云栖君导读:本文根据实测数据,初步探讨了在弹性GPU云服务器上深度学习的性能模型,可帮助科学选择GPU实例的规格。
一、背景
得益于GPU强大的计算能力,深度学习近年来在图像处理、语音识别、自然语言处理等领域取得了重大突GPU服务器几乎成了深度学习加速的标配。
阿里云GPU云服务器在公有云上提供的弹性GPU服务,可以帮助用户快速用上GPU加速服务,并大大简化部署和运维的复杂度。如何提供一个合适的实例规格,从而以最高的性价比提供给深度学习客户,是我们需要考虑的一个问题,本文试图从CPU、内存、磁盘这三个角度对单机GPU云服务器的深度学习训练和预测的性能模型做了初步的分析,希望能对实例规格的选择提供一个科学的设计模型。
下面是我们使用主流的几个开源深度学习框架在NVIDIA GPU上做的一些深度学习的测试。涉及NVCaffe、MXNet主流深度学习框架,测试了多个经典CNN网络在图像分类领域的训练和推理以及RNN网络在自然语言处理领域的训练。
二、训练测试
我们使用NVCaffe、MXNet主流深度学习框架测试了图像分类领域和自然语言处理领域的训练模型。
2.1 图像分类
我们使用NVCaffe、MXNet测试了图像分类领域的CNN网络的单GPU模型训练。
NVCaffe和MXNet测试使用ImageNet ILSVRC2012数据集,训练图片1281167张,包含1000个分类,每个分类包含1000张左右的图片。
2.1.1 CPU+Memory
2.1.1.1 NVCaffe
NVCaffe是NVIDIA基于BVLC-Caffe针对NVIDIA GPU尤其是多GPU加速的开源深度学习框架。LMDB格式的ImageNet训练集大小为240GB ,验证集大小为9.4GB。
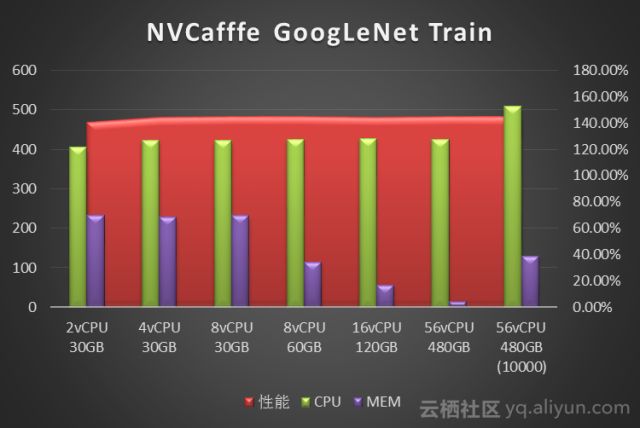
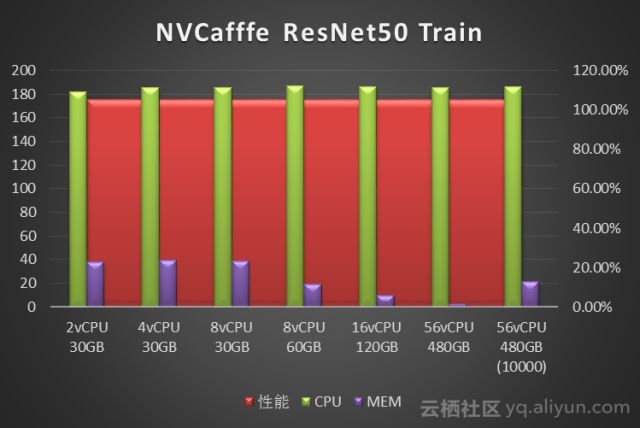
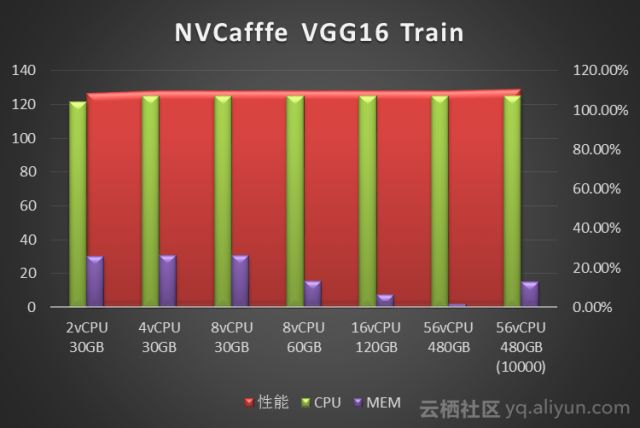
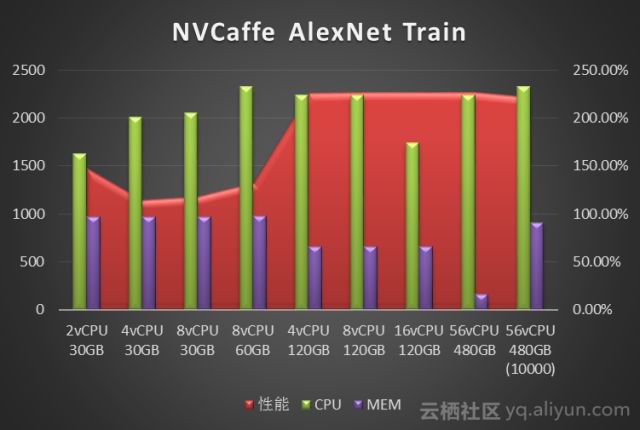
