我是靠谱客的博主 哭泣帆布鞋,这篇文章主要介绍python爬取淘宝页面cookie requests库和re正则表达式库 (最新) 中国大学MOOC嵩天Python网络爬虫与信息提取cookie爬取淘宝商品信息时必须获取cookie,因为淘宝有反爬虫机制!!!,现在分享给大家,希望可以做个参考。
爬取淘宝商品信息时必须获取cookie,因为淘宝有反爬虫机制!!!
**淘宝爬虫机制查看:**https://www.taobao.com/robots.txt

我们需要headers标签修改我们的cookie,让爬虫像人一样搜索页面
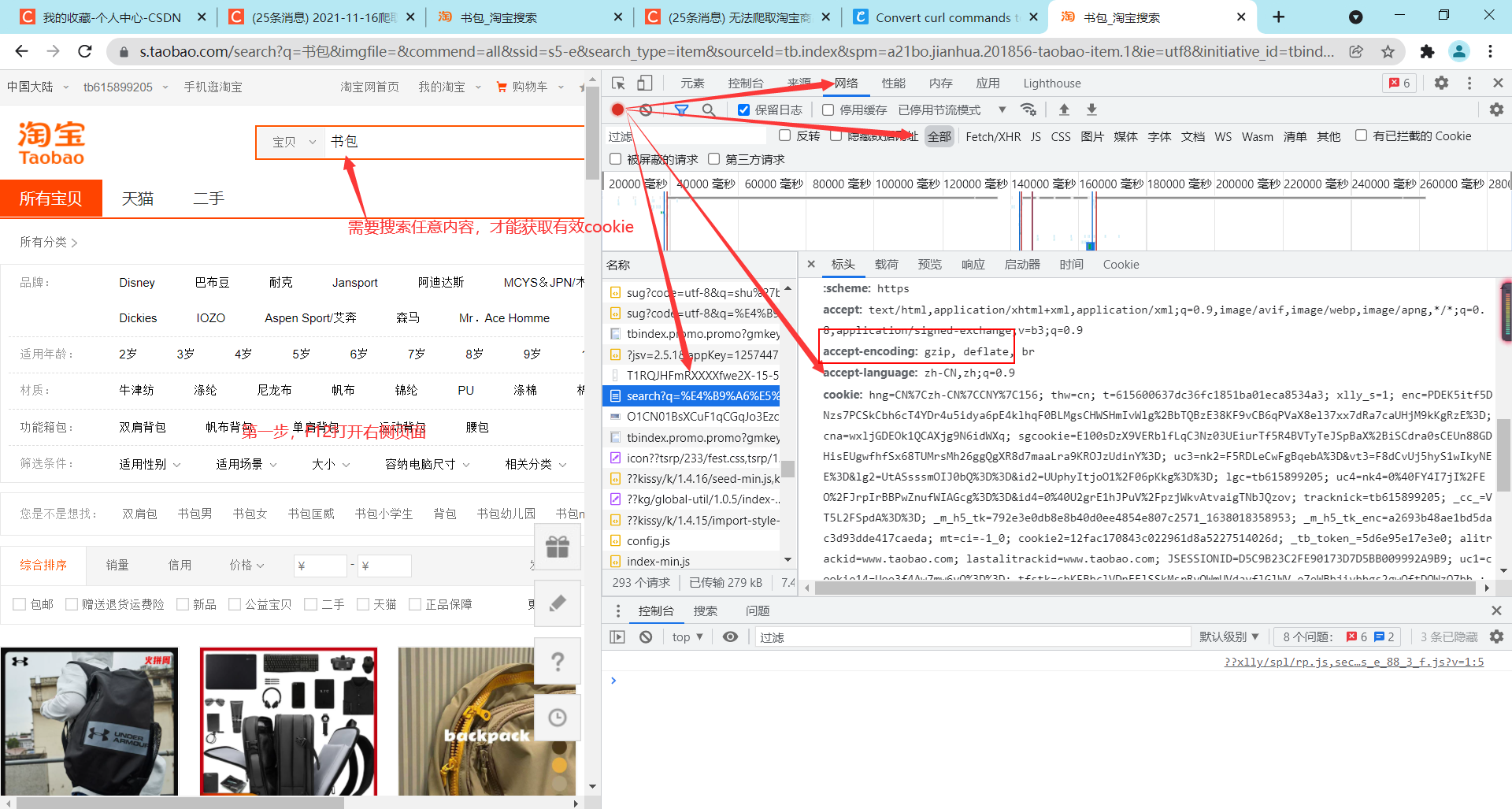
此处以爬取书包信息为例
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'"view_price":"[d.]*"', html)
tlt = re.findall(r'"raw_title":".*?"', html)
for i in range(len(plt)):
price = eval(plt[i].split(":")[1])
title = eval(tlt[i].split(":")[1])
ilt.append([price, title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}t{:8}t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
print("")
def main():
goods = "书包"
depth = 2
start_url = "https://s.taobao.com/search?q=" + goods
infoList = []
for i in range(depth):
try:
url = start_url + "&s=" + str(44 * i)
headers = {
'user-agent': 'Mozilla/5.0',
# cookie必须为搜索页面的cookie,eg:搜索书包(任意对象都可以)后打开的页面cookie
#下面第一个为获取的错误cookie
#"cookie" : "hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; t=615600637dc36fc1851ba01eca8534a3; xlly_s=1; enc=PDEK5itf5DNzs7PCSkCbh6cT4YDr4u5idya6pE4klhqF0BLMgsCHWSHmIvWlg%2BbTQBzE38KF9vCB6qPVaX8el37xx7dRa7caUHjM9kKgRzE%3D; cna=wxljGDEOk1QCAXjg9N6idWXq; sgcookie=E100sDzX9VERblfLqC3Nz03UEiurTf5R4BVTyTeJSpBaX%2BiSCdra0sCEUn88GDHisEUgwfhfSx68TUMrsMh26ggQgXR8d7maaLra9KROJzUdinY%3D; uc3=nk2=F5RDLeCwFgBqebA%3D&vt3=F8dCvUj5hyS1wIkyNEE%3D&lg2=UtASsssmOIJ0bQ%3D%3D&id2=UUphyItjoO1%2F06pKkg%3D%3D; lgc=tb615899205; uc4=nk4=0%40FY4I7jI%2FEO%2FJrpIrBBPwZnufWIAGcg%3D%3D&id4=0%40U2grE1hJPuV%2FpzjWkvAtvaigTNbJQzov; tracknick=tb615899205; _cc_=VT5L2FSpdA%3D%3D; _m_h5_tk=792e3e0db8e8b40d0ee4854e807c2571_1638018358953; _m_h5_tk_enc=a2693b48ae1bd5dac3d93dde417caeda; mt=ci=-1_0; cookie2=12fac170843c022961d8a5227514026d; _tb_token_=5d6e95e17e3e0; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