

作者 | Just
出品 | AI科技大本营(rgznai100)
“我发现,软件研发总会延期。”一流科技CEO袁进辉说。
按照他的预期,深度学习框架OneFlow做两年就能开源给开发者检验,但时间向后延长了近一年半,“确实预计的不准”。
但无论如何,经过1300多天的打磨,一个由30多人团队打造的基于静态调度和流式执行技术的OneFlow深度学习框架终于问世。
对于刚刚在GitHub开源的OneFlow,袁进辉总体打85分。
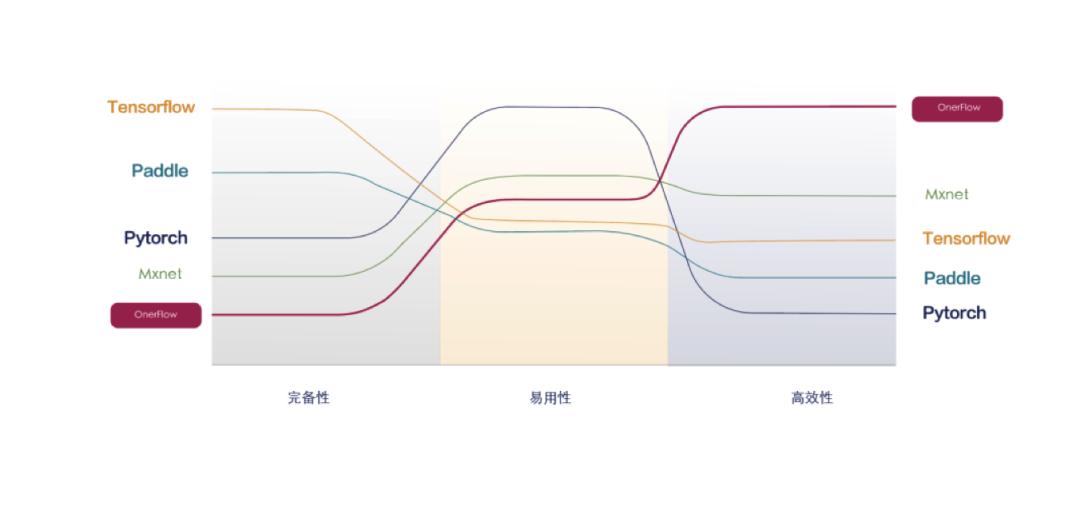
与其他几个“国产”AI框架相比,袁进辉认为,在完备性上,OneFlow比在今年3月开源的MindSpore和MegEngine要更好,不过支持的模型库还是比2016年就开源的PaddlePaddle要少。
效率方面,OneFlow的一类优势是“人有我优”,比如其他框架做数据并行得90分,他们进一步“挖油水”,做到接近100分;还有一类叫“人无我有”,其他框架基本只有深度定制才能支持超大模型,而OneFlow可以轻易做到。袁进辉给出了一组数据对比,显示其他框架在大规模模型训练效率上与OneFlow对比,有着数量级的差距。
而在多卡的易用性上,OneFlow要比其他框架要好,但在支持动态图方面,袁进辉也坦承与PyTorch有差距,不过很快可以追上。
2017年1月,PyTorch正式推出,TensorFlow正如日中天。彼时,国内外除了一线大厂,鲜有创业公司敢去啃AI框架这一硬骨头,但刚刚成立的一流科技却对此很坚定,即便那时从资金、团队、生态、品牌各个维度上来看,外界认为他们做的是Mission Impossible。
他们的信心源自对底层技术方向的把握。2015年,当时还在微软亚洲研究院的袁进辉(网名:老师木)已经研究了快两年的AI框架,和内部专家有过很多交流碰撞,这让他坚定要做一款不同技术方向的AI框架,但那时在研究院找不到工程团队支持。袁进辉相信,如果能找到数十个“袁进辉”组团,就可以搞定这件大事。
2020年年初,在又一次因为估错开源时间延期后,OneFlow团队在七月的最后一天最终搞定,对外开源了二、三十万行代码。他们希望,把这个框架的精妙和创新之处,与每一位使用它的开发者分享。
GitHub链接:https://github.com/Oneflow-Inc/oneflow
OneFlow地址:https://www.oneflow.org/#

为什么是静态调度和流式执行
AI科技大本营:显然,现在OneFlow是真正接受广大开发者检验的时候了,跟之前的预期相比,你给目前开源的版本整体打多少分?
