P.S. 对于第十章并发内容,课上听得不是很明白。课下学习了一下老师的讲义和英文讲义Reading 19:Concurrency,粗浅地总结下。
两种并发编程模型
共享内存(shared memory)和信息传递(message passing)
共享内存
在并发的共享内存模型中,并发模块通过在内存中读取和写入共享对象来进行交互。
共享内存模型的示例:
A和B可能是同一台计算机中的两个处理器(或处理器核心),共享相同的物理内存。
A和B可能是在同一台计算机上运行的两个程序,它们共享一个公共文件系统,包含可以读写的文件。
A和B可能是同一Java程序中的两个线程(我们将解释下面的线程),共享相同的Java对象。
信息传递
在消息传递模型中,并发模块通过通信信道相互发送消息进行交互。模块发送消息,并将每个模块的传入消息排队等待处理。例子包括:
A和B可能是网络中的两台计算机,通过网络连接进行通信。
A和B可能是Web浏览器和Web服务器 - A打开与B的连接并请求网页,B将网页数据发送回A.
A和B可能是即时消息客户端和服务器。
A和B可能是在同一台计算机上运行的两个程序,其输入和输出已通过管道连接,就像ls | grep键入命令提示符一样。
进程、线程和时间片
进程(process)
进程是与同一台计算机上的其他进程相独立 (isolated) 的正在运行的程序的实例。特别是,它有自己的机器内存的私有部分。
进程被抽象为一台虚拟机。它使程序感觉它拥有整个机器本身 - 就像一台新的计算机已经创建,具有全新的内存,只是为了运行该程序。
就像通过网络连接的计算机一样,进程之间通常不共享内存。一个进程无法访问其他进程的内存或对象。在大多数操作系统上,进程之间可以共享内存,但需要特殊的操作。相比之下,新进程自动为消息传递做好准备,因为它是使用标准输入和输出流创建的,即Java中使用的System.out流和System.in流。
线程(thread)
线程是正在运行的程序内的控制位置(a locus of control inside a running program)。可以把它想象成正在运行的程序中的一个位置,以及导致该位置的方法调用栈(因此线程可以在到达return语句时返回栈)。
就像进程代表虚拟机一样,线程被抽象为虚拟处理器。创建一个新线程被抽象为 (simulates) 在该进程所代表的虚拟机内部创建一个新的处理器。这个新的虚拟处理器运行相同的程序,并与进程中的其他线程共享相同的内存。
线程自动为共享内存做好准备,因为进程中的内存被所有线程共享。使一个线程拥有私有的内存需要特别的操作。显示的设置信息传递很有必要,这要通过创建和使用队列这种数据结构。我们将在未来的阅读中讨论如何做到这一点。
无论何时运行Java程序,程序都以一个线程开始,该线程main()作为第一步调用。该线程称为主线程。
时间片(time slicing)
如何在只有一个或两个处理器的计算机中拥有许多并发线程?当线程数多于处理器时,通过时间片模拟并发性,这意味着处理器要在线程之间切换。下图显示了如何在只有两个实际处理器的机器上对三个线程T1,T2和T3进行时间分片。在图中,时间向下进行,因此首先一个处理器运行线程T1而另一个处理器运行线程T2,然后第二个处理器切换到运行线程T3。线程T2暂停到下一个时间片,在同一处理器或另一个处理器上。图的最右边部分显示了每个线程的视角。有时一个线程正在处理器上主动运行,有时它会被暂停,等待下一次机会,在某个处理器上运行。
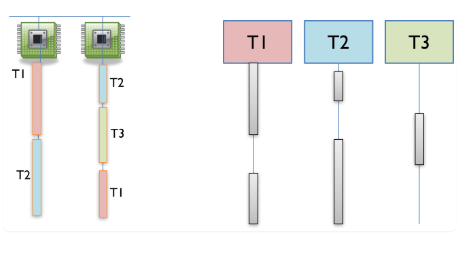
在大多数系统上,时间切片以不可预测和不确定的方式发生,这意味着线程可能随时被暂停或恢复。
在Java中启动一个线程
你可以通过创建Thread并告诉它的实例来启动新线程的start()方法,也可以通过创建一个实现接口Runnable的类来为要运行的新线程提供代码。新线程要做的第一件事是调用此类中的run()方法。例如:
// ... in the main method:
new Thread(new HelloRunnable()).start();
// elsewhere in the code
public class HelloRunnable implements Runnable {
public void run() {
System.out.println("Hello from a thread!");
}
}
但比较常用的是匿名类:
new Thread(new Runnable() {
public void run() {
System.out.println("Hello from a thread!");
}
}).start();
匿名类的部分比较简单,这里跳过了。
