缓存要解决的问题----通过开辟一个新的数据交换缓冲区,来解决原始数据获取代价太大的问题,让数据更快的能被访问。
缓存原理–基本思想
- 时间局限性原理----被获取过一次的数据未来会被多次引用。
- 以空间换时间-----开辟一块高速独立空间,提供高效访问
- 性能成本----访问延迟越低/性能越高,等容量成本越大。
所以在系统架构设计时成本和性能要兼顾考虑。
缓存原理----优势
-
提升访问性能
-
降低网络拥堵
-
减轻服务负载
-
增强可扩展性
缓存存储原始数据可以提升访问性能,缓存中往往存的是需要访问的中间数据甚至是直接结果,这些数据相比DB中的原始数据小很多,这就减少网络流量,降低了网络拥堵,而且缓存的读写承载能力一般比DB大50到100倍以上,同时又减少了原始数据的解析和计算,大幅降低了服务负载。缓存的读写性能很高,预热快,在数据访问存在瓶颈,突发流量,系统压力增大时可快速上线,流量稳定时,可以快速下线,所以有很强的可扩展性。
缓存原理----代价
- 系统复杂度提升
- 成本增加
- CAP限制
缓存读写模式

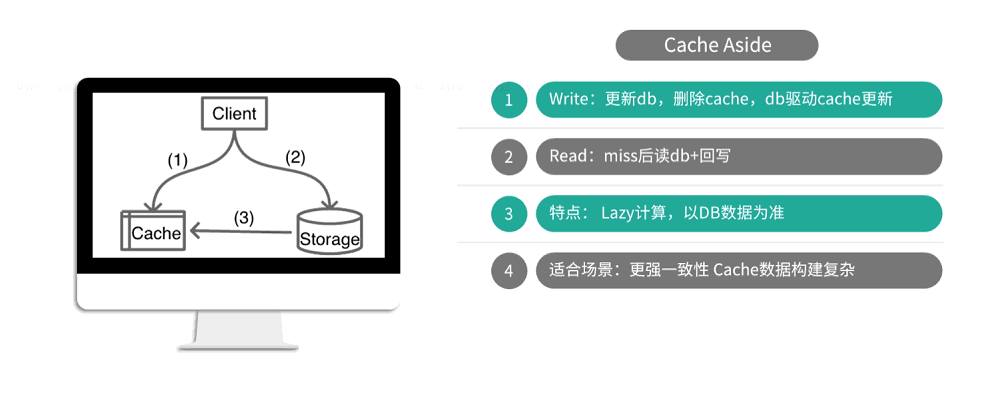
cache aside模式适用于数据一致性要求比较高的,数据构建比较复杂的业务场景。
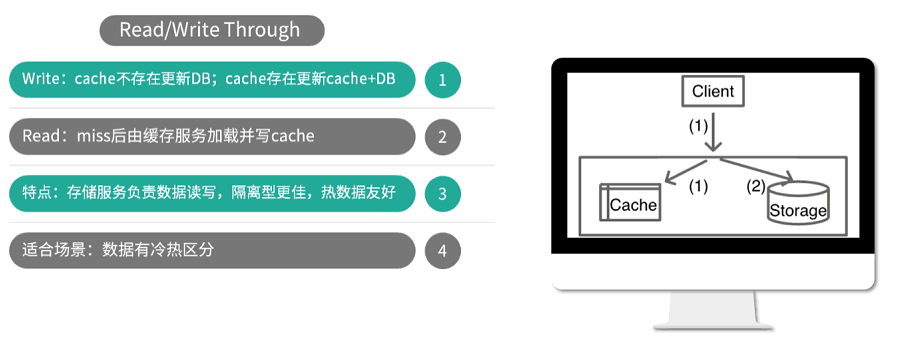
read/write through 这种模式适用于存储服务封装了所有数据处理细节,业务应用端代码只关注业务处理逻辑,系统隔离性增加。

