先看下内核中双向链表的大概样子:
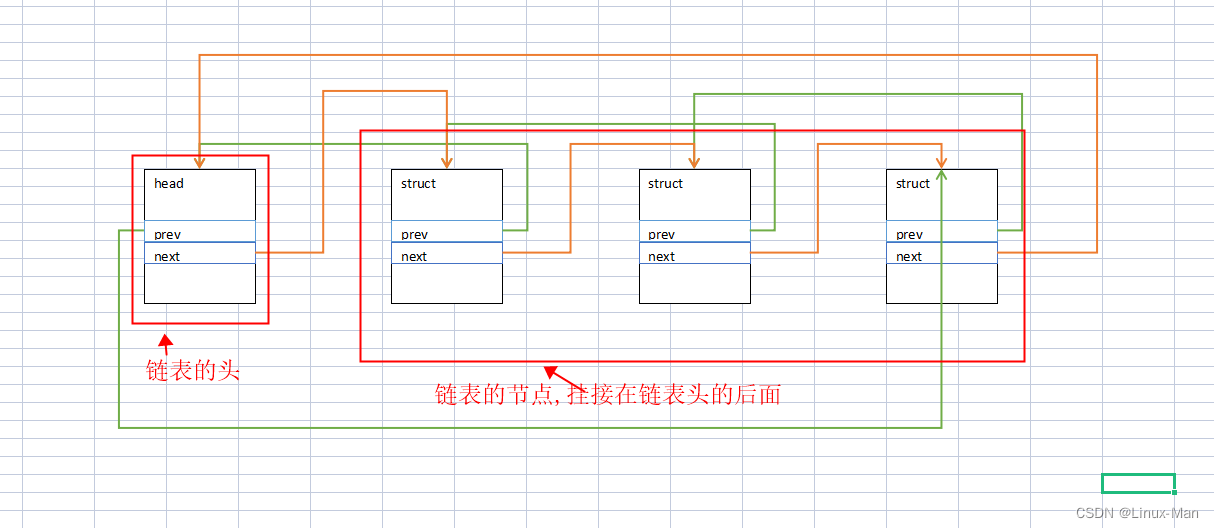
有映像后,再来看看,怎么通过这个宏来遍历这个列表
宏定义的功能:
通过一个链表头地址head,遍历挂接在这个链表上的所有结构体,这些结构体中挂在链表上的成员变量名字叫做member,每遍历一个,将这个结构体的地址放在pos中,后续就可以使用pos这个指针来操作这个结构体;
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_head within the struct.
*/
#define list_for_each_entry(pos, head, member)
for (pos = list_first_entry(head, typeof(*pos), member);
&pos->member != (head);
pos = list_next_entry(pos, member))kernel中的代码例子:
/*capsnap是一个临时变量*/
struct ceph_cap_snap *capsnap = NULL;
/*ci是通过某种方式得到的一个ceph_inode_info结构体指针*/
struct ceph_inode_info *ci = ceph_inode(inode);
list_for_each_entry(capsnap, &ci->i_cap_snaps, ci_item) {
dout(" cap_snap %p snapc %p has %d dirty pagesn", capsnap,
capsnap->context, capsnap->dirty_pages);
}其中ceph_cap_snap结构体定义如下:
/*
* Snapped cap state that is pending flush to mds. When a snapshot occurs,
* we first complete any in-process sync writes and writeback any dirty
* data before flushing the snapped state (tracked here) back to the MDS.
*/
struct ceph_cap_snap {
atomic_t nref;
//这个就是链表头
struct list_head ci_item;
//不关注的成员变量
......
bool need_flush;
};ceph_inode_info结构体成员定义如下
/*
* Ceph inode.
*/
struct ceph_inode_info {
struct ceph_vino i_vino; /* ceph ino + snap */
...不关注的代码...
struct list_head i_cap_snaps; /* snapped state pending flush to mds */
...不关注的代码...
struct inode vfs_inode; /* at end */
};再看下刚才代码:
那么这个遍历的意思就是,从ci结构体中的i_cap_snaps的链表头地址开始,遍历挂接在这个链表上的所有结构体,这个结构体是ceph_cap_snap类型的,这个结构体中挂接在链表上的节点名字叫做ci_item,每遍历一次,将这个链表上的结构体地址赋值给capsnap这个指针,然后打印这个指针指向的结构体中成员变量的值,到这个链表最后一个结束,不遍历链表头。
list_for_each_entry(capsnap, &ci->i_cap_snaps, ci_item) {
//打印
dout(" cap_snap %p snapc %p has %d dirty pagesn", capsnap,
capsnap->context, capsnap->dirty_pages);
}最后
以上就是迷人狗最近收集整理的关于list_for_each_entry通俗解释宏定义的功能:的全部内容,更多相关list_for_each_entry通俗解释宏定义内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复