仅此一文让你掌握OneFlow框架的系统设计(上篇)
OneFlow开源近半年,近期发布了v0.3.2版本,相较于上个大版本,我们又新增了众多算子和功能(如亚线性内存优化、Partial FC、足够灵活易用的新版Checkpoint…),同时完备性(如Serving)、易用性(全新的API)也在快速推进中,敬请期待。
两个月前我们通过DLPerf项目证明了OneFlow是世界上最快的深度学习框架:
成诚:OneFlow是如何做到世界最快深度学习框架的zhuanlan.zhihu.com
其中PK了经NVIDIA深度优化后的各个主流框架实现以及官方实现,对比了ResNet50和BERT这两个CV和NLP领域应用最广的模型在数据并行下的吞吐率和加速比。这两个月我们又做了大量的实验,对比了其他各个应用场景下的第三方框架,如:
- 超大规模人脸识别案例 vs InsightFace
- Wide&Deep vs HugeCTR
- GPT-2 vs Megatron-LM
- SSP vs PipeDream
- Optimizer-Placement-Optimization vs DeepSpeed ZeRO
- Auto Parallelism vs FlexFlow
实验证明了OneFlow这一套简洁的抽象(SBP + Actor)在支持各种模型并行、混合并行、流水并行、自动并行、ZeRO等方面是如此的简单高效。上述的每个特性,都有一个专门的第三方的框架项目对主流框架进行魔改,至少涉及了数千行的项目代码,而这些特性在OneFlow中要么是原生支持的特性,要么是新增一个Actor类型或者是一个图优化的Pass(几十行的代码)就可以支持的非常好。我们认为OneFlow这套设计不仅是性能最快的框架设计,同时也是分布式深度学习训练框架中最简单、最易扩展的框架设计。上述的每个实验,近期都会有专门的技术文章分享,感兴趣的小伙伴可以期待一下~
如果你对OneFlow这套致简致快的框架设计感兴趣,或者对深度学习框架、分布式系统感兴趣的话,本文就会让你完全掌握OneFlow的系统设计。相信读完这篇文章,你就会理解我们是如何看待分布式深度学习训练的,我们为什么要这样设计,这样设计的好处是什么,以及我们为什么相信OneFlow这套设计是分布式深度学习训练框架的最优设计。本文的主要内容如下:
-
深度学习框架原理
-
OneFlow系统架构设计(简略版)
-
OneFlow完整运行流程 与 各模块的交互方式
-
- 1. 分布式集群环境初始化
- 2. Python端搭建计算图
- 3. 编译期: OneFlow(JobSet) -> MergedPlan
- 4. 编译期: Compiler(Job)->Plan
- 5. 运行时: Runtime(Plan)
全文分上、中、下三篇。本文是上篇。
深度学习框架原理
深度学习框架是人工智能领域的“操作系统”,为深度学习相关的算法工程师提供一套简洁易用的用户接口,使之能方便的搭建深度学习模型,进行深度学习模型的训练、验证、测试、调参、迁移、部署、迭代开发等工作。同时深度学习框架作为底层硬件跟算法工程师之间的中间件,要做到设备无关,使得算法工程师可以不用关心具体的计算设备、存储设备的细节就能方便的开发模型。
深度学习框架本质上是一个基于张量(Tensor)之间的计算(Operator)表达式所组成的计算图(Graph)编译执行引擎,提供了一系列张量的定义、一元操作、二元操作等数学原语,并根据反向传播算法(Back Propagation)进行梯度自动求导以及模型更新。在大量数据分批次流入计算图进行模型训练之后,使得模型学习到数据中的内在关联关系,从而获得对应场景中的“智能”感知与判断能力。
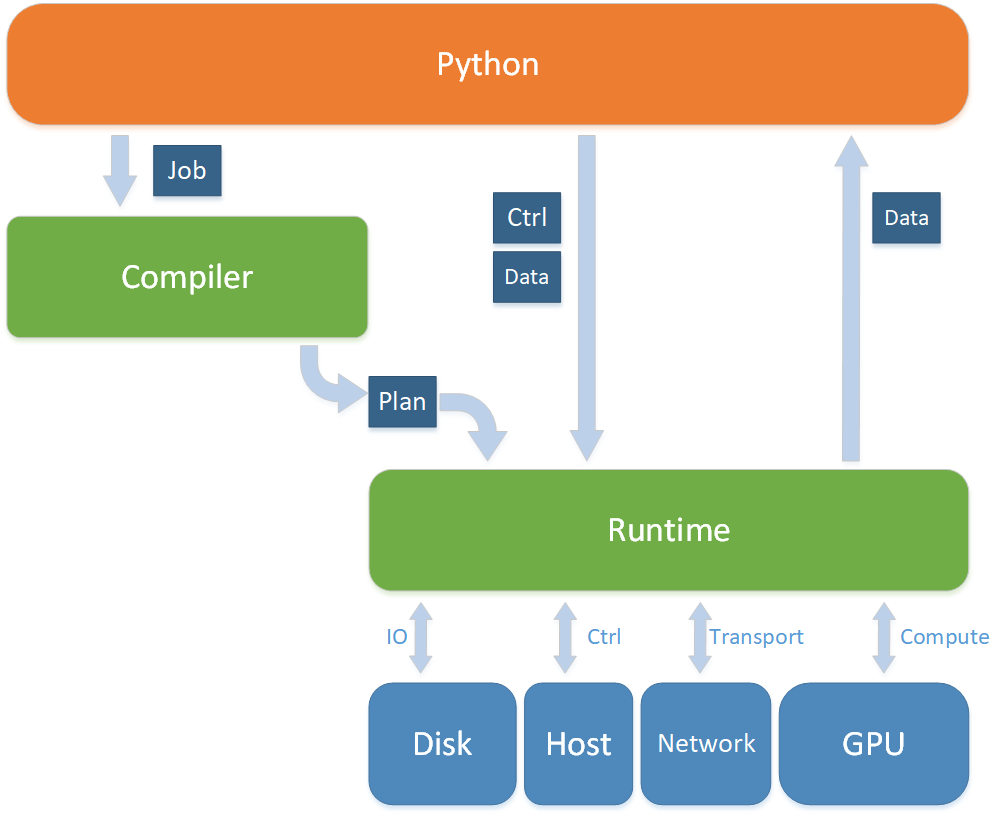
OneFlow系统架构设计
OneFlow总体分为3个层次: Python前端、编译期(Compiler)、运行时(Runtime)。
- Python端是用户接口,是OneFlow启动、编译、运行的入口,负责构建逻辑图(Job),且负责运行时跟底层计算图执行引擎交互,包括发送控制指令(运行一个global_function / job)、喂数据(input)、处理输出(output,callback)。
