基础知识
Executors创建线程池
Java中创建线程池很简单,只需要调用Executors中相应的便捷方法即可,比如Executors.newFixedThreadPool(int nThreads),但是便捷不仅隐藏了复杂性,也为我们埋下了潜在的隐患(OOM,线程耗尽)。
Executors创建线程池便捷方法列表:
方法名
功能
newFixedThreadPool(int nThreads)
创建固定大小的线程池
newSingleThreadExecutor()
创建只有一个线程的线程池
newCachedThreadPool()
创建一个不限线程数上限的线程池,任何提交的任务都将立即执行
小程序使用这些快捷方法没什么问题,对于服务端需要长期运行的程序,创建线程池应该直接使用ThreadPoolExecutor的构造方法。没错,上述Executors方法创建的线程池就是ThreadPoolExecutor。
ThreadPoolExecutor构造方法
Executors中创建线程池的快捷方法,实际上是调用了ThreadPoolExecutor的构造方法(定时任务使用的是ScheduledThreadPoolExecutor),该类构造方法参数列表如下:
// Java线程池的完整构造函数
public ThreadPoolExecutor(
int corePoolSize, // 线程池长期维持的线程数,即使线程处于Idle状态,也不会回收。
int maximumPoolSize, // 线程数的上限
long keepAliveTime, TimeUnit unit, // 超过corePoolSize的线程的idle时长,
// 超过这个时间,多余的线程会被回收。
BlockingQueue<Runnable> workQueue, // 任务的排队队列
ThreadFactory threadFactory, // 新线程的产生方式
RejectedExecutionHandler handler) // 拒绝策略
竟然有7个参数,很无奈,构造一个线程池确实需要这么多参数。这些参数中,比较容易引起问题的有corePoolSize,maximumPoolSize,workQueue以及handler:
corePoolSize和maximumPoolSize设置不当会影响效率,甚至耗尽线程;workQueue设置不当容易导致OOM;handler设置不当会导致提交任务时抛出异常。
正确的参数设置方式会在下文给出。
线程池的工作顺序
If fewer than corePoolSize threads are running, the Executor always prefers adding a new thread rather than queuing.
If corePoolSize or more threads are running, the Executor always prefers queuing a request rather than adding a new thread.
If a request cannot be queued, a new thread is created unless this would exceed maximumPoolSize, in which case, the task will be rejected.
corePoolSize -> 任务队列 -> maximumPoolSize -> 拒绝策略
Runnable和Callable
可以向线程池提交的任务有两种:Runnable和Callable,二者的区别如下:
- 方法签名不同,
void Runnable.run(),V Callable.call() throws Exception - 是否允许有返回值,
Callable允许有返回值 - 是否允许抛出异常,
Callable允许抛出异常。
Callable是JDK1.5时加入的接口,作为Runnable的一种补充,允许有返回值,允许抛出异常。
三种提交任务的方式:
提交方式
是否关心返回结果
Future<T> submit(Callable<T> task)
是
void execute(Runnable command)
否
Future<?> submit(Runnable task)
否,虽然返回Future,但是其get()方法总是返回null
如何正确使用线程池
避免使用无界队列
不要使用Executors.newXXXThreadPool()快捷方法创建线程池,因为这种方式会使用无界的任务队列,为避免OOM,我们应该使用ThreadPoolExecutor的构造方法手动指定队列的最大长度:
ExecutorService executorService = new ThreadPoolExecutor(2, 2,
0, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(512), // 使用有界队列,避免OOM
new ThreadPoolExecutor.DiscardPolicy());
明确拒绝任务时的行为
任务队列总有占满的时候,这是再submit()提交新的任务会怎么样呢?RejectedExecutionHandler接口为我们提供了控制方式,接口定义如下:
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
线程池给我们提供了几种常见的拒绝策略:
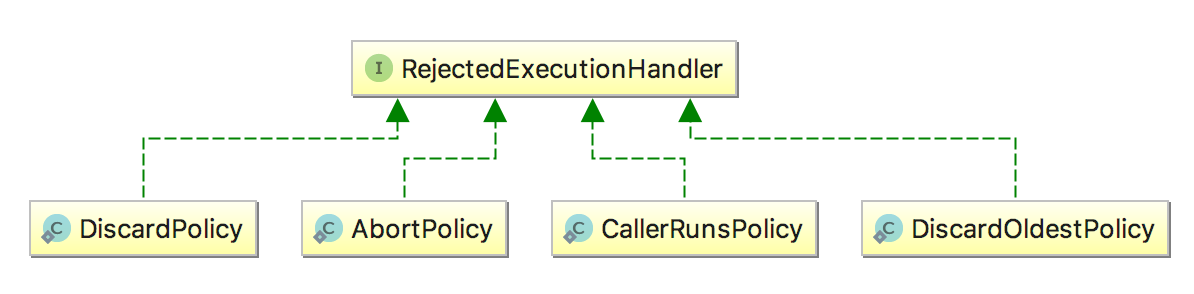
拒绝策略
拒绝行为
AbortPolicy
抛出RejectedExecutionException
DiscardPolicy
什么也不做,直接忽略
DiscardOldestPolicy
丢弃执行队列中最老的任务,尝试为当前提交的任务腾出位置
CallerRunsPolicy
直接由提交任务者执行这个任务
线程池默认的拒绝行为是AbortPolicy,也就是抛出RejectedExecutionHandler异常,该异常是非受检异常,很容易忘记捕获。如果不关心任务被拒绝的事件,可以将拒绝策略设置成DiscardPolicy,这样多余的任务会悄悄的被忽略。
ExecutorService executorService = new ThreadPoolExecutor(2, 2,
0, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(512),
new ThreadPoolExecutor.DiscardPolicy());// 指定拒绝策略
获取处理结果和异常
线程池的处理结果、以及处理过程中的异常都被包装到Future中,并在调用Future.get()方法时获取,执行过程中的异常会被包装成ExecutionException,submit()方法本身不会传递结果和任务执行过程中的异常。获取执行结果的代码可以这样写:
ExecutorService executorService = Executors.newFixedThreadPool(4);
Future<Object> future = executorService.submit(new Callable<Object>() {
@Override
public Object call() throws Exception {
throw new RuntimeException("exception in call~");// 该异常会在调用Future.get()时传递给调用者
}
});
try {
Object result = future.get();
} catch (InterruptedException e) {
// interrupt
} catch (ExecutionException e) {
// exception in Callable.call()
e.printStackTrace();
}
上述代码输出类似如下:

线程池的常用场景
正确构造线程池
int poolSize = Runtime.getRuntime().availableProcessors() * 2;
BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(512);
RejectedExecutionHandler policy = new ThreadPoolExecutor.DiscardPolicy();
executorService = new ThreadPoolExecutor(poolSize, poolSize,
0, TimeUnit.SECONDS,
queue,
policy);
获取单个结果
过submit()向线程池提交任务后会返回一个Future,调用V Future.get()方法能够阻塞等待执行结果,V get(long timeout, TimeUnit unit)方法可以指定等待的超时时间。
获取多个结果
如果向线程池提交了多个任务,要获取这些任务的执行结果,可以依次调用Future.get()获得。但对于这种场景,我们更应该使用ExecutorCompletionService,该类的take()方法总是阻塞等待某一个任务完成,然后返回该任务的Future对象。向CompletionService批量提交任务后,只需调用相同次数的CompletionService.take()方法,就能获取所有任务的执行结果,获取顺序是任意的,取决于任务的完成顺序:
