- 标题:Reinforcement Learning with Deep Energy-Based Policies
- 文章链接:Reinforcement Learning with Deep Energy-Based Policies
- 代码:rail-berkeley/softlearning (原作者实现)
- 作者 Blog:Learning Diverse Skills via Maximum Entropy Deep Reinforcement Learning
- 发表:ICML 2017
- 领域:强化学习经典(Model-free + 最大熵思想),这篇是 SAC 的前身所以专门介绍一下
文章目录
- 1. 思想
- 1.1 随机性策略
- 1.2 用能量模型对策略建模
- 2. 本文方法
- 2.1 最大熵强化学习
- 2.2 策略建模
- 2.3 软价值函数(Soft Value Functions)
- 2.3.1 策略改进定理
- 2.3.2 最优策略的唯一性
- 2.3.3 小结
- 2.4 Soft Q-Learning
- 2.4.1 转换为优化问题
- 2.4.2 从 energy-based 分布中采样
- 2.5 伪代码
- 3. 实验
- 4. 总结
1. 思想
1.1 随机性策略
-
传统 RL 方法直接以最大化累计折扣回报作为优化目标,理想情况下最后会收敛到一个确定性策略,因为无论什么环境总会有一个最优解,传统 RL 就是想直接向它靠近。虽然传统 RL 方法中也含有随机性成分,但是引入随机性的主要目的是增加探索,扩大最后收敛到的稳定策略被选取的空间,比如
- 为了加强探索在策略中增加随机成分,如 ϵ epsilon ϵ-greedy
- 对策略网络输出增加一个噪声,得 Q 函数估计更平滑,如 TD3
- 直接把策略建模为一个概率分布,策略网络的训练变成优化分布的参数,比如 “随机高斯策略方法” 中策略网络是一个正态分布(这个其实有点随机性策略的感觉了,但是人为指定策略分布使其受到很大限制)
-
作者认为有些情况下训练随机性策略更有优势,比如
-
针对 “多模态目标multimodal objective” 的任务获得最优随机策略。所谓多模态目标就是 agent 想达到的目标有多个,比如打台球打进哪个袋口都可以,传统 RL 可能最后收敛到只会瞄准一个袋口。下图是本文作者的实验,面对四个等价目标,随机性策略下 agent 以接近相等的概率去向各个目标
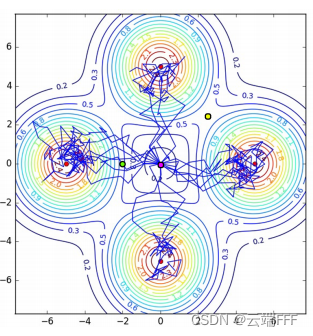
-
提高策略面对未知动态的鲁棒性。比如下面这个走迷宫任务
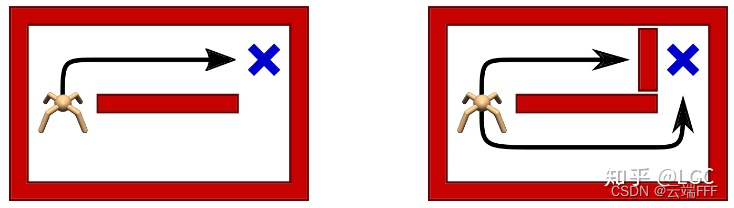
有两条路线能到达目标,传统 RL 最后只会收敛到上侧较短的路线,地图下侧由于后期访问少,相应位置的价值网络和策略网络(如果有的话)可能都还是欠拟合状态;随机策略则会同时优化两条路径,有时走上面有时走下面,虽然这时宏观上看 agent 的收益有所损失,但环境变化(上方道路被堵住)时可以迅速地 fine-turn 到下面的路线上 -
通过预训练迅速习得类似技能:这个其实和上面第 2 点一个意思,我们可以先在左图预训练随机策略,然后直接拿到某条路被挡住的任务环境中继续训练,策略会迅速 fine-turn 到可行的更好路线上
在
最优控制和概率推理二者结合的场景中,随机性策略表现更好,本文之前已经有了从分别从两个角度出发的研究 -
-
过去从最优控制(RL别名)角度出发的研究表明,一个好的随机策略要同时最大化累计折扣回报和策略的熵。直观上看,这时我们不去找那个单一的回报最高的策略,而是要找出一系列回报比较高的策略,并最大化它们的混乱程度,通过这种方式,agent 最后可以学会 “解决问题” 的所有方式,尽管某些方式的成本比较高,但是 agent 也知道可以这么做,会以较小概率按次优方案行动
1.2 用能量模型对策略建模
-
任务的多模态性质体现在价值函数中,最终学到的 Q ∗ ( s t , a t ∣ s t ) Q^*(s_t,a_t|s_t) Q∗(st,at∣st) 会是一个多峰函数。传统 RL 策略建模为如下 max max max 操作
π ( a t ∣ s t ) = arg max a Q ∗ ( s t , a t ) pi(a_t|s_t) = argmax_a Q^*(s_t,a_t) π(at∣st)=aargmaxQ∗(st,at) 为了增强探索,有时对策略输出加一个高斯噪声 ϵ epsilon ϵ,这样得到的近似确定性策略如下面左图所示
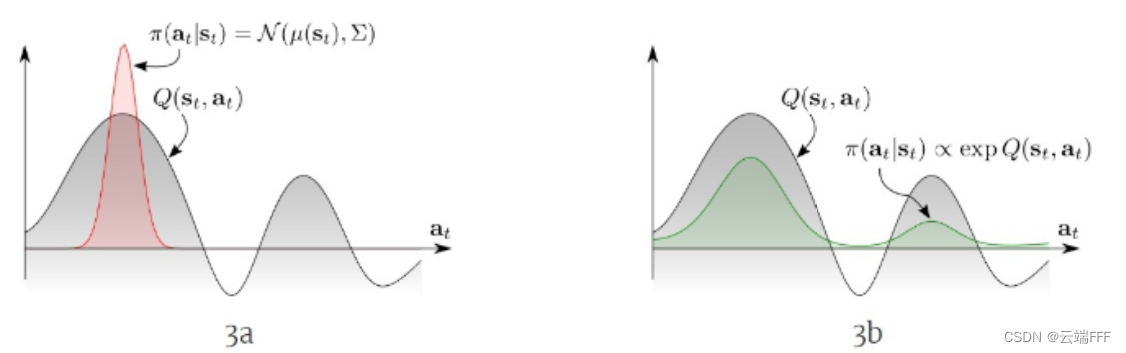
显然,一个理想的,适用于多模态任务的策略应该像右图那样,能够体现 Q ∗ ( s t , a t ∣ s t ) Q^*(s_t,a_t|s_t) Q∗(st,at∣st) 的多峰性质
-
作者这里选择了能表示多模态目标的最一般的分布类,把策略建模成一个
能量模型(Energy-Based Models, EMB)能量模型将样本 X X X 和标签 Y Y Y 的匹配度建模为能量 E ( X , Y ) mathcal{E}(X,Y) E(X,Y),能量越小代表样本和标记越匹配,模型对样本 X X X 的预测标记 Y Y Y 是一个分布的形式
P ( Y ∣ X ) = e − β E ( Y , X ) ∫ y ∈ Y e − β E ( Y , X ) mathrm{P}(mathrm{Y}|mathrm{X})=frac{mathrm{e}^{-beta mathcal{E}(mathrm{Y}, mathrm{X})}}{int_{yin Y} mathrm{e}^{-beta mathcal{E}(mathrm{Y}, mathrm{X})}} P(Y∣X)=∫y∈Ye−βE(Y,X)e−βE(Y,X) 其中逆温度系数 β beta β 是个常数不重要,分母的配分系数。能量模型是从玻尔兹曼分布推导出的,详细说明请参考:能量模型(Energy-Based Models, EMB)对应到强化学习的场景下, s t s_t st 看做样本, a t a_t at 看做标记,策略为
π ( a t ∣ s t ) ∝ exp ( − E ( s t , a t ) ) pi(a_t|s_t) propto exp(-mathcal{E}(s_t,a_t)) π(at∣st)∝exp(−E(st,at)) 只需把 ( s t , a t ) (s_t,a_t) (st,at) pari 的能量 E ( s t , a t ) mathcal{E}(s_t,a_t) E(st,at) 设计为基于负的 Q ∗ Q^* Q∗ 价值放缩后给出即可,这时价值越大的二元组对应的能量越低,匹配度越高,可以得到上面右侧图那种适合于多模态任务的随机性策略
2. 本文方法
2.1 最大熵强化学习
- 考虑如何实现 1.1 节最后的 “同时最大化累计折扣回报和策略的熵”,先看传统 RL 的优化目标
π std ∗ = arg max π 1 1 − γ E ( s , a ) ∼ ρ π [ r ( s , a ) ] = arg max π E τ ∼ π [ ∑ t = 0 ∞ γ t r ( s t , a t ) ] begin{aligned} pi^*_{text{std}} &= argmax_pi frac{1}{1-gamma}mathbb{E}_{(s,a)sim rho_pi}[r(s,a)] \ &= argmax_pi mathbb{E}_{tausimpi}[sum_{t=0}^infingamma^t r(s_t,a_t)] end{aligned} πstd∗=πargmax1−γ1E(s,a)∼ρπ[r(s,a)]=πargmaxEτ∼π[t=0∑∞γtr(st,at)] 作者基于传统 model-free RL 框架,通过修改 reward 来传递 “最大化熵” 的目标,具体而言就是把策略的熵作为附加 reward,于是优化目标变为
π MaxEnt ∗ = arg max π 1 1 − γ E ( s , a ) ∼ ρ π [ r ( s , a ) + α H ( π ( ⋅ ∣ s ) ] = arg max π E τ ∼ π [ ∑ t = 0 ∞ γ t ( r ( s t , a t ) + α H ( π ( ⋅ ∣ s t ) ) ] begin{aligned} pi^*_{text{MaxEnt}} &= argmax_pi frac{1}{1-gamma}mathbb{E}_{(s,a)sim rho_pi}[r(s,a)+alpha mathcal{H}(pi(cdot|s)] \ &= argmax_pi mathbb{E}_{tausimpi}[sum_{t=0}^infingamma^t (r(s_t,a_t)+alpha mathcal{H}(pi(cdot|s_t))] end{aligned} πMaxEnt∗=πargmax1−γ1E(s,a)∼ρπ[r(s,a)+αH(π(⋅∣s)]=πargmaxEτ∼π[t=0∑∞γt(r(st,at)+αH(π(⋅∣st))] 其中 ρ π rho_pi ρπ 是策略 π pi π 诱导的 ( s , a ) (s,a) (s,a) 二元组分布, α alpha α 是一个平衡最大化回报和最大化熵的系数,可以通过对真实 reward 乘以 1 α frac{1}{alpha} α1 将其隐藏掉
2.2 策略建模
- 前面 1.2 节已经说明过作者的策略建模思想,具体而言,作者将
(
s
,
a
)
(s,a)
(s,a) 二元组的能量设计为