- 编译期(Compiler)负责将前端用户的定义的逻辑上的计算图进行编译,产出实际上的物理计算图 (Plan)
- 运行时(Runtime)负责根据Plan创建真正的执行图——即一个由Actor组成的去中心化流式计算图,每个Actor各司其职,有的Actor负责接收Python端的控制信号,有的Actor负责加载数据,有的Actor负责初始化模型、计算、更新、存储、传输…,有的Actor负责返还给Python端数据,数据在计算图中流动,实现深度学习的模型训练功能。
总体架构图如下图所示:
QA by @poohRui
想问一下今天分享的时候提到,OneFlow以op为基本单元,相比于PyTorch以Tensor为基本单元,这两个视角从整个框架的设计上来看有什么优缺点。
我觉得这正是OneFlow跟PyTorch的重要区别。
- PyTorch以Tensor为基本单元,更符合算法工程师写Python脚本的直觉,是一种以面向对象的方式进行模型搭建和训练,对Tensor进行赋值、切片,就像numpy一样易用。所以这种易用性更高。但在分布式情况下想把一个Tensor切分到不同机器上,需要手动构建传输过程,相当于直接对物理编程,所以对分布式使用的门槛更高。Tensor为基本单元,有一个好处就是mutable修改Tensor的值,是非常直观和简单的。
- OneFlow以Op为基本单元,模型搭建是用构图的方式实现的,单机单卡易用性不如以Tensor为基本单元,但分布式情况下对用户的门槛更低。因为有SBP可以让用户不用关心多机多卡情况下的Tensor切分和传输。SBP Signature是Op看待自己的输入输出Tensor的SBP,同一个Tensor,在其唯一的生产者Op和众多消费者Op眼中的SBP Parallel可能不一样,中间的boxing可以让框架来做。而单独拿一个Tensor来说,是没有SBP这个概念的,SBP是基于Op的视角来说的。以Op为基本单元,Tensor一般是不可修改的,仅该Tensor的生产者可以修改它。Tensor只是整个Op组成的计算图中流动的数据。如果在Op为基本单元的计算图中搞mutable消费,就会比较麻烦。
OneFlow完整运行流程 & 各个模块之间交互方式
我们通过介绍一次OneFlow完整运行的流程来了解系统中的各个主要模块是如何协同工作的。
1. 初始化环境(Env)
OneFlow是一个分布式计算系统,在Python前端启动时,第一件要做的就是初始化整个集群环境(Env)。环境由一个配置文件(EnvProto)所描述,里面包含了有多少台机器,每台机器的id、ip地址、控制端口号、数据传输端口号等信息。(Resource、MachineCtx等应该被合并进Env里)
- 如果是类MPI方式启动,各个机器会执行相同的Python脚本,每个机器在执行脚本时会判断得知自己的machine_id,从而知道自己是不是master:
- 如果不是master,则在Python脚本的入口就卡住,进入cluster的WorkerLoop()中循环、等待、执行集群中master发来的指令(Eager::Instruction)、逻辑图集合(Lazy::JobSet)。
- 如果是master,则真正执行python脚本,启动session、进入global function、构图…
- 如果是以ssh & worker的方式启动(目前主要使用这种方式,未来会替换成类MPI方式),则仅在master机器上启动了python进程,master会把oneflow_worker可执行程序通过ssh的scp命令拷贝到各个worker机器上,并根据配置执行oneflow_worker程序,进入WorkerLoop()的循环。
二者的区别:如果是类MPI的方式启动,各个机器上都需要安装oneflow的python包,每个机器上仅需要一份python脚本即可;而以ssh & worker的方式启动,需要把oneflow_worker的二进制文件临时拷贝到各个机器上,不需要python脚本。
环境启动时做了什么事呢?