袁进辉:预期的肯定是想让框架综合来说都很好,但这样做工程量实在太大,所以现在只能在一个维度上非常有特色,有优势,整体我打85分,在扩展性这一个维度上是非常好的。
易用性方面,PyTorch是非常好的。TensorFlow完备性非常好,用户用这个框架做训练之后,要在服务器端部署,就要serving,在终端上部署要有轻量级版本,要搞可视化,要支持很多的算子,模型库要丰富,要能支持图像、强化学习,自然语言、广告推荐等应用,要什么要有什么,TensorFlow在这方面非常好。
还有扩展性或效率,就是算的快不快,比如用户投入10倍或100倍资源,能不能真的让它加速10倍或100倍,以及现在业界出现的Bert、GPT-3等大模型,你的框架能不能做。
OneFlow框架比较大的优势或特色,就是效率。
AI科技大本营:像GPT-3这些最新的模型OneFlow都会支持?
袁进辉:GPT-3是土豪才能玩的模型,不单是技术问题,暂时还不支持。Bert是支持的,还有像广告推荐、人脸识别、检测、图像分类,最常见的十几个模型一开源就会支持。
AI科技大本营:OneFlow架构大致分为哪几层?
袁进辉:最上面是模型库,模型库支持CNN等各种经典模型应用,还有Python的API层,基本上其它框架主要也是Python。最底层就是跟硬件打交道的,还有XLA、TVM这些编译器。
中间两层是OneFlow和其他框架差别比较大的地方,分别是编译层和执行层。编译层其实就是静态调度的实现,执行层就是计算图的执行。
AI科技大本营:OneFlow框架的设计理念和技术创新是什么?
袁进辉:架构是为目的服务的。我们最大的追求是降低用户使用多机多卡的难度,提升这方面的用户体验。
但不幸的是,目前的框架只解决这个需求里最简单的部分,也就是数据并行。如果神经网络模型参数量本身不大的话,现在所有框架都能有比较满意的结果,但后来又出现很多像Bert、GPT-3这种参数量巨大的新模型,以及超大规模的人脸识别,大规模广告推荐,这就需要支持参数分割的模型并行,模型运行在框架层面是一个非常挑战的难题,到今天绝大部分主流框架都没有这个功能,即使定制之后能跑通,效率也很惨,满足不了工业级需求。
另外,就是要解决编程效率问题,怎么让多机多卡分布式编程更容易,也是OneFlow多机多卡体验的一部分。
为了满足这个目的,OneFlow趟出了一条其他框架还没有走的路,也就是静态调度和流式执行。
AI科技大本营:静态调度和流式执行怎么解决问题的?
袁进辉:这跟深度学习算法和异构计算特点相关。深度学习的任务负载特征跟以前Hadoop,Spark面临的计算不一样。以前很多任务是批式处理,处理整体数据,计算粒度很大,但深度学习是随机梯度下降算法,是非常多小粒度的计算构成,接近流式计算,大数据系统里的Flink、Storm也是流式系统,与那些批式处理系统不一样。
底层支撑硬件也不一样,深度学习包含大量稠密计算,非常适合高度并行的加速卡,广泛地依赖于异构计算,既有CPU也有加速卡,不是以前的纯CPU集群,GPU等加速器处理更快。所以,每一片任务过来,都是百毫秒甚至在几毫秒以内差不多就完成了。
一个作业重包含数十万非常小的转瞬即逝的任务,每个任务粒度非常低,如果系统里面有一丁点不顺畅,可能就成为整个系统的瓶颈,因为所有的小任务都需要等着调度器做决策。
怎么解决这个问题?我们的思路是根据深度学习本身的特点,发掘出调度规律,让系统在计算发生之前提前得到很多调度的规律的和策略,这种情况下就能把所谓的运行时的那种额外的开销就降到尽可能的低,几乎降到可忽略不计,这就能克服异构的流式计算里非常严峻的挑战。
流式执行是做什么?在这种任务里的多个卡之间频繁的数据搬运,对整个计算任务来说也是一个非常显著的开销,那流式系统就能提前通过整体规划,在每一次计算发生之前,就把所需要的数据参数都提前取到,通过流水线把数据搬运和计算做完全地重叠。如果是以前那种批式处理的大数据系统,就没法做到。
所以,OneFlow的思路就是做一个偏静态调度和流式执行的系统。
AI科技大本营:针对多机多卡的问题,除了OneFlow提出的解决路径,市面上其他框架怎么做的?
