经过上一期我们介绍了xpath和beautifulsoup4提取数据之后,本章我们介绍一种新的提取数据的方法,就是正则表达是提取数据。
首先我们介绍什么是正则表达式,正则表达式就是按照一定的规则,从某个字符串中匹配出想要的数据,这个规则就是正则表达式。
import re#这个就是正则表达式的库
对于单字符匹配
import re
text='abc'
result=re.match('a',text)#从text中匹配a元素
下面我介绍一下所有的正则表达式的规则
. -表示匹配任意字符
D - 表示匹配任意非数字
d - 表示匹配任意数字
s - 表示空白字符
S - 表示非空白字符(包括n,t,r,空格)
w - 表示匹配是a-z,A-Z以及数字和下划线
W - 表示和w相反
- 号表示前一个字符匹配0次或者无限次
- 号表示前一个字符匹配一次或者无限次
正则表达式小案例:
1.验证手机号
import re
text='13166892143'
result=re.match('1[34587]d{9}',text)
print(result.group())
手机号必须第一步,第二位数字是34578,剩下9位随意匹配。
2.验证身份证号
import re
text='220122199605197535'
result=re.match('d{17}[d|x|X]',text)
print(result.group())
#有一些不严谨,在这里当作举例子用
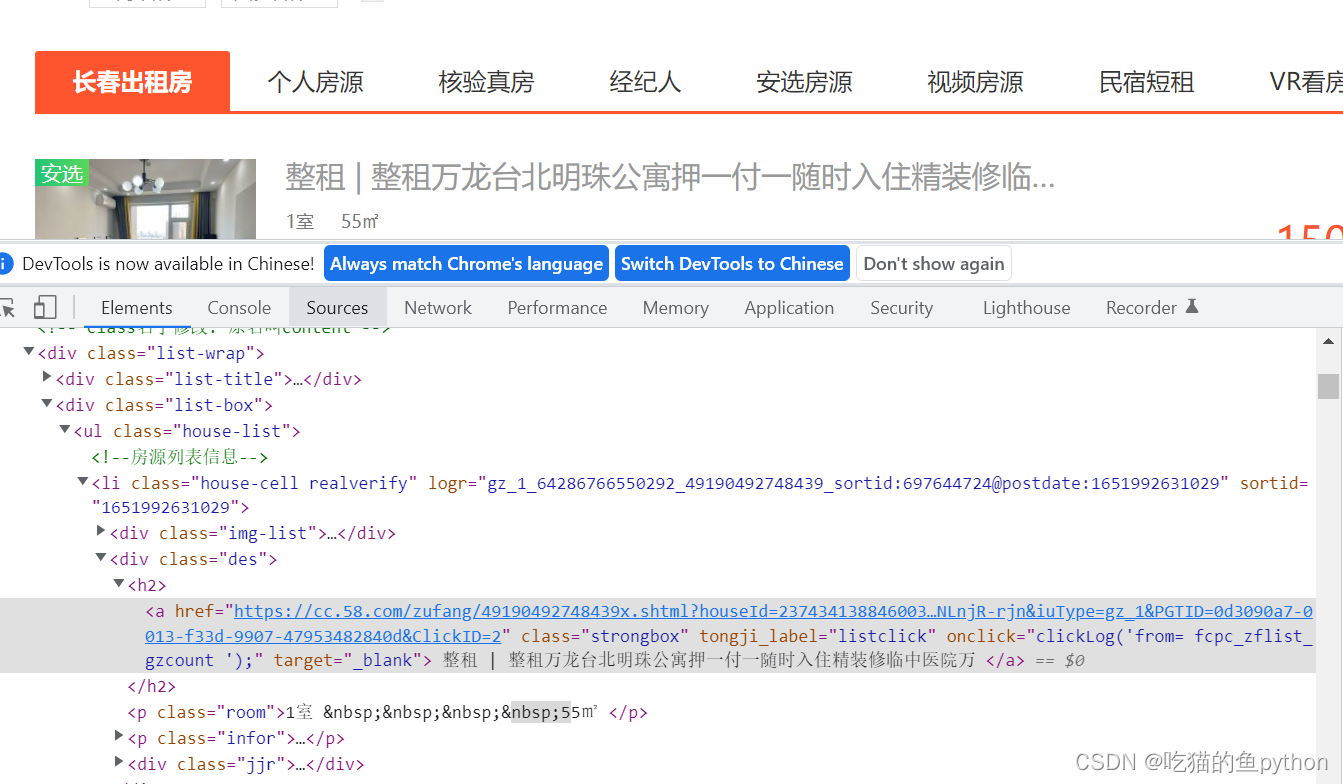
接下来进入到我们今天正则表达式的案例,爬取58同城长春的租房信息
首先我们找到url,然后找到headers,cookie,思想还是遵循前面的案例想法,但是为了避免重复我们只爬取标题,这样就不用进入到详情页面了。
import requests
import re
import time
def parse_url(page_url):
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36',
'cookie': 'f=n; commontopbar_new_city_info=319%7C%E9%95%BF%E6%98%A5%7Ccc; time_create=1651833783126; userid360_xml=5073453BC3F3378103306C5DD6313438; id58=CocNFmJMOjoRG6UpINqoAg==; 58tj_uuid=5f522b57-b5db-4c1e-91ad-dfaed5c54613; wmda_uuid=54945059623630baccf9ce2d19024bac; wmda_new_uuid=1; als=0; xxzl_deviceid=xZ3mzvUzZb7MfhlyfMjWDI43qItjOZEkCkzdMGVensviE4ufnO3TcSmfwuhOkOHN; 58home=cc; fzq_h=3668e23feed5ff34f5121533cacf4d11_1649165482837_aafa871639e1455faddcea1b2dcf0d7d_3688452105; aQQ_ajkguid=6909E4DE-8AC0-44AB-AAFD-564594183E03; sessid=29D9E48F-B91B-4704-B93F-802F0D536267; ajk-appVersion=; ctid=1; wmda_visited_projects=%3B2385390625025%3B11187958619315%3B1732038237441%3B10104579731767; xxzl_smartid=5258ec92b30a083b9c24b7abe6264f22; city=cc; xxzl_cid=2ac14936668549eba3f2d1267e499d31; xzuid=4b6daf1b-8235-4524-8294-5fadcc7a622c; f=n; commontopbar_new_city_info=319%7C%E9%95%BF%E6%98%A5%7Ccc; new_uv=3; utm_source=; spm=; init