共享内存示例:
我们来看一个共享内存系统的例子。这个例子的要点是表明并发编程很难,因为它可能有微妙的错误。
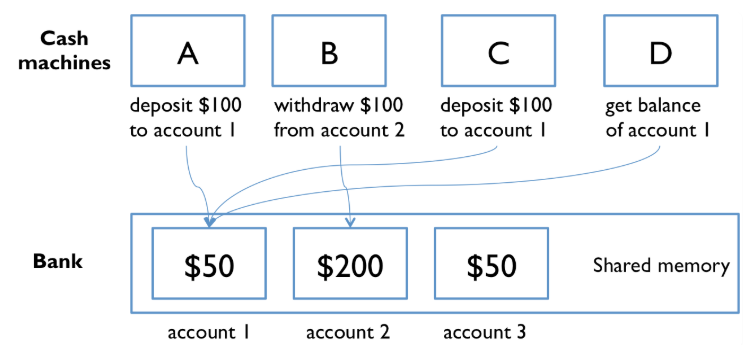
想象一下,银行拥有使用共享内存模型的自动提款机,因此所有自动提款机都可以在内存中读取和写入相同的帐户对象。
为了说明可能出现的错误,让我们简化了银行下降到一个帐户,与存储在一美元平衡balance变量,两个操作deposit和withdraw简单地添加或删除一美元:
// suppose all the cash machines share a single bank account
private static int balance = 0;
private static void deposit() {
balance = balance + 1;
}
private static void withdraw() {
balance = balance - 1;
}
客户使用自动提款机进行以下交易:
deposit(); // put a dollar in
withdraw(); // take it back out
每笔交易只需存款一美元,然后是提款一美元,因此应该保持账户余额不变。整天,我们网络中的每台自动提款机都在处理一系列存款/取款交易:
// each ATM does a bunch of transactions that
// modify balance, but leave it unchanged afterward
public static void cashMachine() {
new Thread(new Runnable() {
public void run() {
for (int i = 0; i < TRANSACTIONS_PER_MACHINE; ++i) {
deposit(); // put a dollar in
withdraw(); // take it back out
}
}
}).start();
}
在一天结束时,无论现金机运行了多少,或者我们处理了多少交易,我们都应该预计帐户余额仍为0。
但是如果我们运行这段代码,我们会经常发现一天结束时的余额不是 0.如果创建的多个线程cashMachine()同时运行 - 例如,在同一台计算机上的不同处理器上 - 那么balance可能不会在一天结束时为零。
交错
这件事很可能发生。假设两个取款机线程A和B同时处理存款。以下是该deposit()步骤通常分解为低级处理器指令的方式:
获得balance(余额 = 0)
加1
写回结果(余额 = 1)
当A和B同时运行时,这些低级指令相互交错(某些甚至可能在某种意义上是同时的,但现在让我们担心交错):

这种交错结果很好——我们最终得到balance的值为2,所以A和B同时存入了一美元。但如果交错是这样的:

现在余额为1——A的美元已经丢失!A和B都同时读取余额,计算单独的期末余额,然后竞相存储新的余额,却未能将对方的存款考虑在内。
竞争条件
这是竞争条件的一个例子。一个竞争条件意味着程序的正确性(即对后置条件和不变的满足)依赖于并行计算A和B。当发生这种情况时,我们说“A与B产生竞争”
一些事件的交错可能是正常的,因为它们与单个非并发进程产生的一致,但是其他交错产生错误的答案 - 违反后置条件或不变量。
调整代码无济于事
所有这些版本的银行账户代码都具有相同的竞争条件:
// version 1
private static void deposit() { balance = balance + 1; }
private static void withdraw() { balance = balance - 1; }
// version 2
private static void deposit() { balance += 1; }
private static void withdraw() { balance -= 1; }
// version 3
private static void deposit() { ++balance; }
private static void withdraw() { --balance; }
你不能仅仅通过查看Java代码来推断处理器将如何执行它。你无法分辨出不可分割的操作(即原子操作)将是什么。它不是原子(atomic)的,因为它是Java的一行。它只触及balance一次,因为balance标识符只出现在行中一次。Java编译器,实际上是处理器本身,不会对它将从代码生成的低级操作做出任何承诺。实际上,典型的现代Java编译器为所有这三个版本生成完全相同的代码!