- 各个机器上启动了oneflow的进程
- 创建CtrlServer和CtrlClient,并互相监听直到每台机器跟其他所有机器(包括自己)都建立了连接
Ctrl就是oneflow的控制平面(control plane),负责发送控制消息和数据,如master向worker发送JobSet、Plan等。
在OneFlow的Runtime阶段,每个机器都会创建CommNet全局对象,这是oneflow的数据平面(data plane),运行时各个机器上的Actor之间的消息通信、数据传输均通过数据平面发送。
控制平面使用rpc方式通信和传输数据,简单直接;数据平面通过高性能的网络(epoll,或者ibverbs)通信和传输数据,效率更高。这里补充一句,在使用ibverbs(RDMA)构建数据平面的过程中,RDMA的数据传输需要使用注册内存(pinned memory,又称锁页内存, page-locked memory)。而各个机器之间需要通信知晓各自的注册内存地址,这是通过控制平面rpc的方式传输注册内存的元信息的。见:IBVerbsCommNet::RegisterMemoryDone
2. Python端Job构图
在初始化环境之后,master上的python进程会执行用户在global function中的构图代码,生成Job。
Job是对整个逻辑图的基本描述,有两个主要部分: net和placement。
- net是一个op list,表述了整个网络是由哪些op以哪种方式连接起来的。net可以转化成一个DAG,图上的点表示一个op,图上的边表示op之间的产出和消费的tensor。
- placement表示了每个op放置在哪些设备哪些卡上。对于env里的所有机器以及所有设备,任何一个op都可以以任何方式分布在这些机器上。placement表示了逻辑上的op跟物理上的op的映射关系。
Python端通过C++(oneflow_internal_helper.h -> c_api_util.py)暴露出来的接口,实际上使用JobBuildAndInferCtx的AddAndInferOp接口进行推导。JobBuildAndInferCtx会保存已经加入的Op及其相关状态(SBP、shape等),并根据新加入的OpConf推导生成新的Op及其相关状态。同时JobBuildAndInferCtx会给Python端提供一系列查询接口,这样在Python的global function中的构图逻辑,后一个op的python代码在执行前,之前所有的op和tensor(的描述,TensorDesc)都已经构建好了,这样就实现了在global function中“类似eager的方式构图。