E ( s t , a t ) = − 1 α Q soft ( s t , a t ) mathcal{E}(s_t,a_t) = -frac{1}{alpha} Q_{text{soft}}(s_t,a_t) E(st,at)=−α1Qsoft(st,at) 于是策略要满足
π MaxEnt ( a t ∣ s t ) ∝ exp ( 1 α Q soft ( s t , a t ) ) pi_{text{MaxEnt}}(a_t|s_t) propto expleft(frac{1}{alpha} Q_{text{soft}}(s_t,a_t)right) πMaxEnt(at∣st)∝exp(α1Qsoft(st,at)) 这里 Q soft ( s t , a t ) Q_{text{soft}}(s_t,a_t) Qsoft(st,at) 就是加入 2.1 节是熵目标后的 Q Q Q 价值函数。这里相当于把原先用 arg max argmax argmax 选择动作变成了通过 softmax text{softmax} softmax 选取动作,因而最终能得到随机性策略 - 需要注意的是,只靠这个并不足够,在传统 Q-Learning 中改用 softmax text{softmax} softmax 选取动作,虽然能让策略体现 Q Q Q 函数的多峰特征,但因为优化过程中没有明确地增大策略熵,仍然可能收敛到近似确定性策略,因此单独使用能量策略模型并不能得到良好的随机性策略,必须和考虑最大化策略熵的优化目标结合才行
2.3 软价值函数(Soft Value Functions)
- 按照 2.1 节的思路,最大熵 RL 的价值函数和传统 RL 无异,只是在 reward 中增加一个策略熵,于是可以定义
Q s o f t π ( s , a ) ≜ r 0 + E τ ∼ π , s 0 = s , a 0 = a [ ∑ t = 1 ∞ γ t ( r t + α H ( π ( ⋅ ∣ s t ) ) ) ] begin{aligned} &Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a}) triangleq r_{0}+mathbb{E}_{tau sim pi, mathbf{s}_{0}=mathbf{s}, mathbf{a}_{0}=mathbf{a}}left[sum_{t=1}^{infty} gamma^{t}Big(r_{t}+alphamathcal{H}(pileft(cdot |mathbf{s}_{t})right)Big)right] end{aligned} Qsoftπ(s,a)≜r0+Eτ∼π,s0=s,a0=a[t=1∑∞γt(rt+αH(π(⋅∣st)))] - 类似传统 RL,将
Q
s
o
f
t
(
s
,
a
)
Q_{mathrm{soft}}(s,a)
Qsoft(s,a) 和
V
s
o
f
t
(
s
)
V_{mathrm{soft}}(s)
Vsoft(s) 理解为 “从s处执行a出发的带熵奖励的累计折扣收益期望” 和 “从s处出发的的带熵奖励的累计折扣收益期望”,两个价值函数间的关系满足
V s o f t π ( s ) = E a ∼ π ( ⋅ ∣ s ) [ Q s o f t π ( s , a ) ] + α H ( π ( ⋅ ∣ s ) ) Q s o f t π ( s , a ) = r ( s , a ) + γ E s ′ ∼ p s [ V s o f t π ( s ′ ) ] begin{aligned} V_{mathrm{soft}}^{pi}(s) &= mathbb{E}_{asim pi(cdot|s)}[Q_{mathrm{soft}}^{pi}(s,a)] + alphamathcal{H}(pi(cdot|s)) \ Q_{mathrm{soft}}^{pi}(s,a) &= r(s,a) + gamma mathbb{E}_{s'sim p_{mathrm{s}}}left[V_{mathrm{soft}}^pileft(s'right)right] end{aligned} Vsoftπ(s)Qsoftπ(s,a)=Ea∼π(⋅∣s)[Qsoftπ(s,a)]+αH(π(⋅∣s))=r(s,a)+γEs′∼ps[Vsoftπ(s′)] 注意第一行 Q s o f t π ( s , a ) Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a}) Qsoftπ(s,a) 中没有计算在 s s s 选出 a a a 这一步的熵,把它加上。这两个相互代入就能得到最大熵 RL 语境下类似 Bellman equation 的恒等迭代关系,不妨称其为soft Bellman equation
2.3.1 策略改进定理
- 如同 2.2 节所述,现在我们用
softmax
text{softmax}
softmax 替代了
arg max
argmax
argmax 选取动作来 update 策略,这样的 update 合理吗?或者说这一步是不是一个合理的 policy improvement 过程?作者在这里给出如下定理说明确实合理
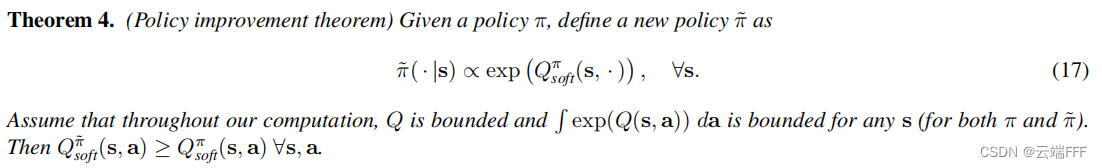
- 下面给出带权重系数
α
alpha
α 的详细证明,给定当前策略
π
pi
π 对应的 soft Q value 为
Q
s
o
f
t
π
(
s
,
a
)
Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a})
Qsoftπ(s,a),如下 update 策略
π ~ ( a ∣ s ) ∝ exp ( 1 α Q s o f t π ( s , a ) ) , ∀ s tilde{pi}(a|s) propto exp(frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s},a)), quad forall s π~(a∣s)∝exp(α1Qsoftπ(s,a)),∀s- 首先注意到,按当前策略
π
pi
π 行动时,有
H ( π ( ⋅ ∣ s ) ) + E a ∼ π [ 1 α Q s o f t π ( s , a ) ] = − D K L ( π ( ⋅ ∣ s ) ∥ π ~ ( ⋅ ∣ s ) ) + log ∫ exp ( 1 α Q s o f t π ( s , a ) ) d a (1) begin{aligned} mathcal{H}(pi(cdot |mathbf{s}))+mathbb{E}_{mathbf{a} sim pi}left[frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a})right]=-mathrm{D}_{mathrm{KL}}(pi(cdot mid mathbf{s}) | tilde{pi}(cdot mid mathbf{s}))+log int exp left(frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a})right) d mathbf{a} end{aligned} tag{1} H(π(⋅∣s))+Ea∼π[α1Qsoftπ(s,a)]=−DKL(π(⋅∣s)∥π~(⋅∣s))+log∫exp(α1Qsoftπ(s,a))da(1)要证明这个等式,可以从分解 − D K L ( π ( ⋅ ∣ s ) ∥ π ~ ( ⋅ ∣ s ) ) -mathrm{D}_{mathrm{KL}}(pi(cdot mid mathbf{s}) | tilde{pi}(cdot mid mathbf{s})) −DKL(π(⋅∣s)∥π~(⋅∣s)) 入手
− D K L ( π ( ⋅ ∣ s ) ∥ π ~ ( ⋅ ∣ s ) ) = ∫ a π ( a ∣ s ) log π ~ ( a ∣ s ) π ( a ∣ s ) d a = ∫ a π ( a ∣ s ) log π ~ ( a ∣ s ) d a − ∫ a π ( a ∣ s ) log π ( a ∣ s ) d a = ∫ a π ( a ∣ s ) log π ~ ( a ∣ s ) d a + H ( π ( a ∣ s ) ) = ∫ a π ( a ∣ s ) log exp ( 1 α Q s o f t π ( s , a ) ) ∫ a exp ( 1 α Q s o f t π ( s , a ) ) d a d a + H ( π ( a ∣ s ) ) = ∫ a π ( a ∣ s ) 1 α Q s o f t π ( s , a ) d a − ∫ a π ( log ∫ a exp ( 1 α Q s o f t π ( s , a ) ) d a ) d a + H ( π ( a ∣ s ) ) = E a ∼ π [ 1 α Q s o f t π ( s , a ) ] − log ∫ a exp ( 1 α Q s o f t π ( s , a ) ) d a + H ( π ( a ∣ s ) ) begin{aligned} -mathrm{D}_{mathrm{KL}}(pi(cdot mid mathbf{s}) | tilde{pi}(cdot mid mathbf{s})) &= int_a pi(a|s)logfrac{tilde{pi}(a|s)}{pi(a|s)}da \ &= int_a pi(a|s)logtilde{pi}(a|s)da- int_a