关键是你无法通过观察表达式来判断它是否对竞争条件安全。
阅读材料:线程干扰 (仅一页)
重新排序
事实上,情况甚至更糟。银行账户余额的竞争条件可以根据不同处理器上的顺序操作的不同交错来解释。但实际上,当您使用多个变量和多个处理器时,您甚至无法依赖于以相同顺序出现的那些变量的更改。
这是一个例子。请注意,它使用循环连续检查并发条件; 这称为忙碌等待,这不是一个好的模式。在这种情况下,代码也被破坏:
private boolean ready = false;
private int answer = 0;
// computeAnswer runs in one thread
private void computeAnswer() {
// ... calculate for a long time ...
answer = 42;
ready = true;
}
// useAnswer runs in a different thread
private void useAnswer() {
// busy-wait for computeAnswer to say it's done
while (!ready) {
Thread.yield();
}
if (answer == 0) throw new RuntimeException("answer wasn't ready!");
}
我们有两种方法在不同的线程中运行。 computeAnswer进行长时间的计算,最后得出答案42,它存储在answer变量中。然后它将ready变量设置为true,以便向另一个线程中运行的方法发出信号useAnswer,表明答案已准备好供其使用。查看代码,answer设置之前ready设置,所以一旦useAnswer看到ready为真,那么它可以假设answer它将是42,这似乎是合理的吗?不是这样。
问题是现代编译器和处理器做了很多事情来快速编写代码。其中的一个是创造一个变量的副本,存储在更快的存储中(处理器寄存器或处理器高速缓存),在将他们存回内存中真正位置之前,暂时地操作他们。回调的顺序可能与代码中操作变量的顺序不同。这是可能在幕后发生的事情(但用Java语法表达以表明它)。处理器有效地创建了两个临时变量,tmpr并且tmpa,操纵字段ready和answer:
private void computeAnswer() {
// ... calculate for a long time ...
boolean tmpr = ready;
int tmpa = answer;
tmpa = 42;
tmpr = true;
ready = tmpr;
// <-- what happens if useAnswer() interleaves here?
// ready is set, but answer isn't.
answer = tmpa;
}
信息传递示例:
现在让我们看看我们的银行帐户示例的消息传递方法。
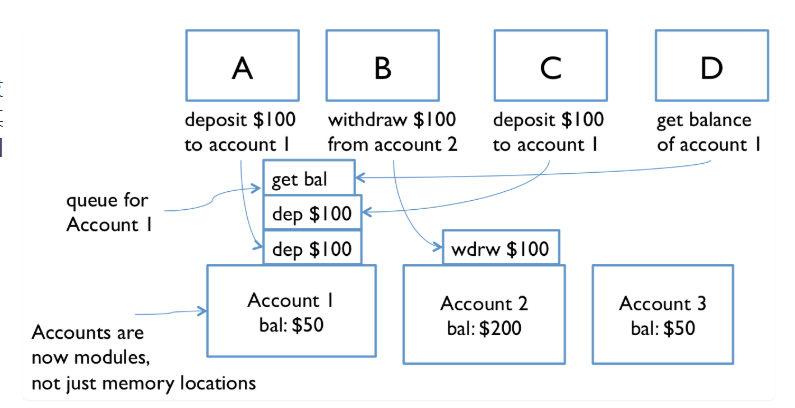
现在不仅每台取款机都是模块,而且每个帐户也是一个模块。模块通过彼此发送消息进行交互。传入请求被放入队列中以便一次处理一个。发送方在等待其请求的回答时不会停止工作。它处理来自自己队列的更多请求。对其请求的回复最终会以另一条消息的形式返回。
不幸的是,消息传递并没有消除竞争条件的可能性。假设每个帐户支持get-balance和withdraw操作,并带有相应的消息。自动提款机A和B的两个用户都试图从同一帐户中提取一美元。他们首先检查余额,以确保他们从不提取超过账户持有的余额,因为透支会触发银行的处罚:
get-balance
if balance >= 1 then withdraw 1
问题是再次交错,但这次交错发送到银行帐户的消息,而不是A和B执行的指令。如果帐户以一美元开头,那么消息的交错会欺骗A和B以为他们都可以提取一美元,从而透支账户?