我们使用NVcaffe对AlexNet、GoogLeNet、ResNet50、Vgg16四种经典卷积神经网络做了图像分类任务的模型训练测试。分别对比了不同vCPU和Memory配置下的训练性能。性能数据单位是Images/Second(每秒处理的图像张数)。图中标注为10000指的是迭代次数10000次,其它都是测试迭代次数为1000次。
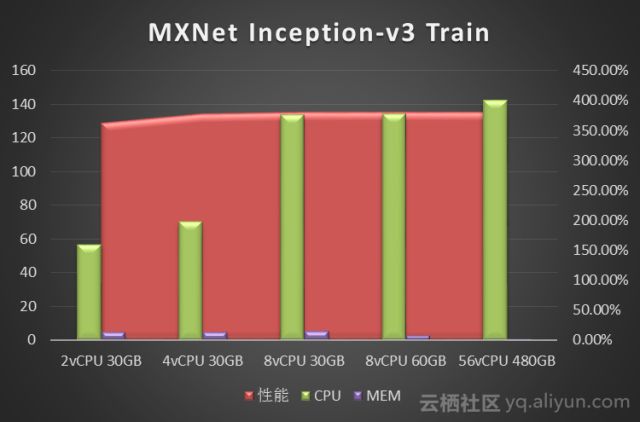
2.1.1.2 MXNet
MXNet的数据集使用RecordIO格式,ImageNet训练集 93GB ,验证集 3.7GB。
我们使用网络Inception-v3(GoogLeNet的升级版)做了图像分类的训练测试。分别对比了不同vCPU和Memory配置下的训练性能。数据单位是Samples/Second(每秒处理的图像张数)。
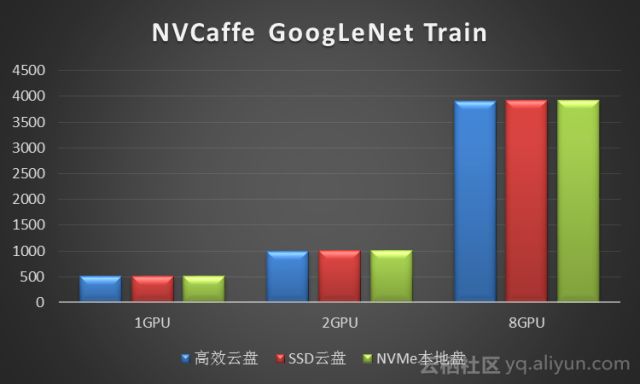
2.1.2 磁盘IO
我们在阿里云GN5(P100)实例上使用NVCaffe测试了GoogLeNet网络模型在NVMe SSD本地盘、SSD云盘和高效云盘上的训练性能,测试结果如下(性能数据单位是Images/Second):
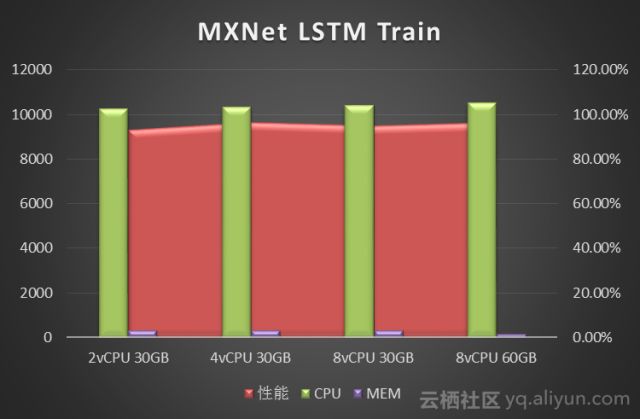
2.2 自然语言处理
我们使用MXNet测试了RNN网络的LSTM模型的训练,使用PennTreeBank自然语言数据集。PennTreeBank数据集的文本语料库包含近100万个单词,单词表被限定在10000个单词。分别对比了不同vCPU和Memory配置下的训练性能:
三、推理测试
3.1 图像分类
我们使用NVCaffe测试了图像分类领域的CNN网络的模型推理。
测试使用ImageNet ILSVRC2012数据集,验证测试图片 50000张。
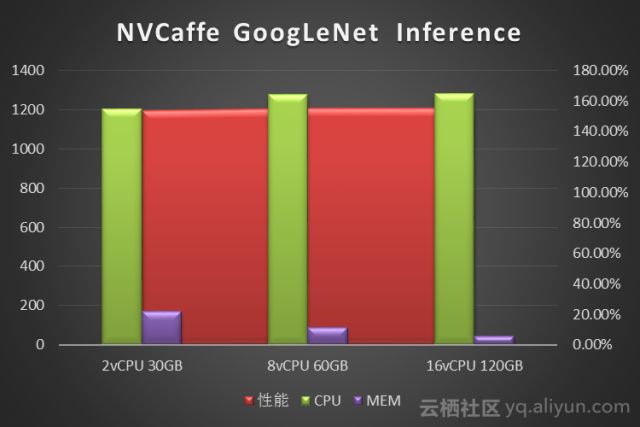
3.1.1 CPU+Memory