pi(a|s)logpi(a|s)da \ &= int_a pi(a|s)logtilde{pi}(a|s)da + mathcal{H}(pi(a|mathbf{s})) \ &= int_a pi(a|s) log frac{exp(frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s},a))}{int_aexp(frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s},a))da}da + mathcal{H}(pi(a|mathbf{s})) \ &= int_a pi(a|s)frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s},a)da - int_a pibig(log int_aexp(frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s},a))dabig)da + mathcal{H}(pi(a|mathbf{s})) \ &= mathbb{E}_{mathbf{a} sim pi}left[frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a})right] - log int_aexp(frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s},a))da + mathcal{H}(pi(a|mathbf{s})) end{aligned} −DKL(π(⋅∣s)∥π~(⋅∣s))=∫aπ(a∣s)logπ(a∣s)π~(a∣s)da=∫aπ(a∣s)logπ~(a∣s)da−∫aπ(a∣s)logπ(a∣s)da=∫aπ(a∣s)logπ~(a∣s)da+H(π(a∣s))=∫aπ(a∣s)log∫aexp(α1Qsoftπ(s,a))daexp(α1Qsoftπ(s,a))da+H(π(a∣s))=∫aπ(a∣s)α1Qsoftπ(s,a)da−∫aπ(log∫aexp(α1Qsoftπ(s,a))da)da+H(π(a∣s))=Ea∼π[α1Qsoftπ(s,a)]−log∫aexp(α1Qsoftπ(s,a))da+H(π(a∣s)) - 利用等式 (1) 可得,维持当前价值估计
Q
s
o
f
t
π
(
s
,
a
)
Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a})
Qsoftπ(s,a) 但是按新策略
π
~
tilde{pi}
π~ 行动时,有
H ( π ~ ( ⋅ ∣ s ) ) + E a ∼ π ~ [ 1 α Q s o f t π ( s , a ) ] = − D K L ( π ~ ( ⋅ ∣ s ) ∥ π ~ ( ⋅ ∣ s ) ) + log ∫ exp ( 1 α Q s o f t π ( s , a ) ) d a = 0 + log ∫ exp ( 1 α Q s o f t π ( s , a ) ) d a (2) begin{aligned} mathcal{H}(tilde{pi}(cdot |mathbf{s}))+mathbb{E}_{mathbf{a} sim tilde{pi}}left[frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a})right] &=-mathrm{D}_{mathrm{KL}}(tilde{pi}(cdot mid mathbf{s}) | tilde{pi}(cdot mid mathbf{s}))+log int exp left(frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a})right) d mathbf{a} \ &= 0 + log int exp left(frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a})right) d mathbf{a} end{aligned} tag{2} H(π~(⋅∣s))+Ea∼π~[α1Qsoftπ(s,a)]=−DKL(π~(⋅∣s)∥π~(⋅∣s))+log∫exp(α1Qsoftπ(s,a))da=0+log∫exp(α1Qsoftπ(s,a))da(2) 由于 D K L ( π ~ ( ⋅ ∣ s ) ∥ π ~ ( ⋅ ∣ s ) ) ≥ 0 mathrm{D}_{mathrm{KL}}(tilde{pi}(cdot mid mathbf{s}) | tilde{pi}(cdot mid mathbf{s}))geq 0 DKL(π~(⋅∣s)∥π~(⋅∣s))≥0 当且仅当 π = π ~ pi = tilde{pi} π=π~ 时等号成立,当 π ≠ π ~ pineq tilde{pi} π=π~ 时(即收敛之前),有
H ( π ( ⋅ ∣ s ) ) + E a ∼ π [ 1 α Q s o f t π ( s , a ) ] ≤ H ( π ~ ( ⋅ ∣ s ) ) + E a ∼ π ~ [ 1 α Q s o f t π ( s , a ) ] mathcal{H}(pi(cdot mid mathbf{s}))+mathbb{E}_{mathbf{a} sim pi}left[frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a})right] leq mathcal{H}(tilde{pi}(cdot mid mathbf{s}))+mathbb{E}_{mathbf{a} sim tilde{pi}}left[frac{1}{alpha}Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a})right] H(π(⋅∣s))+Ea∼π[α1Qsoftπ(s,a)]≤H(π~(⋅∣s))+Ea∼π~[α1Qsoftπ(s,a)] 两边同时乘上 α alpha α 得到两个策略下 soft V value 的关系为
α H ( π ( ⋅ ∣ s ) ) + E a ∼ π [ Q s o f t π ( s , a ) ] ≤ α H ( π ~ ( ⋅ ∣ s ) ) + E a ∼ π ~ [ Q s o f t π ( s , a ) ] (3) alphamathcal{H}(pi(cdot mid mathbf{s}))+mathbb{E}_{mathbf{a} sim pi}left[Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a})right] leq alphamathcal{H}(tilde{pi}(cdot mid mathbf{s}))+mathbb{E}_{mathbf{a} sim tilde{pi}}left[Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a})right] tag{3} αH(π(⋅∣s))+Ea∼π[Qsoftπ(s,a)]≤αH(π~(⋅∣s))+Ea∼π~[Qsoftπ(s,a)](3) - 反复应用等式 (3) 展开
Q
s
o
f
t
π
(
s
,
a
)
Q_{mathrm{soft}}^{pi}(mathbf{s},a)
Qsoftπ(s,a)
Q s o f t π ( s , a ) = E s 1 [ r 0 + γ ( α H ( π ( ⋅ ∣ s 1 ) ) + E a 1 ∼ π [ Q s o f t π ( s 1 , a 1 ) ] ) ] ≤ E s 1 [ r 0 + γ ( α H ( π ~ ( ⋅ ∣ s 1 ) ) + E a 1 ∼ π ~ [ Q s o f t π π ( s 1 , a 1 ) ] ) ] = E s 1 [ r 0 + γ ( α H ( π ~ ( ⋅ ∣ s 1 ) ) + r 1 ) ] + γ 2 E s 2 [ α H ( π ( ⋅ ∣ s 2 ) ) + E a 2 ∼ π [ Q s o f t π ( s 2 , a 2 ) ] ] ≤ E s 1 [ r 0 + γ ( α H ( π ~ ( ⋅ ∣ s 1 ) ) + r 1 ] + γ 2 E s 2 [ α H ( π ~ ( ⋅ ∣ s 2 ) ) + E a 2 ∼ π ~ [ Q s o f t π ( s 2 , a 2 ) ] ] = E s 1 a 2 ∼ π ~ , s 2 [ r 0 + γ ( α H ( π ~ ( ⋅ ∣ s 1 ) ) + r 1 ) + γ 2 ( α H ( π ~ ( ⋅ ∣ s 2 ) ) + r 2 ) ] + γ 3 E s 3 [ α H ( π ~ ( ⋅ ∣ s 3 ) ) + E a 3 ∼ π ~ [ Q s o f t ∗ π ( s 3 , a 3 ) ] ] ⋮ ≤ E τ ∼ π ~ [ r 0 + ∑ t = 1 ∞ γ t ( α H ( π ~ ( ⋅ ∣ s t ) ) + r t ) ] = Q soft π ~ ( s , a ) . begin{aligned} Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a}) &=mathbb{E}_{mathbf{s}_{1}}Big[r_{0}+gammaleft(alphamathcal{H}left(pileft(cdot