前言
在互联网后端架构中,缓存是一种非常常见的解决方案,它有效解决了以下场景:
- 请求数过多,打垮数据库,缓解数据库压力。
- 降低调用第三方api出错率。
- 某些极端场景下,有效可靠的降级方案。
- 缓存的设计和实现,在架构上一般可以分2级。为什么不做3级,如果觉得有必要做,可以做,但是目前这种场景还很少。
正文
一级缓存,最常规的方案,就是Redis。Redis是分布式一级缓存,多api节点可以共用redis,使得缓存源一致。一级缓存作用显而易见,是为了缓解数据库压力。
二级缓存,是api节点内存。二级缓存的作用,是降低redis通信io,降低序列化成本。
在使用缓存时,务必遵循一个原则:
只要是缓存,必定要追加失效机制,禁止使用永久不失效缓存。
整个缓存体系,在后端架构中,如图:
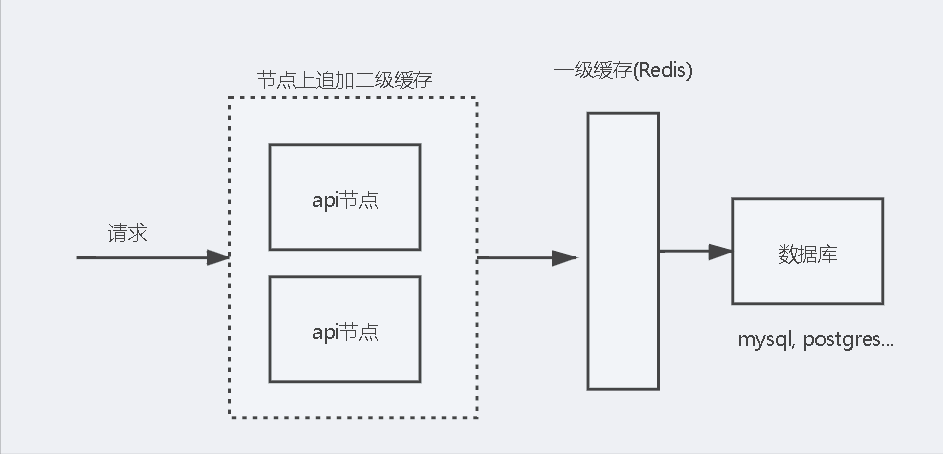
一个缓存设计,让团队的效能得到了明显的提升
规范特征
使用缓存必须要遵循的规范
缓存的使用,一定要遵循一些规范。群魔乱舞的设计,必然会导致维护隐患。健康的缓存设计,有哪些规范呢?
读取策略
-
先从二级缓存中读取,找到了则返回。
-
再从一级缓存中读取,找到了则返回,并追加进二级缓存。
-
最后,从数据库中读取,找到了则返回,并追加进一级缓存,二级缓存。
最重要的是,不论是一级缓存,还是二级缓存,永远应该统一在读取时,被注入。而不是在真实数据源修改时,同步注入。因为修改的场景,是并发的,那么可能存在后修改的操作,被先注入,导致缓存脏了。
失效期
缓存,是作为真实数据源的降级方案,它背后必须有真实可靠的数据源,一般是数据库。
一级缓存,以Redis为例,建议失效时间为5-12分钟随机时间失效。
二级缓存,以应用内存为例,建议失效时间,为固定15秒。
没有失效期,会有哪些后果?
第一,缓存一旦出现不一致,将会永久不一致。在发现不一致和改正的过程,是非常花时间的。不论是使用了怎样的缓存策略,都有可能出现不一致。毕竟redis不是强事务保证。
第二,在缓存模型,增减字段时,当user_info缓存中追加了字段age,要如何给不失效的缓存追加上这个字段是一个经典问题。最佳实践是,给缓存key追加版本,假设原来的10086用户为
key: user_info:10086
value: {“id”:1, “username”:“张三”}
追加版本后,为
key: user_info:v2:10086
value: {“id”:1, “username”:“张三”, “age”:18}
总而言之,旧key丢弃,等待自然失效。新key投入使用。而不是蠢蠢得,懒加载等用户读到了缓存后,再修改缓存内容,设置回原来的key中。
第三,Redis存在静默删除冷key,不热门key的机制,永久不删除的缓存存在被意外删除的场景。
第四,关于状态。如果Redis内的数据存在永久不失效的,那么这个Redis是一个有状态的redis,如果Redis内数据全部都有失效期,那么它是一个无状态的。对一个无状态的Redis,当存在数据库迁移时,比如单点redis升迁集群,无状态的redis可以直接切,无须考虑切换策略。对有状态的Redis,需要执行数据迁移计划,存在影响流量的风险。
删除策略
一级缓存和二级缓存,遵循不同的删除策略。
一级缓存存在两种删除场景。第一,数据库记录存在修改,那么一级缓存应该被删除,并且此时不应该重新注入,而应该等待二次查询时懒注入。第二,一级缓存自然失效,那么它也被删除了。
二级缓存存在两种删除场景。第一,15秒后自然失效。第二,一级缓存存在修改/删除。
哪些数据能开二级缓存
二级缓存,是应用内缓存,属于伪状态。那么,当数据源修改时,我们要怎么通知所有应用几点二级缓存更新呢?