袁进辉:在多机多卡任务上,还有解决那些复杂的超大模型场景上的探索,整个行业是比较初级的。像PyTorch只关注易用性的话,重点都是在单卡上,即使做多卡也是最简单的all reduce,调一下英伟达的NCCL库就好。
因为近期有一些大模型出来,模型并行、流水并行的方式,整个行业才开始关注,包括Google做的GPipe, Mesh-Tensorflow,还有华为MindSpore对这类模型进行探索,但大部分也仅仅是做一个插件,很难加入主干代码,要实现正确且高效是非常难的。
不谦虚地说,在解决多机多卡问题上,其他框架和OneFlow可能是一两年的差距。
AI科技大本营:按你说的,多机多卡算是强需求,其他框架怎么一开始就没考虑到这一点?
袁进辉:这是个好问题,有多方面的因素。一是大部分用户没有那么大规模的计算资源,有多机多卡的都是土豪,大部分用户面临的任务或场景还没到多卡的规模;二是从模型发展的情况来说,超大模型趋势是近期出现的,早期,大家的认知就是做数据并行就够了,也不是那么难。
三是不同的团队有不同策略,多机多卡属于公认的技术难题,但摘果子的时候大家肯定先摘低垂的果子,所以有的框架可能先做最广大用户看中的一些东西,把多机多卡的优先级往后移了,比如PyTorch一开始主打易用性,TensorFlow后来做多机多卡的加速比收益很低,很难用,但不妨碍它捕获大量的用户;四是,多机多卡需要GPU服务器之间有非常高速的带宽,这需要一些特殊的软件和硬件技术,像支持RDMA的以太网等技术还有普及的过程。
AI科技大本营:能支持超大模型,是OneFlow创业初期就有的判断还是后期偶然的顺势而为?
袁进辉:这也是个很好的问题。这个判断是创业初期就有的,但产生这个想法很具有偶然性。
有时候别人也问我,为什么你最先想到搞这种并行,我就回复,我提前预测到这是个刚需,是迟早会发生的事情,因为底层芯片中,单个芯片的计算力是有物理限制的,你必须通过互联方式等才可能解决。
在2008~2011年在清华计算机系做博士后时,对使用机器学习方法理解人脑神经网络结构的形成感兴趣。
2013年,我在微软研究院,这时深度学习已经热起来,就想把我博士后的课题“理解神经网络为什么work”做下去,到现在这个问题还没有令人满意的理论结果,以及为什么CNN这种从人脑结构中启发得到的网络,在应用上效果这么好?要研究这个理论味道十足的问题,那时就会面临一个挑战,理解参数量巨大的神经网络背后的机制,其实计算空间参数量巨大。
这个问题我在微软研究了一年,这种基于好奇心的研究又回到了计算的手段上。而当时的很多框架,要实现这种研究都不可能,这项研究只好无疾而终。我后面在微软又做了主题模型LightLDA,是一个非常大规模的模型,我更加相信,框架不能仅仅停留在做CNN这种很小参数量的模型。2014年年底,那时TensorFlow还没发布,我已经开始想象未来的深度学习框架是什么样。
后来,Caffe、TensorFlow发布后,仍然解不了我想要解决的巨大模型问题。所以,我还是要想办法用一种技术或者架构去设计出一个框架来支持大模型研究。
作为科学家,我有好奇心,就要竭尽全能去验证,我不想因为工具的缺失,验证不了一个idea。这就启发我和团队一直往这个方向去想,我们也去看别人框架怎么做,从历史中去学习经验,包括硬件迭代、高性能网络等等,最后不断提炼,把路线走通。
AI科技大本营:回到OneFlow框架整体的定位,它是一个首创了静态调度和流式执行架构的ML框架,这个核心定位到今天开源有没有发生过变化?