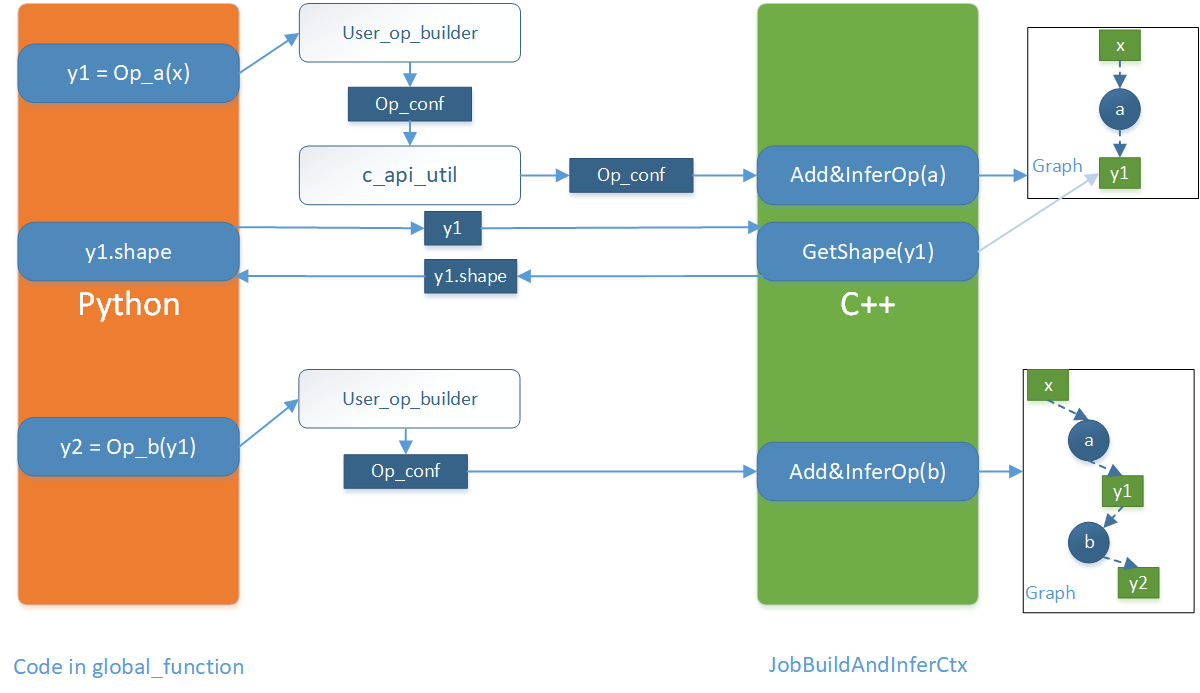
在整个global function中的代码都执行完之后,JobBuildAndInferCtx会被调用Complete,生成最终的用户定义的Job。
在Complete过程中,会调用执行多个JobPass,每个pass是对Job进行一次图修改、重写。其中最重要的pass就是生成后向op以及Optimizer(GenerateBackwardAndOptimizerOpConfs)。每个pass输入是一个job,输出是重写后的job。很多性能优化的pass也是这个时期做,比如“FuseAddToOutputPass”、自动混合精度"AutoMixedPrecision"等。
用户可能会定义多个global function(如cnn的train job和eval job),所有用户定义的Job构成一个集合(JobSet)。而OneFlow的C++主体对象Oneflow就只接收一个JobSet对象启动Complier和Runtime。
3. 编译期: OneFlow(JobSet) -> MergedPlan
由于历史原因,Oneflow的Complier仅编译单个Job,多Job的编译、Job间内存复用、MainPlan等均在Oneflow的CompileAndMergePlanOnMaster接口中执行。我们先假定Complier已经将Job编译成对应的Plan了(Compiler的编译过程我们放在后面讲)。
Oneflow生成最终的MergedPlan的流程:
输入是用户定义的多个job(已经过前后向展开以及各种图优化),我们称之为user job。
3.1 构建Model IO Job
Model IO Job中的每个Variable由全部user job中的Variable op name唯一确定。如果多个user job中有完全相同的Variable,则这两个Variable是内存共享的。即,Variable op的name是全局唯一的,是一个全局变量。举例:train job和eval job中的同名Variable共享同一份内存。
另外,Model IO Job(包含了三类 Model Init Job、Model Save Job、Model Load Job)中的Variable op,跟多个user job中的同名Variable也是内存共享的。