mid mathbf{s}_{1}right)right)+mathbb{E}_{mathbf{a}_{1} sim pi}left[Q_{mathrm{soft}}^{pi}left(mathbf{s}_{1}, mathbf{a}_{1}right)right]right)Big] \ & leq mathbb{E}_{mathbf{s}_{1}}Big[r_{0}+gammaleft(alphamathcal{H}left(tilde{pi}left(cdot mid mathbf{s}_{1}right)right)+mathbb{E}_{mathbf{a}_{1} sim tilde{pi}}left[Q_{mathrm{soft}^{pi}}^{pi}left(mathbf{s}_{1}, mathbf{a}_{1}right)right]right)Big] \ &=mathbb{E}_{mathbf{s}_{1}}left[r_{0}+gammaleft(alphamathcal{H}left(tilde{pi}left(cdot mid mathbf{s}_{1}right)right)+r_{1}right)right]+gamma^{2} mathbb{E}_{mathbf{s}_{2}}Big[alphamathcal{H}left(pileft(cdot mid mathbf{s}_{2}right)right)+mathbb{E}_{mathbf{a}_{2} sim pi}left[Q_{mathrm{soft}}^{pi}left(mathbf{s}_{2}, mathbf{a}_{2}right)right]Big] \ & leq mathbb{E}_{mathbf{s}_{1}}left[r_{0}+gammaleft(alphamathcal{H}left(tilde{pi}left(cdot mid mathbf{s}_{1}right)right)+r_{1}right]+gamma^{2} mathbb{E}_{mathbf{s}_{2}}Big[alphamathcal{H}left(tilde{pi}left(cdot mid mathbf{s}_{2}right)right)+mathbb{E}_{mathbf{a}_{2} sim tilde{pi}}left[Q_{mathrm{soft}}^{pi}left(mathbf{s}_{2}, mathbf{a}_{2}right)right]right]Big.\ &=mathbb{E}_{mathbf{s}_{1} mathbf{a}_{2} sim tilde{pi}, mathbf{s}_{2}}left[r_{0}+gammaleft(alphamathcal{H}left(tilde{pi}left(cdot mid mathbf{s}_{1}right)right)+r_{1}right)+gamma^{2}left(alphamathcal{H}left(tilde{pi}left(cdot mid mathbf{s}_{2}right)right)+r_{2}right)right]+gamma^{3} mathbb{E}_{mathbf{s}_{3}}Big[alphamathcal{H}left(tilde{pi}left(cdot mid mathbf{s}_{3}right)right)+mathbb{E}_{mathbf{a}_{3} sim tilde{pi}}left[Q_{mathrm{soft}^{*}}^{pi}left(mathbf{s}_{3}, mathbf{a}_{3}right)right]Big] \ & vdots \ & leq mathbb{E}_{tau sim tilde{pi}}left[r_{0}+sum_{t=1}^{infty} gamma^{t}left(alphamathcal{H}left(tilde{pi}left(cdot mid mathbf{s}_{t}right)right)+r_{t}right)right] \ &=Q_{text {soft }}^{tilde{pi}}(mathbf{s}, mathbf{a}) . end{aligned} Qsoftπ(s,a)=Es1[r0+γ(αH(π(⋅∣s1))+Ea1∼π[Qsoftπ(s1,a1)])]≤Es1[r0+γ(αH(π~(⋅∣s1))+Ea1∼π~[Qsoftππ(s1,a1)])]=Es1[r0+γ(αH(π~(⋅∣s1))+r1)]+γ2Es2[αH(π(⋅∣s2))+Ea2∼π[Qsoftπ(s2,a2)]]≤Es1[r0+γ(αH(π~(⋅∣s1))+r1]+γ2Es2[αH(π~(⋅∣s2))+Ea2∼π~[Qsoftπ(s2,a2)]]=Es1a2∼π~,s2[r0+γ(αH(π~(⋅∣s1))+r1)+γ2(αH(π~(⋅∣s2))+r2)]+γ3Es3[αH(π~(⋅∣s3))+Ea3∼π~[Qsoft∗π(s3,a3)]]⋮≤Eτ∼π~[r0+t=1∑∞γt(αH(π~(⋅∣st))+rt)]=Qsoft π~(s,a). 策略改进定理等证,只要按照如下方式更新策略进行 policy improvement,最终一定可以收敛
π i + 1 ( a ∣ s ) ∝ exp ( 1 α Q soft π i ( s , a ) ) pi_{i+1}(a|s) propto expleft(frac{1}{alpha} Q_{text{soft}}^{pi_i}(s,a)right) πi+1(a∣s)∝exp(α1Qsoftπi(s,a)) 这个等价于用优势函数表示
π i + 1 ( a ∣ s ) ∝ exp ( 1 α ( Q soft π i ( s , a ) − V soft π i ( s ) ) ) pi_{i+1}(a|s) propto expleft(frac{1}{alpha} (Q_{text{soft}}^{pi_i}(s,a)-V_{text{soft}}^{pi_i}(s))right) πi+1(a∣s)∝exp(α1(Qsoftπi(s,a)−Vsoftπi(s)))
- 首先注意到,按当前策略
π
pi
π 行动时,有
2.3.2 最优策略的唯一性
- 上面我们证明了迭代地对
Q
soft
Q_{text{soft}}
Qsoft 使用 softmax 方式更新策略一定可以收敛到某个最优策略,并且对收敛时
Q
soft
∗
,
V
soft
∗
,
π
MaxEnt
∗
Q_{text{soft}}^*,V_{text{soft}}^*, pi^*_{text{MaxEnt}}
Qsoft∗,Vsoft∗,πMaxEnt∗ 三者间的关系进行了推导分析。本节证明无论更新初始值、更新使用样本顺序等如何变化,最优策略都是唯一的
其实和证明原始 Bellman operator 和 Bellman optimal operator 的收敛性一样,只需证明这种更新方式对应的算子是一个压缩映射即可,关于两个原始 Bellman 算子的证明可以参考:强化学习拾遗 —— 表格型方法和函数近似方法中 Bellman 迭代的收敛性分析
- 把 “对
Q
soft
Q_{text{soft}}
Qsoft 使用 softmax 方式迭代更新策略” 这件事转换为仅关于价值函数的迭代操作:作者这里直接用了 2.3.1 节最终收敛到的关系,文中表述为定理 3:设
Q
soft
Q_{text{soft}}
Qsoft 和
V
soft
V_{text{soft}}
Vsoft 都有界,并假设
∫
A
exp
(
1
α
Q
soft
(
⋅
,
a
)
)
d
a
<
∞
,
Q
soft
∗
<
∞
int_mathcal{A}exp(frac{1}{alpha}Q_{text{soft}}(cdot,a))da<infin, Q_{text{soft}}^* < infin
∫Aexp(α1Qsoft(⋅,a))da<∞,Qsoft∗<∞,反复进行如下迭代
Q s o f t ( s t , a t ) ← r t + γ E s t + 1 ∼ p s [ V s o f t ( s t + 1 ) ] , ∀ s t , a t V s o f t ( s t ) ← α log ∫ A exp ( 1 α Q s o f t ( s t , a ′ ) ) d a ′ , ∀ s t begin{aligned} Q_{mathrm{soft}}left(mathbf{s}_{t}, mathbf{a}_{t}right) & leftarrow r_{t}+gamma mathbb{E}_{mathbf{s}_{t+1} sim p_{mathrm{s}}}left[V_{mathrm{soft}}left(mathbf{s}_{t+1}right)right], forall mathbf{s}_{t}, mathbf{a}_{t} \ V_{mathrm{soft}}left(mathbf{s}_{t}right) & leftarrow alpha log int_{mathcal{A}} exp left(frac{1}{alpha} Q_{mathrm{soft}}left(mathbf{s}_{t}, mathbf{a}^{prime}right)right) d mathbf{a}^{prime}, forall mathbf{s}_{t} end{aligned} Qsoft(st,at)Vsoft(st)←rt+γEst+1∼ps[Vsoft(st+1)],∀st,at←αlog∫Aexp(α1Qsoft(st,a′))da′,∀st 最终会分别收敛到 Q soft ∗ Q^*_{text{soft}} Qsoft∗ 和 V soft ∗ V^*_{text{soft}} Vsoft∗分析一下这个迭代过程,第一行从 V soft ∗ ( s t ) V^*_{text{soft}}(s_t) Vsoft∗(st) 表示出 Q soft ∗ ( s t ) Q^*_{text{soft}}(s_t) Qsoft∗(st) 就是直接用的 2.3 节最初提到的恒等关系