袁进辉:没有,因为问题没有变化。当时能想到的最好方法也就是这样的,从那时到现在好几年时间把几十个关键难题打通,现在的确看到效果是符合预期的。
如果说有什么扩展的话。过去一两年整个行业最大的变化就是PyTorch的崛起,应该很少人都预计到它能通过易用性捕获那么多用户,当然,易用性背后也有动态执行等一套技术支持,现在大家都这么搞了。所以在静态调度和流式执行外,OneFlow也补充了动态图执行的机制。

开发者上手门槛高不高
AI科技大本营:OneFlow更多强调的是工业级落地,对学界的开发者支持力度怎么样?
袁进辉:应该说,学界开发者也是我们很重视的。首先,已经提供了一些比较经典的模型,单机单卡的使用体验实事求是说和PyTorch有差距,但我认为会迟早追上。如果想用多机多卡或是单机多卡,OneFlow会很有优势,一个是效率的优势,一个是易编程的优势。
AI科技大本营:开发者上手容易吗?
袁进辉:我们努力把它做到上手体验和其他框架差不多,但我们为了提升分布式的易用性,引入了一些新的概念,可能需要开发者去了解、学习一下。当然,在单卡的情况下,和其它框架是差不多的,即使有差距我们也会更快补上。
AI科技大本营:文档写得够详细吗?
袁进辉:文档分三个层次。一部分是API文档,我们每个OP和TensorFlow、PyTorch几乎是一样的,而且即使有的地方没有文档,你看TensorFlow或PyTorch的文档也够了;还有用户搭建模型的文档,是比较全的;设计文档涉及到代码里面的架构,这是欠缺的,框架开源之后希望快速补上,我们会先放出一些比较high level的设计文档。
AI科技大本营:开源后,框架会如何优化?
袁进辉:我们要做的事还真的蛮多。有模型库的建设,我们希望用户最需要的那些模型都在OneFlow上有实现,而且在业界有竞争力,还要做和其他框架的兼容,文档的也要做。
还有一些比较深的技术难题,包括在框架和编译器,非常动态的神经网络,以及偏稀疏的网络怎么能在OneFlow框架上支持。
AI科技大本营:生态搭建在开源后的一两年应该比较重要,你们有没有实质性的初步规划?
袁进辉:这属于术的层面,包括策略、执行还有营销。最根本的还是两点:一,开源社区里有价值的东西,一定会出头;二,OneFlow本身的技术领先,这是我们非常坚定的。这两点是前提,后面要解决的问题就是,通过一些手段告诉别人这是好东西。
AI科技大本营:在支持上层应用落地上,你们是做to B服务,在场景落地和客户的选择上是否有优先次序?
袁进辉:肯定有。OneFlow框架主打效率和扩展,特别是头部的互联网企业、AI企业就有这个需求,我们并不是从这类企业里面去挣钱,而是真的满足它的需求,我们也愿意去做支持,希望能做成标杆客户,纯粹是为了增加OneFlow的应用场景。
AI科技大本营:开源后的商业化进程有没有什么计划?
袁进辉:框架要在整个平台下面去做商业化,需要和很多其他的模块系统配合,所以我们是有私有部署的解决方案,特别是传统大型企业背后的算力中心需要整套解决方案,这可以作为近期商业服务收入,未来要向云服务发展。

百家争鸣还是在向终局收敛
AI科技大本营:你现在还能相对客观的评价和总结一下,市面上其他主流框架的优势和不足吗?
袁进辉:先声明这是利益相关。我是遵从内心,还是不得罪别人呢?
TensorFlow,我觉得是最好,编译器、框架、 serving、 lite、可视化等都有,还有非常强大的算法科学家、应用场景和工程团队的支持,社区和生态非常强。不足之处是大而全,在任何一个单点上总能找到比它更好一点的框架,TensorFlow历史包袱太重,系统太复杂,难以及时吸收框架技术的新突破。
PyTorch,它的优势也是它的缺点,整个架构是为了解决易用性问题,技术较简单,整个工程复杂度比较低,切中了用户痛点,这是它的好处。不足之处在于,为未来特别是大规模需求考虑的不多,训练出来模型之后进行部署时也比较困难。
MXNet,早期的时候实际上有很多好的想法,但缺乏一个非常清晰的主路线,很长时间没有大的进步。
PaddlePaddle,完整度是很好的,在百度内部强制使用,有实践检验,但在技术上像跟随者的角色,没有突破和引领潮流。
MindSpore,团队很强,做全栈AI的战略上想得非常清楚,局部有技术创新,问题是对GPU的支持不足。
MegEngine,亮点是把训练和推理一体化了,但这个团队的基因是视觉,对自然语言处理、广告推荐、强化学习等应用的支持可能不在他们的视野之内。
AI科技大本营:你说过,在资源有限的情况下,做框架必须找到最正确的路径才能做到又快又好,从百家争鸣向终局收敛,现在是百家争鸣还是说技术框架的技术已经在收敛了?