一般不通知,二级缓存删除的操作会被绑定进删除一级缓存的方法中,假设应用节点有3个,那么请求通过负载均衡打入某一个节点,那么该节点的二级缓存会被有效删除,其它两个节点,存在随机0-15秒幻读。
所以,哪些数据能开二级缓存,哪些数据不能,必须有明确规定。在业务开发中,我们往往将业务模型抽象为两类: 配置类,进度类。配置类表名往往以config结尾,进度类我们以process结尾。
以config结尾的数据,可以开二级缓存。也就是,大部分配置都可以开。因为它较少修改,并且修改后,允许15秒内渐渐生效,.15秒后完全生效。
以process结尾的数据,禁止开二级缓存。因为它存在实时运算,比如商城限购2次,那么限购次数作为进度里的字段,是要避免出现幻读的。
设计和使用
在设计缓存时,大多数时候,我们都知道它的原理是一致的,但是现实是,每个人实现的样式不一样,带来的维护成本,和故障链路查询成本,都非常高。以下是我见过的群魔乱舞的缓存设计场景:
-
读写分离。 数据源的读取和写入,放进了两个项目里,两个仓库。
-
重复设计。先按照缓存定义,实现了某一个业务模型的缓存,等下一个场景又需要缓存时,继续仿照第一个,重复设计,周期*2。
-
无预判。在设计时,已经了解到是一个c端请求模型,可是到处修改,跨服务改,导致后续无法追加缓存。因为无法统计到修改场景,导致缓存更新上存在不一致。
这些设计方式,统统都能够正确实现缓存,可是实现过程,和上手成本,从实际出发,真的太高了。当你的缓存设计出来以后,需要扪心自问3个问题:
这个缓存维护简单吗?
这个缓存,新手来写会写吗?
这个缓存,在增加字段,缓存数据迁移,缓存雪崩,缓存穿透上,改起来简单吗?
一个合理的缓存设计,就是对开发使用人来说,只关注两个值【缓存key】【二级缓存开关】。其它任何的过程实现,都不应该让开发人员循环参与实现。
show me your code
团队中,我们使用了【代码生成】作为缓存设计必用工具。
当我们在数据库中见好了表后,我们使用代码生成,产出了go语言的模型
import mc "github.com/fwhezfwhez/model_convert"
func TestTableToStructWithTag(t *testing.T) {
dataSouce := fmt.Sprintf("host=%s port=%s user=%s dbname=%s sslmode=%s password=%s", "localhost", "5432", "postgres", "testdb", "disable", "123")
tableName := "match_info"
fmt.Println(mc.TableToStructWithTag(dataSouce, tableName, map[string]interface{}{
"dialect": "postgres",
"${db_instance}": "db.DB",
"${db_instance_pkg}": "path/to/db",
}))
}
产出
type MatchInfo struct{
... // 省略了字段说明
}
var MatchInfoRedisKeyFormat = "xyx:match_info:%s:%d"
// 1级缓存key, 二级缓存key
func (o MatchInfo) RedisKey() string {
// TODO set its redis key and required args
return fmt.Sprintf(MatchInfoRedisKeyFormat, config.Mode, o.GameId)
}
// 一级缓存失效时间
func (o MatchInfo) RedisSecondDuration() int {
return int(time.Now().Unix()%7+5) *60
}
const (
// 单条记录二级缓存开关
MatchInfoCacheSwitch = true
// 记录集二级缓存开关
ArrayMatchInfoCacheSwitch = false
)
func (o *MachInfo) MustGet(conn redis.Conn, engine *gorm.DB) error {
.... // 省略了实现过程
}
// 以下省略了大部分缓存设计
所以,由上可见,当一个模型在技术评审时,定性为客户端c端模型,那么它必然要有缓存策略,那么它必然得按照代码生成来制定。
以上产出代码,使用人,只需要关注修改【缓存key】【二级缓存开关】。其它都按照默认值即可。
代码实现的详情,可以自行尝试,框架是开源框架。
它是怎么做到追加字段的?
xyx:match_info:%s:%d => xyx:match_info:v2:%s:%d // 弃用旧key,唤起新key
它是怎么做到防止缓存雪崩的?
int(time.Now().Unix()%7+5) *60 // 随机5-12分钟失效
它是怎么做到防止缓存穿透的?
这个在被省略的缓存设计中,核心原理是查询缓存查询数据库都查不到时,缓存注入一个【Disable】值。当查询到Disable时,自动返回找不到。
产能
在统一了缓存规范和工具后,每个业务模型上,节省了700-900行代码,并且对新人在缓存设计和使用上,几乎没有了门槛。哪怕是一个0基础刚刚学会编程的人,也可以很好得实现具备缓存的接口。
在团队中,这个方案带来的价值非常重量级。新人从学习到上手设计出合理规范的缓存,只花了一个小时学习,就能跟进c端项目了。
最后
以上就是疯狂路灯最近收集整理的关于【最佳实践】一个缓存设计,让团队的效能得到了明显的提升的全部内容,更多相关【最佳实践】一个缓存设计,让团队内容请搜索靠谱客的其他文章。








发表评论 取消回复