我们使用NVcaffe对AlexNet、GoogLeNet、ResNet50、VGG16四种经典卷积神经网络做了图像分类的推理测试。分别对比了不同vCPU和Memory配置下的训练性能。数据单位是Images/Second(每秒处理的图像张数)。
3.1.2 磁盘IO
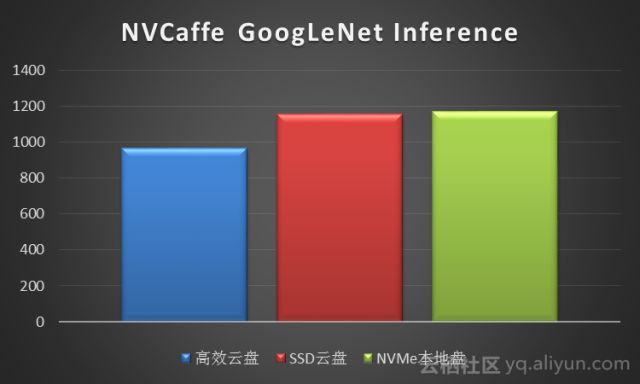
我们使用NVCaffe测试了GoogLeNet网络在NVMe SSD本地盘、SSD云盘和高效云盘上的图像分类推理性能,测试结果如下(数据单位是Images/Second):
四、数据预处理测试
在训练模型之前,往往要对训练数据集做数据预处理,统一数据格式,并做一定的归一化处理。
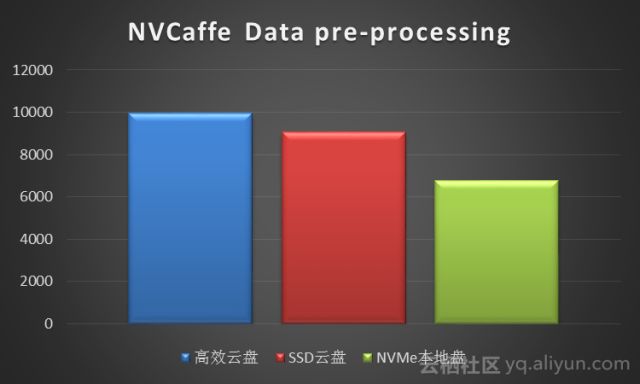
我们使用NVCaffe对ImageNet ILSVRC2012数据集做了数据预处理的测试,分别对比了NVMe SSD本地盘、SSD云盘和高效云盘的数据预处理时间,数据单位是秒,数据如下:
五、数据分析
5.1 训练
5.1.1 图像分类
从NVCaffe和MXNet的测试结果来看,图像分类场景单纯的训练阶段对CPU要求不高,单GPU 只需要4vCPU就可以。而内存需求则取决于深度学习框架、神经网络类型和训练数据集的大小:测试中发现NVCaffe随着迭代次数的增多,内存是不断增大的,但是内存需求增大到一定程度,对性能就不会有什么提升了,其中NVCaffe AlexNet网络的训练,相比其它网络对于内存的消耗要大得多。相比之下MXNet的内存占用则要小的多(这也是MXNet的一大优势),93G预处理过的训练数据集训练过程中内存占用不到5G。
对于磁盘IO性能,测试显示训练阶段NVMe SSD本地盘、SSD云盘性能基本接近,高效云盘上的性能略差1%。因此训练阶段对IO性能的要求不高。
5.1.2 自然语言处理
从MXNet的测试结果来看,对于PennTreeBank这样规模的数据集,2vCPU 1GB Mem就能满足训练需求。由于自然语言处理的原始数据不像图像分类一样是大量高清图片,自然语言处理的原始数据以文本文件为主,因此自然语言处理对内存和显存的要求都不高,从我们的测试来看,4vCPU 30GB 1GPU规格基本满足训练阶段需求。