目前,OneFlow里有两种构建Model IO Job的方式(MakeModelIoJobs, MakeModelIoV2Jobs),分别表示这些Variable是共用一个Init/Load/Save op去处理,还是每个Variable单独一个Op去处理。下图展示了Model IO Job的几种形式:
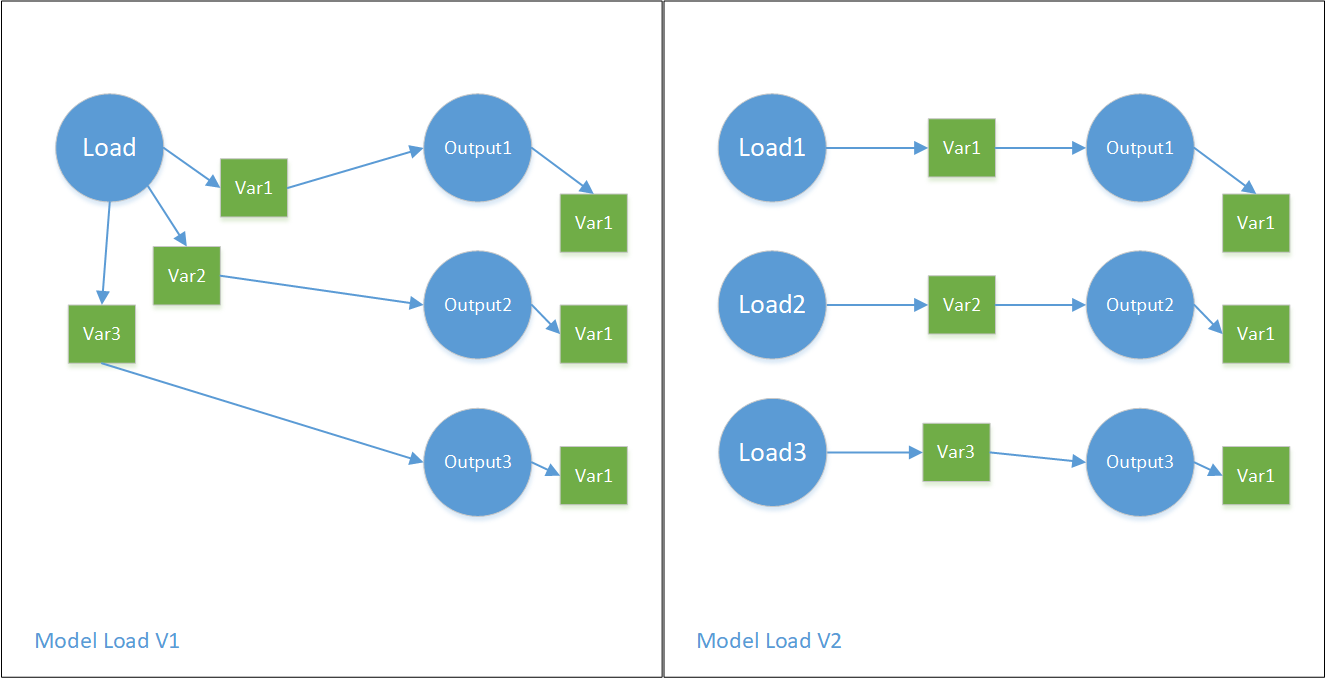
请注意,Model IO中真正存放各个模型的Op类型是Output,是InterfaceOp的一种。而不是Variable。Output1产出的Tensor::Var1跟其他某几个user job中的VariableOp::Var1内存共享。以此类推。
OneFlow中有几种类型的InterfaceOp:
- Input(Python端的global function输入Tensor)
- Output
- Return(Python端的global function的return Tensor)
Job之间的数据传递和绑定均通过InterfaceOp来实现。
InterfaceOp产出的Tensor的“RegstNum”恒为一,即仅有一份内存块,不支持流水;同时这块内存是被这个Tensor所独占的,不会跟系统中的其他Op产出的Tensor内存进行内存复用。
注:目前的Model IO是非常静态的,非常不利于用户对Checkpoint灵活使用的需求。@daquexian的新Model IO会彻底解决这个灵活性的问题。PR见: Oneflow-Inc/oneflow#3540
3.2 构建Push/Pull Job
遍历所有user job中的Input Op和Return Op,针对每个Input Op,分别构建一个对应的Push Job,针对每个Return Op,分别构建一个对应的Pull Job。Push/Pull的原理见下图:
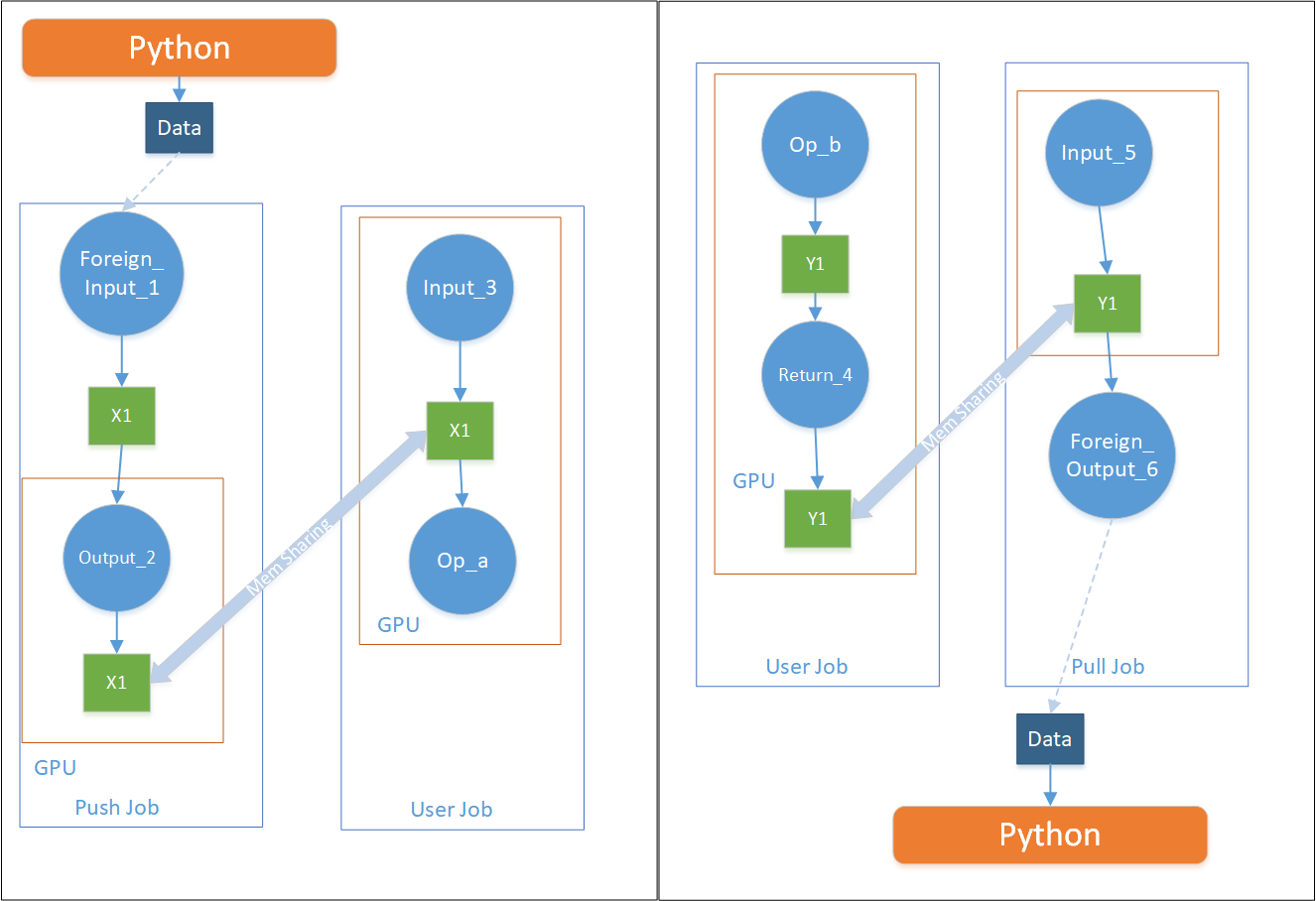
其中ForeignInput Op内部维护一个buffer,该buffer等待Python端喂数据,当数据喂完时该Op/Kernel执行完毕。ForeignOutput Op内部也有一个buffer,当往该buffer内填完数据以后,python端对应的of blob对象中的numpy就拷贝了对应的数据。
参见:
- ForeignInputKernel 与 ForeignOutputKernel
- Python端: OfBlob._CopyBodyFromNdarray() OfBlob._CopyToNdarrayListAndIsNewSliceStartMask()
- C++与Python端连接处: Dtype_GetOfBlobCurTensorCopyToBufferFuncName
