,Buffer Cache主要设计为对块设备io进行数据缓存。磁盘Cache分为预读和回写两个功能,预读就是在对一个文件进行读取的时候,提前预读顺序的后几个Page到Page Cache;回写就是在写文件时将数据暂存在Cache中一并刷到磁盘。
http缓存也是很常见的缓存,常见到大家容易忽视它。如果没有缓存机制,那么每次比较大的静态资源都要重新去服务端拿,这会很冗余。http在返回响应时通过cache-control控制返回的资源浏览器可以缓存的模式,比如:
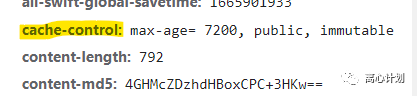
设置为max-age就是允许缓存7200秒,除了这个还会返回一个etag唯一标识这个资源

这样下次去请求时就会携带这个etag信息通过If-None-Match和If-Modify-Since条件判断资源是否过期:

如果没有过期就会返回304告诉浏览器可以直接用上次缓存的资源
旁路缓存的意义
上面列举了常见计算机中的缓存,他们都有一个特点,就是局限在一个体系内,更直接地说就是计算机A上的文件缓存是无法直接被计算机B使用的,而如果把缓存作为一个服务、一个系统以接口的形式提供给其他服务,那么就能实现大家共用,而共用一份数据可以解决很多问题,像分布式锁其实就是不同机器间不同进程的同步。
Redis就是这样一个旁路缓存系统,我们完全可以把它理解为一个数据服务,仅仅提供读写数据而已,如果你搭建一个web项目,只提供一个接口,传递key,value,接口功能就是把key放进hashmap,或者把key从hashmap中拿出来,这就是一个很简易的数据服务,只不过Redis更加强大与完善。
旁路缓存的工作模式
只读缓存
只读缓存故名思意就是只提供读操作,它的基本工作模式是当缓存中数据缺失时就去后端DB中查库并刷新缓存;当DB数据有变更时就先更新数据库然后删除对应的缓存,这样下次请求就会触发缓存缺失主动读取最新数据。只读缓存将最新的数据维护在DB中,缓存不用关心数据的可靠性
读写缓存
读写缓存则是提供读写两种模式,当我们要修改数据时同时修改缓存和DB的值,这样的好处在于最新的数据一直在缓存中,提升了部分读性能;而写操作则其实可以同步写DB和异步写DB,同步表示写缓存和写DB同步进行,都成功后返回给客户端,异步则是为了提高写性能,将写DB的耗时操作放到异步线程。
只读缓存保证了缓存与DB的数据最终一致性,存在下面两种场景:
-
刚写完DB还没删除缓存的一小段gap的不一致
-
写DB成功,删缓存失败导致的不一致
为了保证最终的一致性,mysql可以通过订阅binlog,其他DB相同思路直接借助消息队列发送一个更新数据的消息出来,消费者去实时更新缓存

而读写缓存相对问题就会更多,因为写缓存和写DB无论哪一步先执行,任何一步失败都会出现严重的数据不一致,因此适合对数据一致性要求不高的场景,个人认为就没必要借助其他方式强行原子化两个步骤,反而与提升效率的初衷背道而驰了。
小结
这一小节我们了解了旁路缓存以及旁路缓存的工作模式,Redis作为一款旁路缓存系统,本质是数据服务,我们上面举了一个hashmap的例子粗糙地形容了一下基本读写功能,而Redis作为最受欢迎的旁路缓存,它丰富的数据结构是其地位不倒的重要原因之一,除了字符类型我们有各种奇奇怪怪的存储需求比如队列、集合或者是map甚至是定制的数据结构,本质是服务于业务,因此我们下一节会介绍Redis的基本数据结构,看看Redis是如何高效地利用珍贵地内存资源的。

最后
以上就是殷勤大碗最近收集整理的关于【专栏】基础篇02| Redis 旁路缓存的价值的全部内容,更多相关【专栏】基础篇02|内容请搜索靠谱客的其他文章。








发表评论 取消回复