Q s o f t π ( s , a ) = r ( s , a ) + γ E s ′ ∼ p s [ V s o f t π ( s ′ ) ] Q_{mathrm{soft}}^{pi}(s,a) = r(s,a) + gamma mathbb{E}_{s'sim p_{mathrm{s}}}left[V_{mathrm{soft}}^pileft(s'right)right] Qsoftπ(s,a)=r(s,a)+γEs′∼ps[Vsoftπ(s′)] 而第二行是这个迭代的重点,有 2.3.1 节分析中第 2 点可知,在当前价值估计为 Q s o f t π ( s , a ) Q_{mathrm{soft}}^{pi}(mathbf{s}, mathbf{a}) Qsoftπ(s,a) 但是按基于 softmax 得到的提升后的新策略 π ~ tilde{pi} π~ 行动时,有
V soft π ~ ( s ) = α log ∫ A exp ( 1 α Q s o f t π ( s , a ′ ) ) d a ′ V_{text{soft}}^{tilde{pi}}(s) = alphalog int_{mathcal{A}} exp left(frac{1}{alpha}Q_{mathrm{soft}}^{pi}(s,a')right) da' Vsoftπ~(s)=αlog∫Aexp(α1Qsoftπ(s,a′))da′ 因此这一行是从价值函数上体现了 softmax 策略提升操作,只有优化后的策略 π ~ tilde{pi} π~ 才能使等号成立,将 = = = 变化为 ← leftarrow ← 即代表估计优化后策略的价值,因此定理 3 这个迭代过程就是最大熵 RL 语境下类似 Bellman optimal equation 的恒等迭代关系,不妨称其为soft Bellman optimal equation。另外可以看一下原始 Bellman optimal equation
v ( s ) = max a ∈ A q ( s , a ) q ( s , a ) = r ( s , a ) + γ ∑ s ′ p ( s ′ ∣ s , a ) v ( s ′ ) = ∑ s ′ , r p ( s ′ , r , ∣ s , a ) [ r + γ v ( s ′ ) ] begin{array}{l} mathrm{v}(mathrm{~s})=max _{mathrm{a} in mathcal{A}} mathrm{q}(mathrm{~s}, mathrm{a}) \ mathrm{q}(mathrm{~s}, mathrm{a})=mathrm{r}(mathrm{s}, mathrm{a})+gamma sum_{mathrm{s}^{prime}} mathrm{p}left(mathrm{s}^{prime} mid mathrm{s}, mathrm{a}right) mathrm{v}left(mathrm{~s}^{prime}right)=sum_{mathrm{s}^{prime}, mathrm{r}} mathrm{p}left(mathrm{s}^{prime}, mathrm{r}, mid mathrm{s}, mathrm{a}right)left[mathrm{r}+gamma mathrm{v}left(mathrm{~s}^{prime}right)right] end{array} v( s)=maxa∈Aq( s,a)q( s,a)=r(s,a)+γ∑s′p(s′∣s,a)v( s′)=∑s′,rp(s′,r,∣s,a)[r+γv( s′)] 和这里很类似,第二行从 v 到 q 是恒等关系,第一行 max max max 操作体现 arg max argmax argmax 的策略提升操作 - 使用算子形式表示这里的 “soft Bellman optimal equation”:直接把上面迭代式子中的
V
soft
(
s
t
)
V_{text{soft}}(s_t)
Vsoft(st) 代入到
Q
soft
(
s
t
,
a
t
)
Q_{text{soft}}(s_t,a_t)
Qsoft(st,at) 里,引入 soft value iteration operator
T
mathcal{T}
T 为
T Q ( s , a ) ≜ r ( s , a ) + γ E s ′ ∼ p s [ log ∫ exp Q ( s ′ , a ′ ) d a ′ ] mathcal{T} Q(mathbf{s}, mathbf{a}) triangleq r(mathbf{s}, mathbf{a})+gamma mathbb{E}_{mathbf{s}^{prime} sim p_{mathbf{s}}}left[log int exp Qleft(mathbf{s}^{prime}, mathbf{a}^{prime}right) d mathbf{a}^{prime}right] TQ(s,a)≜r(s,a)+γEs′∼ps[log∫expQ(s′,a′)da′] - 证明算子是压缩映射:这里仍然使用传统 RL 的无穷范数作为考察压缩性质的度量,无穷范数下
L
p
L^p
Lp 空间中任意两个
Q
soft
Q_{text{soft}}
Qsoft 函数
Q
1
,
Q
2
Q_1,Q_2
Q1,Q2 间的距离为
∣
∣
Q
1
−
Q
2
∣
∣
∞
=
max
s
,
a
∣
Q
1
(
s
,
a
)
−
Q
2
(
s
,
a
)
∣
||Q_1-Q_2||_infin = max_{s,a}|Q_1(s,a)-Q_2(s,a)|
∣∣Q1−Q2∣∣∞=maxs,a∣Q1(s,a)−Q2(s,a)∣,设
ε
=
∣
∣
Q
1
−
Q
2
∣
∣
∞
varepsilon = ||Q_1-Q_2||_infin
ε=∣∣Q1−Q2∣∣∞,这时有
log ∫ exp ( Q 1 ( s ′ , a ′ ) ) d a ′ ≤ log ∫ exp ( Q 2 ( s ′ , a ′ ) + ε ) d a ′ = log ( exp ( ε ) ∫ exp Q 2 ( s ′ , a ′ ) d a ′ ) = ε + log ∫ exp Q 2 ( a ′ , a ′ ) d a ′ begin{aligned} log int exp left(Q_{1}left(mathbf{s}^{prime}, mathbf{a}^{prime}right)right) d mathbf{a}^{prime} & leq log int exp left(Q_{2}left(mathbf{s}^{prime}, mathbf{a}^{prime}right)+varepsilonright) d mathbf{a}^{prime} \ &=log left(exp (varepsilon) int exp Q_{2}left(mathbf{s}^{prime}, mathbf{a}^{prime}right) d mathbf{a}^{prime}right) \ &=varepsilon+log int exp Q_{2}left(mathbf{a}^{prime}, mathbf{a}^{prime}right) d mathbf{a}^{prime} end{aligned} log∫exp(Q1(s′,a′))da′≤log∫exp(Q2(s′,a′)+ε)da′=log(exp(ε)∫expQ2(s′,a′)da′)=ε+log∫expQ2(a′,a′)da′ 同理有 log ∫ exp ( Q 1 ( s ′ , a ′ ) ) d a ′ ≥ − ε + log ∫ exp Q 2 ( a ′ , a ′ ) d a ′ log int exp left(Q_{1}left(mathbf{s}^{prime}, mathbf{a}^{prime}right)right) d mathbf{a}^{prime} geq -varepsilon+log int exp Q_{2}left(mathbf{a}^{prime}, mathbf{a}^{prime}right) d mathbf{a}^{prime} log∫exp(Q1(s′,a′))da′≥−ε+log∫expQ2(a′,a′)da′,因此有