袁进辉:我觉得是现在处于争鸣和收敛的过程中,离终局可能还有两年时间。
每一个框架上的生态就能像个黑洞一样,外界有什么新的想法也都为自己所吸纳。如果一个技术创新不是足够大的话,这个想法就很容易被生态最强的框架吸过去。所以新框架必须与众不同,这样别人吸收你会非常困难,你也就有一个时间窗口能站稳,拥有一波铁杆用户,才可能发展壮大。
AI科技大本营:收敛是不是意味着技术路线会走向同质化?
袁进辉:是的,各个框架现在来说长得越来越像了,因为我看你这个想法好,也按照你的套路去做,所以竞争非常白热化。我相信未来这个市场实际上会变成一个赢者通吃的局面。
AI科技大本营:你说竞争到了白热化,但总体来看,框架的数量是比较少的。
袁进辉:框架这个领域确实数量不多,因为复杂性和难度已经拦住了很多人,有很多人觉得做框架没有胜算,他就不会来做这个事,所以但凡进来的都是强者。
AI科技大本营:OneFlow会成为其中一个赢家吗?
袁进辉:原来是TensorFlow一家独大,PyTorch的出现造成各占百分之四五十的市场,我们相信OneFlow可以逐渐站住脚,先实现三分天下,甚至可以再进一步,我们有这个信心。
AI科技大本营:有人说,开发者对于训练和推理这两个维度的关注点不一样,在训练时更关注效率,推理时更关注低功耗,所以训练和推理可能会分化出两大框架市场,你是否同意?
袁进辉:肯定同意。训练有两个维度很重要,一个是易用性,研究员要快速的把自己的idea变成product,PyTorch是这个特点,另一个是扩展性,可以不计成本训练比较大规模模型。但是,在端上要考虑非常受限的场景,要考虑到端侧算力弱,功耗要求苛刻,这一定要是非常轻量的,甚至跑的模型都需要压缩,训练框架在端上都不work。虽然我刚才说赢者通吃,但在训练和推理上可能还是会分化出两套框架。
AI科技大本营:现在是做开源软件最好的时期吗?
袁进辉:开源背后有很深的话题,开源本质是什么?怎么来的?传播规律是什么?可谈的东西特别多。回到问题本身,现在确实是一个很好的时间,现在出现了专门做开源,和云结合的蛮好的To B商业模式,国内还有新基建的政策红利。

“从各个维度,他们都说不可能做成”
AI科技大本营:OneFlow框架的研发经历了几个阶段?
袁进辉:把我们的技术设想跑通就花了快两年时间,大约是2018年秋天;然后在这上面把经典的模型,调到满意的状态,又大概花了快一年的时间,主要是解决原来没预计到的问题;骨架打造好之后,最近半年都在做易用性、文档、模型库等能力。
AI科技大本营:之前你说今年第二季度会开源,但这个时间点明显延后了,发生了什么?
袁进辉:我们原来是计划一季度开源,那时旷视和华为也开源了,但我们发现他们模型丰富度有点单薄,会影响开源效果,为了做到一个比较令人满意的状态,就再推迟了三、四个月。
AI科技大本营:如果复盘一下,这三年来创业的最大感受是什么?
袁进辉:总的来说,在一些主要的事情上,没有做错什么。我们创业,主要的矛盾都来自于在非常受限的资源下如何做好一件非常难的事情。在这种情况下,再高超的管理、运作策略也没办法,矛盾在这儿就是非常激烈。
所以,如果能解决资源问题,肯定帮助很大。解决这些困难,我本人也经历了一个成长的过程,知道怎么和资本打交道,怎么说服技术高手加入。
解决资源问题,首先,创业者自己要想明白,想通想透。说服自己,你只需要想很近的东西。但要说服更多的人来一起帮助你,你就必须想到底,因为别人看到创始人也没想通,就没信心。其次,创业者不仅要想通,而且要能说明白,怎么以非常好的故事讲出来,得到别人认同。
AI科技大本营:什么时期感觉最困难?