_refer=https%253A%252F%252Fcc.ganji.com%252F; wmda_session_id_2385390625025=1649241775503-9c4d1068-5b20-9030; commontopbar_ipcity=cc%7C%E9%95%BF%E6%98%A5%7C0; BAIDU_SSP_lcr=https://cc.ganji.com/; wmda_session_id_11187958619315=1649241776620-b94e118e-74a3-f619; new_session=0; wmda_session_id_10104579731767=1649242260725-d1698ea5-3e31-69e3; crmvip=; dk_cookie=; PPU=UID=50008179919636&UN=257yg0ij5&TT=85b0ddff390e2ad1cf9197b62a43bab6&PBODY=BtmW68AazGVFi-8GfV47Vx-GOH6uoejYuGjh242TlAQsKHxfn1ESmJKILSjwsl1eGTKKujjhFXG7bcNstnACkx6zImJtTYqABCmtaElOgYoYTqGN0qPRlsoWi1jNzJ-Te9xmrgFLIe2PNMQpN717DBCX7sZBka6WllSCVoaFwhE&VER=1&CUID=-PPNBXDEohf4g5_5jbNtDg; www58com=UserID=50008179919636&UserName=257yg0ij5; 58cooper=userid=50008179919636&username=257yg0ij5; 58uname=257yg0ij5; passportAccount=atype=0&bstate=0'}
#在这里我们找到了页面的headers和cookie
proxy={'http':'http://120.220.220.95:8085'}
resp=requests.get(page_url,headers=headers,proxies=proxy)
#在这里我们换了一下ip,也相当于复习一下之前的知识
text=resp.text
houses=re.findall(r"""
<div.+?des.+?<a.+?strongbox.+?>(.+?)</a>
""",text,re.VERBOSE|re.DOTALL)#获取房子的标题
#从上面的图中我们看到属于该标题的标签,然后我们从div属性为list-box标签开始匹配,.+?属于匹配中间任意字符(.+?)就是我们需要的东西,加上re.DOTALL参数后,就是真正的所有字符。使用re.VERBOSE来编写注释,使用re.IGNRECASE来忽略大小写
for house in houses:
print(house)
time.sleep(2)
#这样我们就可以把标题进行提取下来了
def main():
base_url='https://cc.58.com/chuzu/pn{}/?PGTID=0d3090a7-0013-f36b-4062-dd5eb66bbf85&ClickID=2'
for x in range(1,11):
page_url=base_url.format(x)
parse_url(page_url)
#base_url就是网页的规律,然后我们准备爬取10页的数据,进行爬取
if __name__ == "__main__":
main()
同样我们也可以对其进行详情页面进行数据提取,就是在上面的函数中获取到详情页面的url,然后在提取详情信息。我们把主体框架写出来,各位有需求的可以在这个基础上继续提取。
<div.+?des.+?<a.+?="(.+?)".+?ass.+?strongbox.+?>.+?</a>
这里我们写了一下提取详情页面的url,写的比较草率,但是可以提取到。谢谢各位大佬的观看!
最后
以上就是迷人狗最近收集整理的关于爬虫数据提取-正则表达式re提取网页数据信息的全部内容,更多相关爬虫数据提取-正则表达式re提取网页数据信息内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复