∣ ∣ T Q 1 − T Q 2 ∣ ∣ ∞ = γ ∣ ∣ log ∫ exp ( Q 1 ( s ′ , a ′ ) ) d a ′ − log ∫ exp ( Q 2 ( s ′ , a ′ ) ) d a ′ ∣ ∣ ∞ ≤ γ ε = γ ∣ ∣ Q 1 − Q 2 ∣ ∣ ∞ begin{aligned} ||mathcal{T}Q_1-mathcal{T}Q_2||_infin &= gamma||log int exp left(Q_{1}left(mathbf{s}^{prime}, mathbf{a}^{prime}right)right) d mathbf{a}^{prime}-log int exp left(Q_{2}left(mathbf{s}^{prime}, mathbf{a}^{prime}right)right) d mathbf{a}^{prime}||_infin \ &leq gamma varepsilon \ &= gamma||Q_1-Q_2||_infin end{aligned} ∣∣TQ1−TQ2∣∣∞=γ∣∣log∫exp(Q1(s′,a′))da′−log∫exp(Q2(s′,a′))da′∣∣∞≤γε=γ∣∣Q1−Q2∣∣∞ 这就证明了算子 T mathcal{T} T 是一个 γ gamma γ 收缩映射,优化得到的最优策略一定唯一
- 把 “对
Q
soft
Q_{text{soft}}
Qsoft 使用 softmax 方式迭代更新策略” 这件事转换为仅关于价值函数的迭代操作:作者这里直接用了 2.3.1 节最终收敛到的关系,文中表述为定理 3:设
Q
soft
Q_{text{soft}}
Qsoft 和
V
soft
V_{text{soft}}
Vsoft 都有界,并假设
∫
A
exp
(
1
α
Q
soft
(
⋅
,
a
)
)
d
a
<
∞
,
Q
soft
∗
<
∞
int_mathcal{A}exp(frac{1}{alpha}Q_{text{soft}}(cdot,a))da<infin, Q_{text{soft}}^* < infin
∫Aexp(α1Qsoft(⋅,a))da<∞,Qsoft∗<∞,反复进行如下迭代
2.3.3 小结
- 观察上面的证明过程,根据等式 (2),还可以发现策略收敛时(
π
~
=
π
tilde{pi}=pi
π~=π)时的最优 soft V value 为
V soft ∗ ( s ) = E a ∼ π [ Q s o f t ∗ ( s , a ) ] + α H ( π ( ⋅ ∣ s ) ) = α log ∫ a exp ( 1 α Q s o f t ∗ ( s , a ) ) d a V^*_{text{soft}}(s) = mathbb{E}_{mathbf{a} sim pi}left[Q_{mathrm{soft}}^*(mathbf{s}, mathbf{a})right] +alphamathcal{H}(pi(cdot |mathbf{s}))=alphalog int_a exp left(frac{1}{alpha}Q_{mathrm{soft}}^*(mathbf{s}, a)right) da Vsoft∗(s)=Ea∼π[Qsoft∗(s,a)]+αH(π(⋅∣s))=αlog∫aexp(α1Qsoft∗(s,a))da 利用这个可以得到最优策略为
{ π MaxEnt ∗ ( a ∣ s ) ∝ exp ( 1 α ( Q s o f t ∗ ( s , a ) − V soft ∗ ( s ) ) ) ∫ A π MaxEnt ∗ ( a ∣ s ) = 1 ⟹ π MaxEnt ∗ ( a ∣ s ) = exp ( 1 α ( Q s o f t ∗ ( s , a ) − V soft ∗ ( s ) ) ) begin{aligned} &left{ begin{aligned} &pi^*_{text{MaxEnt}}(a|s) propto expleft(frac{1}{alpha}(Q_{mathrm{soft}}^*(mathbf{s},a)-V^*_{text{soft}}(s))right) \ &int_mathcal{A}pi^*_{text{MaxEnt}}(a|s) = 1 end{aligned} right. \ Longrightarrow &spacespace pi^*_{text{MaxEnt}}(a|s) = expleft(frac{1}{alpha}(Q_{mathrm{soft}}^*(mathbf{s},a)-V^*_{text{soft}}(s))right) end{aligned} ⟹⎩ ⎨ ⎧πMaxEnt∗(a∣s)∝exp(α1(Qsoft∗(s,a)−Vsoft∗(s)))∫AπMaxEnt∗(a∣s)=1 πMaxEnt∗(a∣s)=exp(α1(Qsoft∗(s,a)−Vsoft∗(s))) 利用上面的 V soft ∗ ( s ) V^*_{text{soft}}(s) Vsoft∗(s) 和 π MaxEnt ∗ pi^*_{text{MaxEnt}} πMaxEnt∗(下面简称 π ∗ pi^* π∗),还能从 Q s o f t ∗ ( s , a ) Q_{mathrm{soft}}^*(s,a) Qsoft∗(s,a) 的定义推出用 V soft ∗ V^*_{text{soft}} Vsoft∗ 表示 Q soft ∗ Q^*_{text{soft}} Qsoft∗ 的方法
Q s o f t ∗ ( s , a ) ≜ r ( s , a ) + E ( s ′ , . . . ) ∼ ρ [ ∑ t = 0 ∞ γ l ( r t + α H ( π ∗ ( ⋅ ∣ s t ) ) ) ] = r ( s , a ) + γ E s ′ ∼ p s [ α H ( π ∗ ( ⋅ ∣ s ′ ) ) + E a ′ ∼ π ∗ ( ⋅ ∣ s ′ ) [ Q s o f t ∗ ( s ′ , a ′ ) ] ] = r ( s , a ) + γ E s ′ ∼ p s [ V s o f t ∗ ( s ′ ) ] begin{aligned} Q_{mathrm{soft}}^*(mathbf{s}, mathbf{a}) &triangleq r(s,a) + mathbb{E}_{(s',...)simrho}left[sum_{t=0}^infin gamma^l(r_{t}+alphamathcal{H}(pi^*(cdot|s_t)))right] \ &=r(mathbf{s}, mathbf{a})+gamma mathbb{E}_{mathbf{s}^{prime} sim p_{mathrm{s}}}left[alphamathcal{H}left(pi^*left(cdot mid mathbf{s}^{prime}right)right)+mathbb{E}_{mathbf{a}^{prime} sim pi^*left(cdot mid mathbf{s}^{prime}right)}left[Q_{mathrm{soft}}^*left(mathbf{s}^{prime}, mathbf{a}^{prime}right)right]right] \ &=r(mathbf{s}, mathbf{a})+gamma mathbb{E}_{mathbf{s}^{prime} sim p_{mathrm{s}}}left[V_{mathrm{soft}}^*left(mathbf{s}^{prime}right)right] end{aligned} Qsoft∗(s,a)≜r(s,a)+E(s′,...)∼ρ[t=0∑∞γl(rt+αH(π∗(⋅∣st)))]=r(s,a)+γEs′∼ps[αH(π∗(⋅∣s′))+Ea′∼π∗(⋅∣s′)[Qsoft∗(s′,a′)]]=r(s,a)+γEs′∼ps[Vsoft∗(s′)] - 整理一下,优化收敛时,有
Q soft ∗ ( s t , a t ) = r ( s t , a t ) + E ( s t + 1 , . . . ) ∼ ρ [ ∑ l = 1 ∞ γ l ( r t + l + α H ( π MaxEnt ∗ ( ⋅ ∣ s t + l ) ) ) ] = r ( s t , a t ) + γ E s t + 1 ∼ p s [ α H ( π MaxEnt ∗ ( ⋅ ∣ s t + l ) ) + E a t + 1 ∼ π MaxEnt ∗ ( ⋅ ∣ s t ) [ Q soft ∗ ( s t + 1 , a t + 1 ] ] = r ( s t , a t ) + γ E s t + 1 ∼ p s [ V s o f t ∗ ( s t + 1 ) ] V soft ∗ ( s t ) = α log ∫ A exp ( 1 α Q s o f t ∗ ( s t , a ) ) d a π MaxEnt ∗ ( a t ∣ s t ) = exp ( 1 α ( Q s o f t ∗ ( s t , a t ) − V soft ∗ ( s t ) ) ) begin{aligned} Q^*_{text{soft}}(s_t,a_t) &= r(s_t,a_t) + mathbb{E}_{(s_{t+1},...)simrho}left[sum_{l=1}^infin gamma^l(r_{t+l}+alphamathcal{H}(pi_{text{MaxEnt}}^*(cdot|s_{t+l})))right]\ &=r(s_t,a_t) +gamma mathbb{E}_{s_{t+1}sim p_{mathrm{s}}}left[alphamathcal{H}(pi_{text{MaxEnt}}^*(cdot|s_{t+l}))+mathbb{E}_{a_{t+1}simpi_{text{MaxEnt}}^*(cdot|s_t)}[Q_{text{soft}}^*(s_{t+1},a_{t+1}]right] \ &= r(s_t,a_t) + gamma mathbb{E}_{s_{t+1}sim p_{mathrm{s}}}left[V_{mathrm{soft}}^*left(s_{t+1}right)right] \ V^*_{text{soft}}(s_t) &= alphalog int_mathcal{A} exp left(frac{1}{alpha}Q_{mathrm{soft}}^*(s_t, a)right) da \ quad pi^*_{text{MaxEnt}}(a_t|s_t) &=expleft(frac{1}{alpha}(Q_{mathrm{soft}}^*(s_t,a_t)-V^*_{text{soft}}(s_t))right) end{aligned} Qsoft∗(st,at)Vsoft∗(st)πMaxEnt∗(at∣st)=r(st,at)+E(st+1,...)∼ρ[l=1∑∞γl(rt+l+αH(πMaxEnt∗(⋅∣st+l)))]=r(st,at)+γEst+1∼ps[αH(πMaxEnt∗(⋅∣st+l))+Eat+1∼πMaxEnt∗(⋅∣st)[Qsoft∗(st+1,at+1]]=r(st,at)+γEst+1∼ps[Vsoft∗(st+1)]=αlog∫Aexp(α1Qsoft∗(st,a))da=exp(α1(Qsoft∗(st,at)−Vsoft∗(st))) 到这其实就把文章里的定理 1 和定理 2 也证明完了Note: 我个人认为文章附录里对这部分证明的符号不严谨,我是重新写的没完全按原文