袁进辉:2018年的秋冬,那时已经研发了一年半以上。创业者有个18个月魔咒的说法,也就是一年半没看到希望,没有正反馈,心态就会发生变化,会失去耐心。
我自己肯定非常坚定,但团队里不是每一个人都这么坚定,长时间没有正反馈,有一部分人信心和耐力到了极限,所以那个时间段,我又顶上去做了一段时间研发。同时,之前的融资也快花完了,那既是事实上的冬天,也是资本寒冬,公司处于濒死边缘,人员规模还做了收缩。
AI科技大本营:哪个机构解了OneFlow的燃眉之急?
袁进辉:快手,还有老股东。
AI科技大本营:快手为什么会投,有战略上的考虑吗?
袁进辉:快手创始人宿华在种子轮就投了我们。我们当时和快手在同一栋楼,也经常借他们的计算资源,所以知根知底,他们知道我们做的事是扎实的,是真的做出来了,只不过还差临门一脚。
当然,快手本身的业务规模很大,也非常需要大规模机器学习基础设施,这个需求是存在的,而且知道这个问题难度很大。
AI科技大本营:当时,内部和外部对你们最大的质疑是什么?
袁进辉:质疑有很多,从技术能力、生态逆转各个维度去看,都认为我们是不可能做成。
AI科技大本营:怎么面对这些质疑?
袁进辉:信心必须靠理性,通过扎实的分析论证这个事情一定会发生,这个需求一定会发生。不管是谁解决这个需求,迟早会走到我们设想的这条路上来。那时,我们已经走到这条路上了,而别人还没有入手这个方向,我们有先发优势,可能是世界上最先搞定这个问题的团队。
如果没有这些理性分析,就的确会觉得很难,会者不难,难者不会。当我们把这个路子想通时,就是执行的问题,只是说别人还不知道,别人看到也不相信,但对内部的人来说,它的发生只是时间早晚的问题。
AI科技大本营:现在所有的框架都在进步,而且其他企业的投入比OneFlow都要大,你说是因为坚定和信心,但从另一维度,是不是可以理解成你是相信开发者群体有着识别好产品的眼光?
袁进辉:的确。特别在开源的情况下,开发者可直接去做判断和体验,他能知道好坏,好的东西一定会得到认可。
AI科技大本营:OneFlow终于开源了,最近心情怎么样?
袁进辉:最激动的时刻在前面已经发生了,当技术设想打通那一刻,看到效果时最激动。现在其实比较平静,感觉很多事情都在预计之内,一件件自然发生而已。
AI科技大本营:要把OneFlow推给更多的开发者,对他们有什么想说的?
袁进辉:开发者群体蛮分化的,每位工作背景不同的人看重的点都不一样,刚开始没办法让所有的开发者满意。我最想和开发者朋友说的是,我本人目力所及,OneFlow确实包含了非常美好、精妙的创新想法,非常希望大家可以去感受下。当然,如果你发现一些问题,也希望大家包容、反馈,我们会尽快修复。
相关阅读:
2020,国产AI开源框架“亮剑”TensorFlow、PyTorch
《对标PyTorch,清华团队推出自研AI框架“计图”》
35 万行代码,旷视重磅开源天元深度学习框架 ,四大特性实现简单开发


推荐阅读
一键实现图像、视频卡通化,GAN又进化了
PyTorch 1.6、TensorFlow 2.3、Pandas 1.1同日发布!都有哪些新特性?
Python 还能实现图片去雾?FFA 去雾算法、暗通道去雾算法用起来! | 附代码
程序员必备基础:Git 命令全方位学习
微软直播马上开始,近百岗位等你来,快戳进直播间
最后
以上就是活力汉堡最近收集整理的关于TensorFlow、PyTorch夹缝之下:后浪的进击和野望的全部内容,更多相关TensorFlow、PyTorch夹缝之下:后浪内容请搜索靠谱客的其他文章。








发表评论 取消回复