零、算法原理

一、导入标准库
In [2]:
# Importing the libraries 导入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 使图像能够调整
%matplotlib notebook
#中文字体显示
plt.rc('font', family='SimHei', size=8)
二、导入数据
In [8]:
dataset = pd.read_csv('Ads_CTR_Optimisation.csv') # 数据表示虚拟环境,模拟我将投放哪些广告
dataset
Out[8]:
问题描述
三、每个用户随机抽选广告得到的点击数
In [27]:
import random
N = 10000 # 1000个用户
d = 10 # 10个广告
ads_selected = [] # 广告选择
total_reward = 0
for n in range(0, N): # 每个用户循环
ad = random.randrange(d) # 随机选择广告
ads_selected.append(ad) # 将选择的广告加入list中
reward = dataset.values[n, ad] # 取出数据集中n行ad列查看是否命中,命中值为1,未命中值为0(1即为奖励)
total_reward = total_reward + reward # 每轮奖励累计相加
print(total_reward)
# 画图
plt.hist(ads_selected)
plt.title(u'广告选择直方图')
plt.xlabel(u'广告')
plt.ylabel(u'每个广告的点击数')
plt.show()
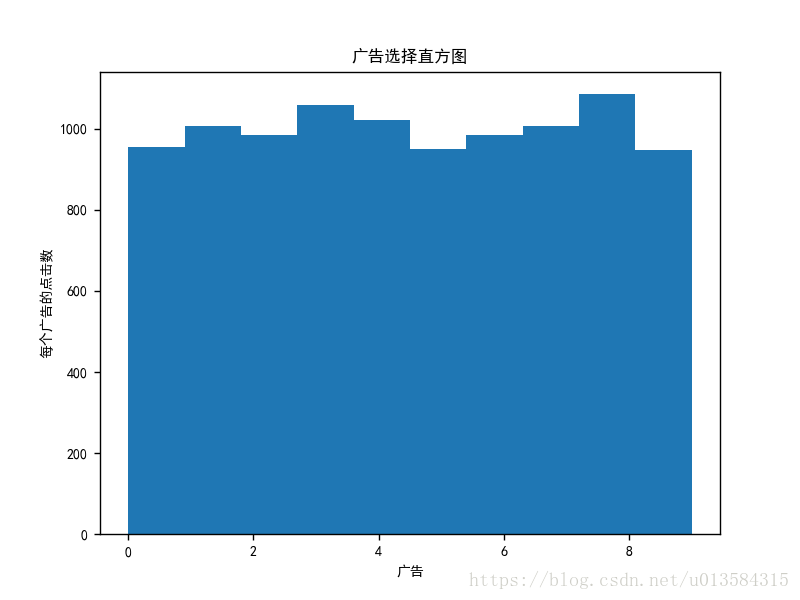
图中我们可以看到,由于是随机的,10000个人选择10种广告,每个人平均会在1000次左右
四、置信区间上界算法
In [55]:
import math
N = 10000 # 1000个用户
d = 10 # 10个广告
ads_selected = [] # 广告选择
numbers_of_selections = [0] * d # 多项选择
sums_of_rewards = [0] * d # 奖励总和
total_reward = 0
for n in range(0, N): # 第n个用户
ad = 0 # 广告初始化
max_upper_bound = 0 # 最大上界初始化
for i in range(0, d): # 第i个广告
if (numbers_of_selections[i] > 0):
average_reward = float(sums_of_rewards[i]) / float(numbers_of_selections[i]) # 平均奖励,这里如果python2记得用float
delta_i = math.sqrt(3/2 * math.log(n + 1) / numbers_of_selections[i]) # 置信区间
upper_bound = average_reward + delta_i # 置信区间上界
# print(average_reward)
# print(delta_i )
else:
upper_bound = 10000
if upper_bound > max_upper_bound:
max_upper_bound = upper_bound
ad = i
# print(ad)
ads_selected.append(ad)
numbers_of_selections[ad] = numbers_of_selections[ad] + 1
reward = dataset.values[n, ad]
sums_of_rewards[ad] = sums_of_rewards[ad] + reward
total_reward = total_reward + reward
# print(ads_selected)
print(total_reward)
# print(numbers_of_selections)
# print(sums_of_rewards)
In [56]:
# 画图
plt.hist(ads_selected)
plt.title(u'广告选择直方图')
plt.xlabel(u'广告')
plt.ylabel(u'每个广告的点击数')
plt.show()
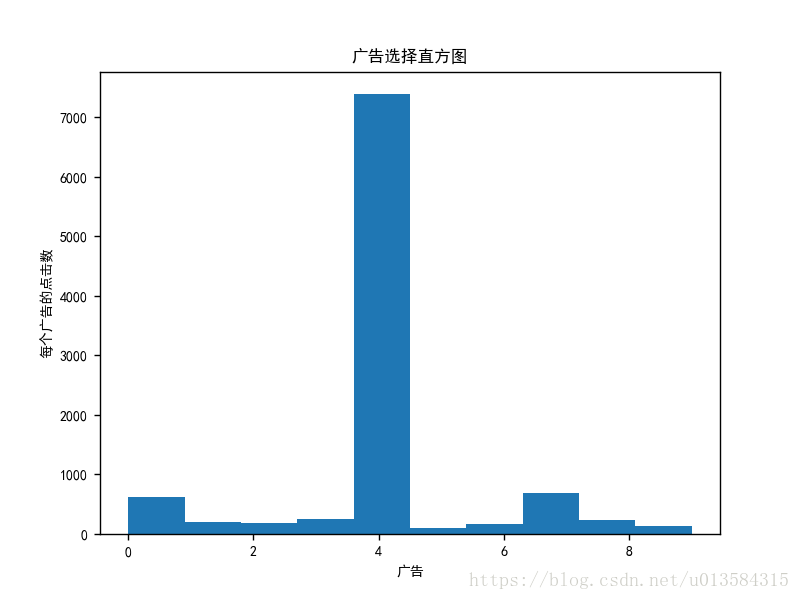
从图中可以看到,广告5被点击数明显比较多。总奖励也提高了一倍,证明我们的算法很NB
五、项目地址
https://coding.net/u/RuoYun/p/Python-of-machine-learning/git/tree/master/00%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/5.%E8%BF%9B%E9%98%B6%E7%AE%97%E6%B3%95/1.%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0/1.%E7%BD%AE%E4%BF%A1%E5%8C%BA%E9%97%B4%E4%B8%8A%E7%95%8C?public=true
最后
以上就是神勇蜻蜓最近收集整理的关于机器学习之置信区间上界算法二、导入数据三、每个用户随机抽选广告得到的点击数的全部内容,更多相关机器学习之置信区间上界算法二、导入数据三、每个用户随机抽选广告得到内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。



![Bandit算法学习[网站优化]04——UCB(Upper Confidence Bound) 算法Bandit算法学习[网站优化]04——UCB(Upper Confidence Bound) 算法](https://www.shuijiaxian.com/files_image/reation/bcimg16.png)




发表评论 取消回复