- 另外,还可以和传统 RL 的两个 bellman 等式进行比较
这里实在懒得打公式了,引用自 Soft Q-learning解读

2.4 Soft Q-Learning
- 到目前为止算法其实已经有了,只要像 2.3.2 节那样不停迭代
Q s o f t ( s t , a t ) ← r t + γ E s t + 1 ∼ p s [ V s o f t ( s t + 1 ) ] , ∀ s t , a t V s o f t ( s t ) ← α log ∫ A exp ( 1 α Q s o f t ( s t , a ′ ) ) d a ′ , ∀ s t begin{aligned} Q_{mathrm{soft}}left(mathbf{s}_{t}, mathbf{a}_{t}right) & leftarrow r_{t}+gamma mathbb{E}_{mathbf{s}_{t+1} sim p_{mathrm{s}}}left[V_{mathrm{soft}}left(mathbf{s}_{t+1}right)right], &&forall mathbf{s}_{t}, mathbf{a}_{t} \ V_{mathrm{soft}}left(mathbf{s}_{t}right) & leftarrow alpha log int_{mathcal{A}} exp left(frac{1}{alpha} Q_{mathrm{soft}}left(mathbf{s}_{t}, mathbf{a}^{prime}right)right) d mathbf{a}^{prime}, &&forall mathbf{s}_{t} end{aligned} Qsoft(st,at)Vsoft(st)←rt+γEst+1∼ps[Vsoft(st+1)],←αlog∫Aexp(α1Qsoft(st,a′))da′,∀st,at∀st 就一定能收敛到唯一的最优价值函数,但是这里存在对动作空间和状态空间的积分,无法直接处理,本节来解决此问题
2.4.1 转换为优化问题
- 首先把上面这个迭代优化变形成一个优化问题,使用一个
θ
theta
θ 参数化的网络
Q
soft
θ
Q_{text{soft}}^theta
Qsoftθ 来近似
Q
soft
Q_{text{soft}}
Qsoft,同时通过在
V
soft
V_{text{soft}}
Vsoft 中引入重要性采样比,把积分转换由
Q
soft
θ
Q_{text{soft}}^theta
Qsoftθ 得到的期望形式
V
soft
θ
V_{text{soft}}^theta
Vsoftθ(转换为期望后就可以用随机优化方法了)
V s o f t θ ( s t ) = α log ∫ A exp ( 1 α Q s o f t θ ( s t , a ′ ) ) d a ′ = α log ∫ A q a ′ ( a ′ ) q a ′ ( a ′ ) exp ( 1 α Q s o f t θ ( s t , a ′ ) ) d a ′ = α log E q a ′ [ exp ( 1 α Q s o f t θ ( s t , a ′ ) ) q a ′ ( a ′ ) ] (4) begin{aligned} mathrm{V}^theta_{mathrm{soft}}left(mathrm{s}_{mathrm{t}}right) &=alpha log int_{mathcal{A}} exp left(frac{1}{alpha} mathrm{Q}^theta_{mathrm{soft}}left(mathrm{s}_{mathrm{t}}, mathrm{a}^{prime}right)right) mathrm{da}^{prime} \ &=alpha log int_{mathcal{A}} frac{mathrm{q}_{mathrm{a}^{prime}}left(mathrm{a}^{prime}right)}{mathrm{q}_{mathrm{a}^{prime}}left(mathrm{a}^{prime}right)} exp left(frac{1}{alpha} mathrm{Q}^theta_{mathrm{soft}}left(mathrm{s}_{mathrm{t}}, mathrm{a}^{prime}right)right) mathrm{da}^{prime} \ &=alpha log mathbb{E}_{mathrm{q}_{mathrm{a}^{prime}}}left[frac{exp left(frac{1}{alpha} mathrm{Q}^theta_{mathrm{soft}}left(mathrm{s}_{mathrm{t}}, mathrm{a}^{prime}right)right)}{mathrm{q}_{mathrm{a}^{prime}}left(mathrm{a}^{prime}right)}right] end{aligned} tag{4} Vsoftθ(st)=αlog∫Aexp(α1Qsoftθ(st,a′))da′=αlog∫Aqa′(a′)qa′(a′)exp(α1Qsoftθ(st,a′))da′=αlogEqa′[qa′(a′)exp(α1Qsoftθ(st,a′))](4) 这里引入的 q a ′ q_a' qa′ 可以是动作集上的任意分布。之后的操作完全类似 DQN,首先利用 soft Bellman optimal equation 构造 TD target,再通过优化 L2 损失来靠近它,即最小化
J Q ( θ ) = E s t ∼ q s t , a t ∼ q a t [ 1 2 ( Q ^ s o f t θ ˉ ( s t , a t ) − Q s o f t θ ( s t , a t ) ) 2 ] 其中 Q ^ s o f t θ ˉ ( s t , a t ) = r t + γ E s t + 1 ∼ p s [ V s o f t θ ˉ ( s t + 1 ) ] J_{Q}(theta)=mathbb{E}_{mathbf{s}_{t} sim q_{mathbf{s}_{t}}, mathbf{a}_{t} sim q_{mathbf{a}_{t}}}left[frac{1}{2}left(hat{Q}_{mathrm{soft}}^{bar{theta}}left(mathbf{s}_{t}, mathbf{a}_{t}right)-Q_{mathrm{soft}}^{theta}left(mathbf{s}_{t}, mathbf{a}_{t}right)right)^{2}right] \ 其中spacespacehat{Q}_{mathrm{soft}}^{bar{theta}}left(mathbf{s}_{t}, mathbf{a}_{t}right)=r_{t}+gamma mathbb{E}_{mathbf{s}_{t+1} sim p_{mathrm{s}}}left[V_{mathrm{soft}}^{bar{theta}}left(mathbf{s}_{t+1}right)right] JQ(θ)=Est∼qst,at∼qat[21(Q^softθˉ(st,at)−Qsoftθ(st,at))2]其中 Q^softθˉ(st,at)=rt+γEst+1∼ps[Vsoftθˉ(st+1)] 这里构造 L2 损失的 ( s , a ) (s,a) (s,a) 分布,以及上面式 (4) 引入的动作分布 q a ′ q_a' qa′ 都可以是任意的,作者的做法是- 构造 L2 损失的 ( s , a ) (s,a) (s,a) 分布:从 replay buffer 采样 s s s,再从当前策略 Q soft θ Q^theta_{text{soft}} Qsoftθ 所诱导的策略 π pi π 中采样生成对应的 a a a
- q a ′ q_a' qa′:使用当前策略 Q soft θ Q^theta_{text{soft}} Qsoftθ 所诱导的策略对应的分布 π ( ⋅ ∣ s t ) pi(cdot|s_t) π(⋅∣st)
2.4.2 从 energy-based 分布中采样
- 接下来的问题特别棘手,为了执行上面的优化,必须从当前估计的价值