5.2 推理
5.2.1 图像分类
从NVCaffe的图像分类推理测试来看,除AlexNet 2vCPU刚刚够用外,其它网络2vCPU对性能没有影响,而9.4GB的验证数据集推理过程中内存占用大概是7GB左右,因此对大部分模型来看,2vCPU 30GB 1GPU规格基本满足图像分类推理的性能需求。
对于磁盘IO性能,推理性能NVMe SSD本地盘、SSD云盘很接近,但高效云盘差15%。因此推理阶段至少应该使用SSD云盘保证性能。
5.2.2 自然语言处理
对于自然语言处理,参考训练性能需求,我们应该可以推测2vCPU 30GB 1GPU规格应该也能满足需求。
5.3 数据预处理
从NVCaffe对ImageNet ILSVRC2012数据集做数据预处理的测试来看,数据预处理阶段是IO密集型,NVMe SSD本地盘比SSD云盘快25%,而SSD云盘比高效云盘快10%。
六、总结
深度学习框架众多,神经网络类型也是种类繁多,我们选取了主流的框架和神经网络类型,尝试对单机GPU云服务器的深度学习性能模型做了初步的分析,结论是:
深度学习训练阶段是GPU运算密集型,对于CPU占用不大,而内存的需求取决于深度学习框架、神经网络类型和训练数据集的大小;对磁盘IO性能不敏感,云盘基本能够满足需求。
深度学习推理阶段对于CPU的占用更小,但是对于磁盘IO性能相对较敏感,因为推理阶段对于延迟有一定的要求,更高的磁盘IO性能对于降低数据读取的延时进而降低整体延迟有很大的帮助。
深度学习数据预处理阶段是IO密集型阶段,更高的磁盘IO性能能够大大缩短数据预处理的时间。
end
阿里巴巴千亿交易背后的0故障发布
阿里巴巴6大行业报告免费分享啦!
七本书籍带你打下机器学习和数据科学的数学基础
Logtail 从入门到精通:开启日志采集之旅
更多精彩

最后
以上就是魔幻爆米花最近收集整理的关于GPU云服务器深度学习性能模型初探的全部内容,更多相关GPU云服务器深度学习性能模型初探内容请搜索靠谱客的其他文章。








发表评论 取消回复