为什么OneFlow与Python端的数据交换需要通过两种独立的Job子图实现?
有两个目的:
- 新增Push/Pull Job,并使用内存共享的方式,对原有的Job没有构图上的破坏。
- (主要目的)为了尽可能重叠Python与C++数据交换的过程。如何重叠?需要依赖OneFlow构图上的重要设计:MainJob和CriticalSection。我们放在下一节讲。
3.3 编译所有的job
顺序编译所有的user job和Model IO Job、Push/Pull Job。每个Job编译时,都是用Compiler完整编译至plan。且各个job之间不知道彼此的存在(历史原因)。
Compiler将一个Job编译成Plan的过程放在下一章节讲。
3.4 生成MainJob并得到最终的MergedPlan
这个过程分为几步。
1) 将每个Job生成的Plan(SubPlan)合并到一个大的MergedPlan中
2) Job之间的内存复用和内存共享 (OneFlow中的内存共享和内存复用是一个很大的话题,我们后面会专门单独写一篇文章分享其中的设计)
3) 计算CriticalSection
4) 生成MainJob
5) 编译MainJob得到MainPlan
6) 将MainPlan和MergedPlan中每个Job生成的SubPlan进行link,得到最终的MergedPlan
CriticalSection
CriticalSection是OneFlow构图中一个非常重要的概念——临界区。多个Job编译的多个Plan分布在各个临界区中。每个Job都关联多个临界区,临界区有两种类型:InputOutput 和 Total。其中InputOutput是根据这个Job的Input、Output、Return等特殊类型的Op专门设立的临界区,Total是每个Job必有的临界区,Job内的所有Op都被包含在Total临界区里。
整个JobSet会划分成众多临界区,临界区之间最重要的关系就是——互斥。如果两个临界区互斥,则其中一个临界区在执行的时候,另一个临界区必须等待。如果两个临界区不互斥,则可以并行同时执行。如何判断两个临界区是否互斥?借助全局概念的Op——InterfaceOp和VariableOp,如果两个临界区中的全局Op有同名,则这两个临界区在执行的时候会访问同一个全局的Op,则这两个临界区必然互斥,无法同时访问同一个全局Op。
临界区是比Job更细粒度的概念(但跟Op相比,仍然是粗粒度的)。
- 为什么要把Job分成多个临界区?
- 为什么要有InputOutput和Total两种类型的临界区?