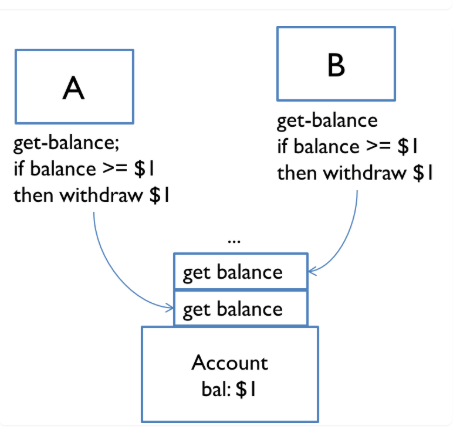
这里的一个教训是,你需要仔细选择消息传递模型的操作。 withdraw-if-sufficient-funds将是一个比仅仅更好的操作withdraw。
并发很难测试和调试
并发真的很棘手。使用测试发现竞争条件非常困难。即使测试发现了一个错误,也可能很难将其本地化到导致它的程序部分。
并发错误表现出非常差的可重复性。很难让它们以同样的方式发生两次。指令或消息的交织取决于受环境强烈影响的事件的相对时间。延迟可能是由其他正在运行的程序,其他网络流量,操作系统调度决策,处理器时钟速度的变化等引起的。每次运行包含竞争条件的程序时,你可能会得到不同的行为。
这些类型的bug是heisenbugs,它们是不确定的并且难以复制,而不是bohrbug,它会在你看到它时反复出现。顺序编程中的几乎所有错误都是bohrbugs。
当您尝试用println调试器或调试器查看时,heisenbug甚至可能会消失!原因是打印和调试比其他操作慢得多,通常慢100-1000倍,它们会显着改变操作的时间和交错。所以在下面插入一个简单的print语句cashMachine():
public static void cashMachine() {
new Thread(new Runnable() {
public void run() {
for (int i = 0; i < TRANSACTIONS_PER_MACHINE; ++i) {
deposit(); // put a dollar in
withdraw(); // take it back out
System.out.println(balance); // makes the bug disappear!
}
}
}).start();
}
…突然,balance总是为0,正如你想要的那样,并且错误似乎消失了。但它只是掩盖了,而不是真正固定的。程序中其他位置的时间变化可能会突然使错误恢复。
并发很难做到正确。这篇阅读的部分内容是吓唬你。在接下来的几个Reading中,我们将看到设计并发程序的原则性方法,以便它们更安全地避免这些类型的错误。
总结
- 并发:同时运行多个计算
- 共享内存和消息传递范例
- 进程和线程:进程就像一台虚拟机; 线程就像一个虚拟处理器
- 竞争条件:结果的正确性(后置条件和不变量)取决于事件的相对时间
这些要点以糟糕的方式关联软件的三个关键属性。并发是必要的,但它会导致严重的正确性问题。我们将在接下来的几个Reading中解决这些问题。
最后
以上就是独特煎蛋最近收集整理的关于并发Concurrency两种并发编程模型进程、线程和时间片在Java中启动一个线程共享内存示例:信息传递示例:总结的全部内容,更多相关并发Concurrency两种并发编程模型进程、线程和时间片在Java中启动一个线程共享内存示例内容请搜索靠谱客的其他文章。








发表评论 取消回复