文章目录
- 背景
- Best Practice 1: Release Code for the Training Pipeline(s) you use
- Best Practice 2: Release Code for Your NAS Method
- Best Practice 3: Don’t Wait Until You’ve Cleaned up the Code; That Time May Never Come
- Best Practice 4: Use the Same NAS Benchmarks, not Just the Same Datasets
- Best Practice 5: Run Ablation Studies
- Best Practice 6: Use the Same Evaluation Protocol for the Methods Being Compared
- Best Practice 7: Compare Performance over Time
- Best Practice 8: Compare Against Random Search
- Best Practice 9: Validate The Results Several Times
- Best Practice 10: Use Tabular or Surrogate Benchmarks If Possible
- Best Practice 11: Control Confounding Factors
- Best Practice 12: Report the Use of Hyperparameter Optimization
- Best Practice 13: Report the Time for the Entire End-to-End NAS Method
- Best Practice 14: Report All the Details of Your Experimental Setup
- 未来的期待
- 总结
Best Practices For Scientific Research On Neural Architecture Search
网址 : http://automl.org/nas_checklist.pdf
背景
神经架构搜索是自动机器学习中最热门的领域之一,有逐渐上升的趋势。下图是最近几年的相关文献数量。
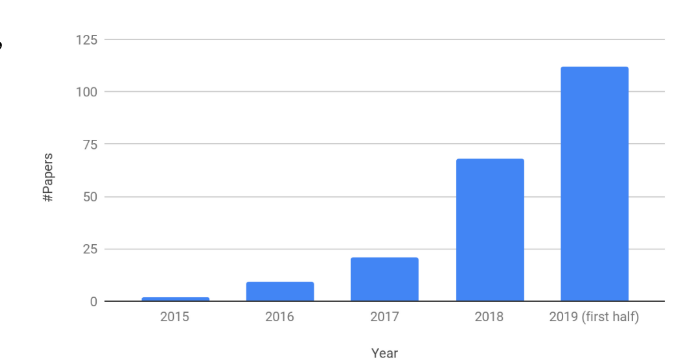
为了NAS的可持续性发展,也是为了能够更准确、公平地比较NAS算法。本文从以下几个方面进行阐述。
Best Practice 1: Release Code for the Training Pipeline(s) you use
Training pipeline比一个性能优异的模型更为重要。因为training pipeline包括了训练过程中的各种细节,有些时候,我们即使得到了模型、了解了训练的方法也无法得到与原论文中同样的效果,就是因为原论文中的细节没有说清楚:比如图像数据集中的优化器、正则化方法、学习率的变化、数据增强、权重衰减等各个方面。
所以说两篇论文只有在同一个training pipeline中才能进行比较,对发表的论文来说,开源一个training pipeline是非常重要的。
Best Practice 2: Release Code for Your NAS Method
有可用源代码的论文往往更具有影响力。
Best Practice 3: Don’t Wait Until You’ve Cleaned up the Code; That Time May Never Come
不要总是想着等把代码优化之后再开源,这句话往往意味着不开源。当然,如果可以优化后开源会更好,但是我们鼓励直接开源代码,简单说明代码的作用就好,可以等有时间再仔细整理。开源的好处如下:
- 许多顶会如NeurIPS 2019更多的要求reproducibility(可复现性)。这会影响论文的接受率。
- 在工业研究实验室的招聘中,共享代码的渐进策略具有竞争优势。
Best Practice 4: Use the Same NAS Benchmarks, not Just the Same Datasets
NAS的方法通常是会用一个大表对模型的各个方面进行比较,然而由1可知,他们并无法客观公平地比较。因此我们定义了一个NAS Benchmark:
NAS基准测试由一个数据集(带有预定义的训练、测试集划分)、一个搜索空间和可用的可运行代码组成,这些代码具有用于训练体系结构的预定义超参数。
以下是NAS Benchmark的两个示例:
- DARTS (Liu et al., 2019b)
- NAS-Bench-101 (Ying et al., 2019)
Best Practice 5: Run Ablation Studies
现存的NAS方法有的修改了方法、有的修改了基准,我们并不确定是否是方法本身的好坏影响了结果。所以如何量化那些改变尤为重要。因此,建议做消融实验验证单个算法组件的重要性。
Best Practice 6: Use the Same Evaluation Protocol for the Methods Being Compared
简单的训练、验证和测试集的划分。
Best Practice 7: Compare Performance over Time
随着时间的推移得到不同的网络性能。
Best Practice 8: Compare Against Random Search
如题,一些论文中,在一个好的初始化的前提下,随机的方法也会得到非常好的效果。
Best Practice 9: Validate The Results Several Times
NAS的方法总是随机的,即使重复运行相同的代码也不一定会出现相同的结果。所以需要多次验证结果。
Best Practice 10: Use Tabular or Surrogate Benchmarks If Possible
对于大部分研究者,无法满足NAS需要的超大规模的计算资源,所以尽可能使用代理的基准进行测试。
Best Practice 11: Control Confounding Factors
即使使用相同的Benchmark,结果的表现也会被一些其他因素影响,如:硬件设备、深度学习库的版本、运行各种方法的时间等。
Best Practice 12: Report the Use of Hyperparameter Optimization
我们应该注意超参数的影响,在论文中详细的写清楚。
Best Practice 13: Report the Time for the Entire End-to-End NAS Method
与7相关,我们注意到NAS方法的时间必须以端到端方式测量,即,从启动NAS方法到返回最终架构之间的时间。如果不同的NAS方法运行方式不同,这一点尤其重要(参见6)。特别是,一些NAS方法在第一阶段之后提出多个潜在的体系结构,然后在验证阶段从这些体系结构中选择最终的体系结构。在这种情况下,除了报告各个阶段的时间外,还必须将验证阶段所需的时间计算为NAS方法所用的总时间的一部分。
Best Practice 14: Report All the Details of Your Experimental Setup
目前,NAS的主要关注点之一是更快地获得良好的架构。因此,结果通常包括实现的准确性(或类似的度量标准)和实现这些结果所需的时间。然而,为了评估和重现这些结果,了解所使用的硬件(GPU/TPU的类型等)以及深度学习库及其版本是很重要的。如果方法A需要的时间是方法B的两倍,但是方法A是在旧的GPU上评估的,而方法B是在新GPU上评估的,那么GPU的差异可以解释整个速度的差异。总的来说,我们建议报告所有顶级机器学习会议所需要的重现结果的所有细节,这样就可以有一个很长的附录,这样就没有理由省略这些细节了。
未来的期待
-
需要适当的NAS基准测试
-
需要一个NAS方法的开源库
总结
以上都是为了公平、有效地评价一个算法,不仅是说有计算资源就能出好的结果,更多是对方法的创新。也能看出目前的方法没有一个很好的规范,未来需要大量的工作不断努力。
最后
以上就是曾经睫毛膏最近收集整理的关于Best Practices For Scientific Research On Neural Architecture Search神经架构搜索规范的全部内容,更多相关Best内容请搜索靠谱客的其他文章。

![[GRE] 填空经典1290题 错题(五)](https://www.shuijiaxian.com/files_image/reation/bcimg15.png)






发表评论 取消回复