原因是想让不同的Job之间尽可能流水并行起来。如何使得相邻的两个有消费关系的Job(Job A -> Job B, A的output被B的input消费/共享)同时执行?借助CriticalSection以及MainJob里的几个重要组件,我们就能实现多Job之间尽可能的并行执行。
Idea by @Ldpe2G
临界区的互斥可以区分读写互斥,这样多个只读的临界区可以并行执行,在某些场景下可以更好的流水并行。
MainJob
MainJob的结构图如下:
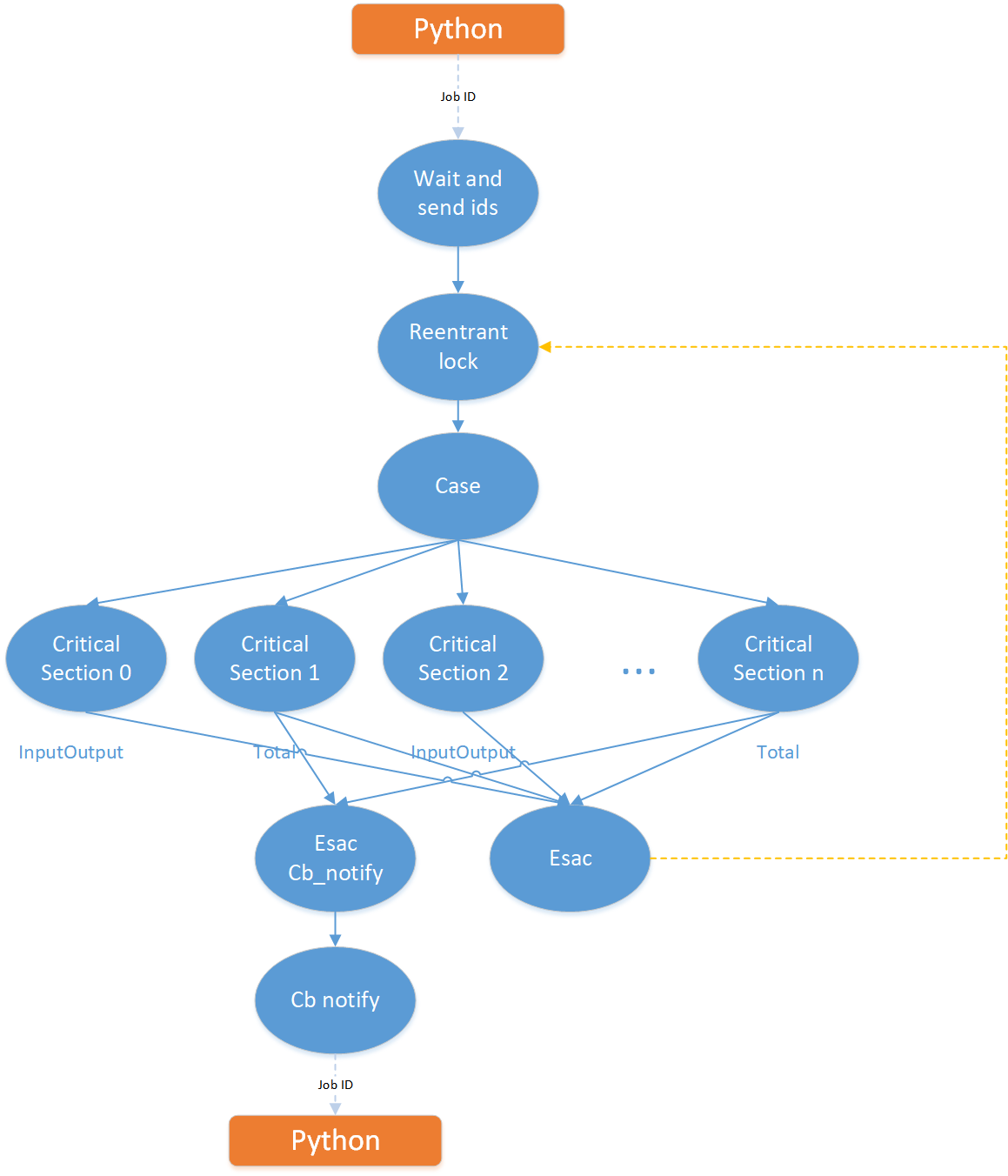
Main Job 的结构大体上反映了运行时Python端跟OneFlow系统的交互情况:
-
Python端每调用一次global_function,都会向WaitAndSendIds op发送一个job id,WaitAndSendIds会把收到的job id对应的多个CriticalSection id发送给ReentrantLock op。
-
ReentrantLock——可重入锁,里面维护了所有临界区之间的互斥情况,并且会维护一个等待队列。其输入有两个:
- 一个是python端发来的控制指令说要执行哪个Job对应的多个CriticalSection id,称之为“start”输入
- 另一个是esac返还回来的CriticalSection id,称之为“end”输入
start表示需要执行哪个CriticalSection,end表示哪个CriticalSection已经执行完了。每个输入都会更新可重入锁中的等待队列。由可重入锁来判断哪个CriticalSection可以被执行。
举例: start来了一个CriticalSection id 3。我们假设CriticalSection 3 与 0 互斥,且当前CriticalSection 0 正在被执行中,所以可重入锁会让3进入等待队列,直到0的执行完毕信号还回来时(end 来了 0),3可以执行了,那么才放3执行。
3) ReentrantLock会根据内部的临界区互斥情况和等待队列来判断要向下发送真正可以立即执行的CriticalSection id,发给Case op,Case Op执行的就是一个switch的操作,触发下面对应id的CriticalSection去执行。
4) MainJob的主体部分是所有的CriticalSection,注意在MainJob里每个CriticalSection用一个identity的tick op来标识。当整个MainJob编译成MainPlan后,会执行Link操作,将每个SubPlan连接替换MainPlan中的identity tick op。