Q
soft
θ
Q^theta_{text{soft}}
Qsoftθ 所诱导的策略
π ( a t ∣ s t ) ∝ exp ( 1 α Q soft θ ( s t , a t ) ) pi(a_t|s_t) propto expleft(frac{1}{alpha}Q^theta_{text{soft}}(s_t,a_t)right) π(at∣st)∝exp(α1Qsoftθ(st,at)) 中采样,从这样的玻尔兹曼分布中采样是很困难的,过去的方法通常可以分两类基于马尔可夫链蒙特卡洛法 Markov chain Monte Carlo, MCMC 进行采样。这种方法无法进行在线推理,不适用训练一个随机采样网络,可以直接从目标分布中生成样本。这个其实很像 GAN 这类生成方法的 generator,具体而言就是要训练一个 ϕ phi ϕ 参数化的网络 f ϕ f^phi fϕ,它把来自给定分布(如高斯)的随机噪音 ξ xi ξ 映射为一个采样自目标分布的样本,这样就能如下采样动作了
a t = f ϕ ( ξ ; s t ) a_t= f^phi(xi;s_t) at=fϕ(ξ;st) 作者在此使用了 Stein variational gradient descent (SVGD) 方法,它有如下特点- 可以得到一个采样网络,快速从目标分布中生成样本
- 已经证明,它可以收敛到 EBM 模型后验分布的一个准确估计
- 得到的采样网络形式上看很像 Actor-Critic 框架中 Actor 的角色,从这个角度看 2.4.1 节的价值估计就相当于 Critic,这样能把 Value-based 类方法 Q-learning 和 Policy Gradient 类方法 Actor-Critic 联系起来
- 概述一下 SVGD 的思路,把采样网络表示为
π
ϕ
(
a
t
∣
s
t
)
pi^phi(a_t|s_t)
πϕ(at∣st),我们的目标是找到最优网络参数
ϕ
phi
ϕ 使得它对任意
s
t
s_t
st 表示的分布尽量靠近
Q
soft
θ
Q^theta_{text{soft}}
Qsoftθ 所诱导的策略分布。也就是要优化以下 KL 散度
J π ( ϕ ; s t ) = D K L ( π ϕ ( ⋅ ∣ s t ) ∥ exp ( 1 α ( Q s o f t θ ( s t , ⋅ ) − V s o f t θ ) ) ) J_{pi}left(phi ; mathbf{s}_{t}right)= mathrm{D}_{mathrm{KL}}Big(pi^{phi}left(cdot mid mathbf{s}_{t}right) | exp left(frac{1}{alpha}left(Q_{mathrm{soft}}^{theta}left(mathbf{s}_{t}, cdotright)-V_{mathrm{soft}}^{theta}right)right)Big) Jπ(ϕ;st)=DKL(πϕ(⋅∣st)∥exp(α1(Qsoftθ(st,⋅)−Vsoftθ))) 我们可以先从给定分布中独立采样一组噪声 { ξ ( i ) } {xi^{(i)}} {ξ(i)},然后用随机初始化的采样网络得到一组 a t ( i ) = f ϕ ( ξ ( i ) ; s t ) a_t^{(i)} = f^phi(xi^{(i)};s_t) at(i)=fϕ(ξ(i);st)。接下来的每轮迭代中,我们对这组被采出来的样本 { a t ( i ) } {a_t^{(i)}} {at(i)} 施加扰动 △ f ϕ ( ξ ( i ) ; s t ) triangle f^phi(xi^{(i)};s_t) △fϕ(ξ(i);st),使上述 KL 散度不断减小,这样多次迭代后 { a t ( i ) } {a_t^{(i)}} {at(i)} 就可以看作真的来自目标分布了。SVGD 方法给出了扰动的最佳方向为
Δ f ϕ ( ⋅ ; s t ) = E a t ∼ π ϕ [ κ ( a t , f ϕ ( ⋅ ; s t ) ) ∇ a ′ Q s o f t θ ( s t , a ′ ) ∣ a ′ = a t + α ∇ a ′ κ ( a ′ , f ϕ ( ⋅ ; s t ) ) ∣ a ′ = a t ] Delta f^{phi}left(cdot ; mathbf{s}_{t}right)=mathbb{E}_{mathbf{a}_{t} sim pi^{phi}}left[left.kappaleft(mathbf{a}_{t}, f^{phi}left(cdot ; mathbf{s}_{t}right)right) nabla_{mathbf{a}^{prime}} Q_{mathrm{soft}^{theta}}left(mathbf{s}_{t}, mathbf{a}^{prime}right)right|_{mathbf{a}^{prime}=mathbf{a}_{t}}right.left.+left.alpha nabla_{mathbf{a}^{prime}} kappaleft(mathbf{a}^{prime}, f^{phi}left(cdot ; mathbf{s}_{t}right)right)right|_{mathbf{a}^{prime}=mathbf{a}_{t}}right] Δfϕ(⋅;st)=Eat∼πϕ[κ(at,fϕ(⋅;st))∇a′Qsoftθ(st,a′)∣ ∣a′=at+α∇a′κ(a′,fϕ(⋅;st))∣ ∣a′=at] 其中 κ kappa κ 是一个核函数,SVGD 其实是在再生核希尔伯特空间中优化了两个分布间的 Kernelized Stein Discrepancy,最后得到的 Δ f ϕ ( ⋅ ; s t ) Delta f^{phi}left(cdot ; mathbf{s}_{t}right) Δfϕ(⋅;st) 并不是上面 J π ( ϕ ; s t ) J_{pi}left(phi ; mathbf{s}_{t}right) Jπ(ϕ;st) 的精确梯度,不过二者具有相同的方向,这样就可以设 ∂ J π ( ϕ ; s t ) ∂ a t ∝ Δ f ϕ frac{partial J_{pi}left(phi ; mathbf{s}_{t}right)}{partial a_t}propto Delta f^{phi} ∂at∂Jπ(ϕ;st)∝Δfϕ,再用链式法则就能得到
∂ J π ( ϕ ; s t ) ∂ ϕ ∝ E ξ [ Δ f ϕ ( ξ ; s t ) ∂ f ϕ ( ξ ; s t ) ∂ ϕ ] frac{partial J_{pi}left(phi ; mathbf{s}_{t}right)}{partial phi} propto mathbb{E}_{xi}left[Delta f^{phi}left(xi ; mathbf{s}_{t}right) frac{partial f^{phi}left(xi ; mathbf{s}_{t}right)}{partial phi}right] ∂ϕ∂Jπ(ϕ;st)∝Eξ[Δfϕ(ξ;st)∂ϕ∂fϕ(ξ;st)] 至此就能用任意梯度方法对 ϕ phi ϕ 进行优化了,最后得到的 π ϕ ( a t ∣ s t ) pi^phi(a_t|s_t) πϕ(at∣st) 还可以直接用作策略网络Note:关于 SVGD 的详细说明可以参考 [论文解读 02]Stein变分梯度下降详细解读
2.5 伪代码
- 给出 Soft Q learning 的伪代码如下

3. 实验
- 这个方法比较早了,实验就不详细写了,简单说就是验证了 1.1 节中的三个优势
4. 总结
- SQL 的主要意义是启发了当前几乎最流行的 model-free 方法 SAC,它本身基本已经没人用了,这里直接引用别人总结的 SQL 特点:论文笔记之Soft Q-learning
- SQL是一种
随机性策略算法,不是确定性策略,他的随机性并不像 DDPG 或者 TD3 那样的启发式,而是通过能量模型使得各个动作最终都有一定概率会被选择,可以体现出 Q value 的多峰性质 - 使用
采样网络对难以采样的能量模型分布进行动作采样 - 使用
IS技术将积分转为期望,从而可以将 V 加入到随机优化中 - SQL使用了2种优化算法,一种是确定性方向的SVGD,另一种是我们常用的随机性优化方法Adam
- 将采样网络看成是Actor网络的话,SQL的结构和DDPG这种AC算法没什么差异
- 改变了经典的期望累计奖励目标函数,增加了熵项,因此还需要改变贝尔曼等式,重新设计策略评估与策略提升过程(这个东西在后面的 SAC 中也用了)
- Theorem 1 证明了玻尔兹曼策略是最大化含熵目标的最优解
- SQL的 “S” 来自于其EBM模型的分布很像 softmax 函数,所以截取了 “soft”
- 最大化含熵目标的优点:抗干扰强、适用于多模任务、某个任务输出的这种策略可以作为下个任务的初始化策略、探索性强、鲁棒性强等。缺陷在于SVGD计算复杂度高,因此也可以放弃SVGD,用随机优化来替代,比如SAC算法中就这样做了。
- SQL是一种
- 附一篇比较清晰的解读 Soft Q-learning解读
最后
以上就是洁净万宝路最近收集整理的关于论文理解【RL经典】—— 【SQL】Reinforcement Learning with Deep Energy-Based Policies1. 思想2. 本文方法3. 实验4. 总结的全部内容,更多相关论文理解【RL经典】——内容请搜索靠谱客的其他文章。








发表评论 取消回复