最后两节课分别将bandits和games,基本上是保证课程的完整性,很多内容比较复杂,这里只提一些思想。
Lecture 9: Exploration and Exploitation
Online decision-making involves a fundamental choice:
Exploitation Make the best decision given current information
Exploration Gather more information
The best long-term strategy may involve short-term sacrifices
Gather enough information to make the best overall decisions
然而问题是:
If an algorithm forever explores it will have linear total regret
If an algorithm never explores it will have linear total regret
Is it possible to achieve sublinear total regret?
exploration and exploitation的principle:
Naive Exploration:
Add noise to greedy policy (e.g. epo-greedy) ==> greedy/epo-greedy has linear total regret
Optimistic Initialisation:
Assume the best until proven otherwise ==> greedy/epo-greedy + optimistic initialisation has linear total regret
Decaying epo-Greedy Algorithm :
不断减小epo的值,从多探索到多选择已知最优 ==> Decaying epo-Greedy Algorithm has logarithmic asymptotic total regret
Lower Bound of regret:Asymptotic total regret is at least logarithmic in number of steps
Optimism in the Face of Uncertainty:
Prefer actions with uncertain values
The more uncertain we are about an action-value,The more important it is to explore that action,It could turn out to be the best action
这其中的道理是:不确定的action对应的density function慢慢变得确定,而且reward是大是小非常明显。
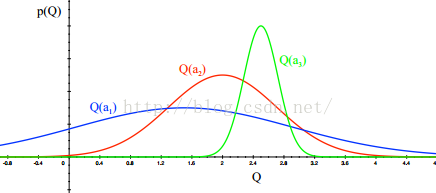
After picking blue action(如下图),We are less uncertain about the value,And more likely to pick another action,Until we home in on best action
Probability Matching:
Select actions according to probability they are best
Information State Search:
Lookahead search incorporating value of information
Lecture 10: Classic Games

Minimax Search
Self-Play Reinforcement Learning
Combining Reinforcement Learning and Minimax Search
Reinforcement Learning in Imperfect-Information Games
最后
以上就是清新电脑最近收集整理的关于reinforcement learning,增强学习:Exploration and Exploitation的全部内容,更多相关reinforcement内容请搜索靠谱客的其他文章。








发表评论 取消回复