5) 当某个CriticalSection执行完毕后,会给Esac op发消息。“Esac” 的命名是“Case”的字母逆序,因为其功能就是跟Case完全对称相反的。Esac会把执行结束的CriticalSection id发给ReentrantLock op(end输入)用于更新状态。
另外图中还有另外一个Esac op,仅连接了各个job对应的Total Critical Section,该op接收某个Job执行完毕的消息,并通过CallbackNotify Op发送给Python用于通知Python某个Job执行结束了,可以执行对应的Callback了(如loss收集、acc统计等)。
ReentrantLock + CriticalSection 实现Job之间的流水并行
我们假设一种Job之间的消费情况: Job A -> Job B,B消费A的输出,A和B均对应了多个CriticalSection,A对应0,1,2;B对应3,4,5,其中1,4是TotalCriticalSection类型,其余是InputOutputCriticalSection类型。由于两个Job仅在输入输出之间有消费关系,所以仅有2,3互斥,其余均不互斥。互斥关系如下图:
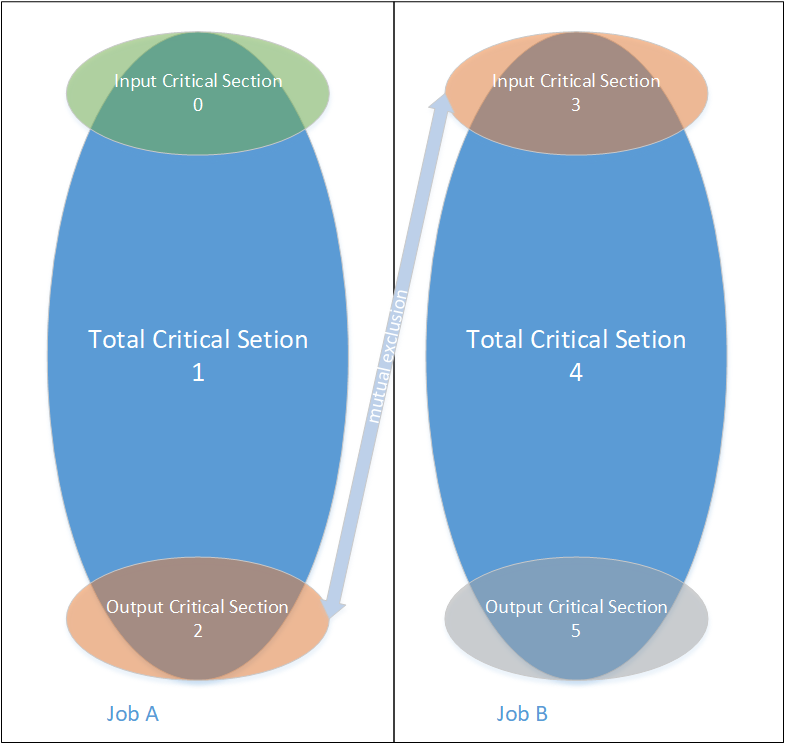
所以在ReentrantLock那里,仅会把2,3互斥相互block住。而两个Job的主体: (A, 1), (B, 4)是不互斥的。故当条件允许时,Job A和Job B可以流水并行执行。如果没有InputOutputCriticalSection,则A和B是一定会串行执行的。
在OneFlow中,Push/Pull Job跟对应的UserJob就是通过上述方式进行流水并行的。
小结
本文是OneFlow系统设计分享文章的上篇,介绍了深度学习框架原理、OneFlow系统架构的简略版,以及OneFlow完整运行流程的前半部分:从环境初始化到编译期MergedPlan生成。在下一篇《仅此一文让你掌握OneFlow框架的系统设计(中篇)》中,我们会介绍编译期Complier如何将Job编译成Plan的过程,其中会简要介绍OneFlow编译期最精华的Boxing章节,敬请期待~
最后
以上就是精明烧鹅最近收集整理的关于仅此一文让你掌握OneFlow框架的系统设计(上篇)仅此一文让你掌握OneFlow框架的系统设计(上篇)深度学习框架原理OneFlow系统架构设计OneFlow完整运行流程 & 各个模块之间交互方式的全部内容,更多相关仅此一文让你掌握OneFlow框架的系统设计(上篇)仅此一文让你掌握OneFlow框架的系统设计(上篇)深度学习框架原理OneFlow系统架构设计OneFlow完整运行流程内容请搜索靠谱客的其他文章。








发表评论 取消回复