; JSESSIONID=BF58315189D98C826FF6829A2758D8C4; uc1=cookie14=Uoe3f4Aw7mtHFw%3D%3D; tfstk=cEHdBdT9iFYnHIrt0XdiF8nyVs0RakSLrMaRehaspeClunXRFsvonxQxqBZzuyKO.; l=eBSdHAnqOvxQwm-8BOfZhurza77TMIRfguPzaNbMiOCP_a1W5Y9fW6IVsNYXCnGVHsq9y3uQQyaYBmLF-yIqJxpswAaZk_DmndC..; isg=BCcnBcJECpxshrBK_3iN5F_itlvxrPuOFeclXfmUmrbd6EaqCH1U3jyuCuj2ANMG"
'cookie' : 'hng=CN|zh-CN|CNY|156; thw=cn; t=615600637dc36fc1851ba01eca8534a3; xlly_s=1; enc=PDEK5itf5DNzs7PCSkCbh6cT4YDr4u5idya6pE4klhqF0BLMgsCHWSHmIvWlg+bTQBzE38KF9vCB6qPVaX8el37xx7dRa7caUHjM9kKgRzE=; cna=wxljGDEOk1QCAXjg9N6idWXq; sgcookie=E100sDzX9VERblfLqC3Nz03UEiurTf5R4BVTyTeJSpBaX+iSCdra0sCEUn88GDHisEUgwfhfSx68TUMrsMh26ggQgXR8d7maaLra9KROJzUdinY=; uc3=nk2=F5RDLeCwFgBqebA=&vt3=F8dCvUj5hyS1wIkyNEE=&lg2=UtASsssmOIJ0bQ==&id2=UUphyItjoO1/06pKkg==; lgc=tb615899205; uc4=nk4=0@FY4I7jI/EO/JrpIrBBPwZnufWIAGcg==&id4=0@U2grE1hJPuV/pzjWkvAtvaigTNbJQzov; tracknick=tb615899205; _cc_=VT5L2FSpdA==; _m_h5_tk=792e3e0db8e8b40d0ee4854e807c2571_1638018358953; _m_h5_tk_enc=a2693b48ae1bd5dac3d93dde417caeda; mt=ci=-1_0; cookie2=12fac170843c022961d8a5227514026d; _tb_token_=5d6e95e17e3e0; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; JSESSIONID=D5C9B23C2FE90173D7D5BB009992A9B9; uc1=cookie14=Uoe3f4Aw7mw6vQ==; tfstk=chKFBbclVDnEElSSkMsrRvQWmUVdavflGlWV-e7eWBbjivbhgs2gwOftDOWzQ7bh.; l=eBSdHAnqOvxQwQNjBOfZnurza77TtIRfguPzaNbMiOCPO11w5yRNW6IVsVTeCnGVHs0vP3uQQyaYBkLF7ydqJxpswAaZk_DmndC..; isg=BLa20_JEy6NVP4GdRrNsi_YpB-y41_oRDHx0KiCfxxk0Y1f9gGbZIUAVez8PS_Ip'
}
html = requests.get(url, headers=headers)
parsePage(infoList, html.text)
except:
continue
printGoodsList(infoList)
main()
结果

最后
以上就是哭泣帆布鞋最近收集整理的关于python爬取淘宝页面cookie requests库和re正则表达式库 (最新) 中国大学MOOC嵩天Python网络爬虫与信息提取cookie爬取淘宝商品信息时必须获取cookie,因为淘宝有反爬虫机制!!!的全部内容,更多相关python爬取淘宝页面cookie内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复