write behind caching这种模式适用于数据的写性能要求非常高,变更特别频繁的业务。对读要求不高的业务
缓存中的经典问题
1.缓存失效:大量key同时过期,cache访问Miss,穿透到DB,DB压力大增,慢查率增大。
- 预先设置固定expire time
- 主动/被动 批量DB加载,写入缓存时,设置预制过期时间
- 到达过期时间,批量一起过期
- 批量请求一起穿透到DB
解决方案:过期时间策略:base时间+random时间
2.缓冲穿透:查询一个不存在的key,每次访问都穿刺到DB,对DB造成压力。
- 系统访问策略,cache Miss后会查DB
- 正常的key,会查询到value并回写
- 正常的key,后续查询会直接命中缓存并返回
- 不存在的key,没有查到value,直接返回NULL
- 不存在的key,后续所有查询都会cacheMiss,全部访问DB
解决方案:查询这些不存在的数据时,第一次查DB没有结果返回null,仍然记录这个key到缓存,这个key对应的value是特殊设置的值(为避免key过多,存一个较短的时间或者将这些不存在的key都存在一个公共的区间,查询时先查询正常的区间,再查非法的key区间,如命中则返回,否则穿透DB,如存在返回到正常key区间,否则返回到非法key区间)。或者构建一个bloomfilter记录全量数据,这样访问数据时可以根据bloomfilter判断这个key是否存在,如不存在直接返回,无需查询DB和缓存
bloomfilter目的检测一个数组是否存在一个集合内,原理如下:
3.缓存雪崩:部分缓存节点不可用,导致整个缓存体系,服务系统不可用的情况

-
缓存不支持rehash导致的系统雪崩不可用(缓存不支持rehash,较多缓存节点不可用,大量cache访问失败,进一步访问DB,DB可承载的访问量只有缓存1-2%以下,DB过载,服务异常)
-
缓存支持rehash导致的缓存雪崩不可用(缓存支持rehsh,流量洪峰到达,大流量key集中在其中1-2个节点,大流量key所在的缓存节点过载crash,异常节点下线,请求rehash,进一步导致其他缓存节点也过载crash,恶性循环,最终整个缓存体系雪崩不可用)
解决方案:增加DB读写开光,慢查询超过阀值,关闭开关,failfast。多副本cache架构,任何cache池miss后,读其他cache副本。实时监控,及时发现并恢复,增加自动故障转移策略
4.数据不一致,cache中的数据与db数据不一致,更新db后,更新cache失败,cache存的是老数据。采用rehash自动偏移策略,在节点多次上下线之后,也会产生脏数据。多个cache副本时,某个缓存副本写异常,更新失败,导致副本间数据不一致
解决方案:cache更新失败后,重试or延迟删除。调短过期时间,db重新加载,最终一致性。拒绝rehash漂移,采用缓存分层策略
5.数据并发竞争高并发访问场景,缓存miss,并发到db查相同key,大量并发请求相同key,key在cache中不存在。进程加载没有协调,并发查询db,db压力大增。
解决方案:缓存miss后,加全局锁,唯一进程查DB,并回写。其他进程查询,若缓存miss,先查是否被锁定,发现有锁就等待。等加锁进程回写完毕后,从缓存加载。或者对缓存数据保存多个备份,减少miss的概率。
6.Hot Key : 突发热门事件,特定key所在的cache节点服务过载、卡顿、cache。(突发热门事件,超大量请求集中访问热门事件对应的key,10W-100W+用户一起访问,流量集中打在一个cache节点机器,达到物理网卡、带宽
CPU极限、从而导致服务异常)
解决方案:找出Hot key,预先评估重要节假日相关key、秒杀活动的商品、集中推送的内容。批处理任务离线计算,找出最近历史最高频关键词(hadoop)。流任务实时分析,及时发现新发布的热门数据(spark)找到hot key后进行拆分。
7.Big key:bigkey存mc,对应的slab较少,导致频繁被剔除,db反复加载。key的value过大,如果此类型key被大量访问,缓存组件的带宽、网卡被打满。key存储的字段过多,每个字段变更都需要对缓存数据进行变更,读写相互影响。key如果被缓存系统淘汰,db加载需要查询大量数据,加载时间长。
解决方案:若数据存在mc(memcached)中,设置缓存阈值,超过阈值即启用压缩。启动后预写足够数量大的key,预支配对应slab.若存在Redis中,client序列化,restore一次写入。其他方案 将bigkey 分拆为多个小key同时尽量避免big kv过期或剔除
本文参考陈波( 新浪微博平台架构技术专家)分布式缓存的分享课,主要用途为记录经典问题的场景和解决的方案以共分享参考。
最后
以上就是过时小刺猬最近收集整理的关于缓存的读写模式及经典问题缓存中的经典问题的全部内容,更多相关缓存内容请搜索靠谱客的其他文章。








发表评论 取消回复