void solve(Executor executor, Collection<Callable<Result>> solvers)
throws InterruptedException, ExecutionException {
CompletionService<Result> ecs = new ExecutorCompletionService<Result>(executor);// 构造器
for (Callable<Result> s : solvers)// 提交所有任务
ecs.submit(s);
int n = solvers.size();
for (int i = 0; i < n; ++i) {// 获取每一个完成的任务
Result r = ecs.take().get();
if (r != null)
use(r);
}
}
单个任务的超时时间
V Future.get(long timeout, TimeUnit unit)方法可以指定等待的超时时间,超时未完成会抛出TimeoutException。
多个任务的超时时间
等待多个任务完成,并设置最大等待时间,可以通过CountDownLatch完成:
public void testLatch(ExecutorService executorService, List<Runnable> tasks)
throws InterruptedException{
CountDownLatch latch = new CountDownLatch(tasks.size());
for(Runnable r : tasks){
executorService.submit(new Runnable() {
@Override
public void run() {
try{
r.run();
}finally {
latch.countDown();// countDown
}
}
});
}
latch.await(10, TimeUnit.SECONDS); // 指定超时时间
}
线程池和装修公司
以运营一家装修公司做个比喻。公司在办公地点等待客户来提交装修请求;公司有固定数量的正式工以维持运转;旺季业务较多时,新来的客户请求会被排期,比如接单后告诉用户一个月后才能开始装修;当排期太多时,为避免用户等太久,公司会通过某些渠道(比如人才市场、熟人介绍等)雇佣一些临时工(注意,招聘临时工是在排期排满之后);如果临时工也忙不过来,公司将决定不再接收新的客户,直接拒单。
线程池就是程序中的“装修公司”,代劳各种脏活累活。上面的过程对应到线程池上:
// Java线程池的完整构造函数
public ThreadPoolExecutor(
int corePoolSize, // 正式工数量
int maximumPoolSize, // 工人数量上限,包括正式工和临时工
long keepAliveTime, TimeUnit unit, // 临时工游手好闲的最长时间,超过这个时间将被解雇
BlockingQueue<Runnable> workQueue, // 排期队列
ThreadFactory threadFactory, // 招人渠道
RejectedExecutionHandler handler) // 拒单方式
总结
Executors为我们提供了构造线程池的便捷方法,对于服务器程序我们应该杜绝使用这些便捷方法,而是直接使用线程池ThreadPoolExecutor的构造方法,避免无界队列可能导致的OOM以及线程个数限制不当导致的线程数耗尽等问题。ExecutorCompletionService提供了等待所有任务执行结束的有效方式,如果要设置等待的超时时间,则可以通过CountDownLatch完成。
Java 五种线程池详解
在应用开发中,通常有这样的需求,就是并发下载文件操作,比如百度网盘下载文件、腾讯视频下载视频等,都可以同时下载好几个文件,这就是并发下载。并发下载处理肯定是多线程操作,而大量的创建线程,势必会影响程序的性能,导致卡顿等问题。所以呢,Java 中给我们提供了线程池来管理线程。
首先,我们来看看线程池是什么?顾名思义,好比一个存放线程的池子,我们可以联想水池。线程池意味着可以储存线程,并让池内的线程得以复用,如果池内的某一个线程执行完了,并不会直接摧毁,它有生命,可以存活一些时间,待到下一个任务来时,它会复用这个在等待中线程,避免了再去创建线程的额外开销。
百度对线程池的简介:
【线程池(英语:thread pool):一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。 例如,线程数一般取cpu数量+2比较合适,线程数过多会导致额外的线程切换开销。】
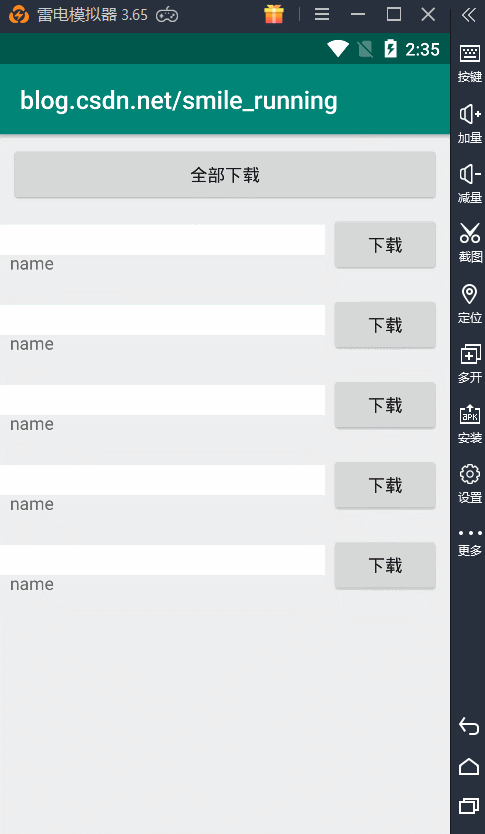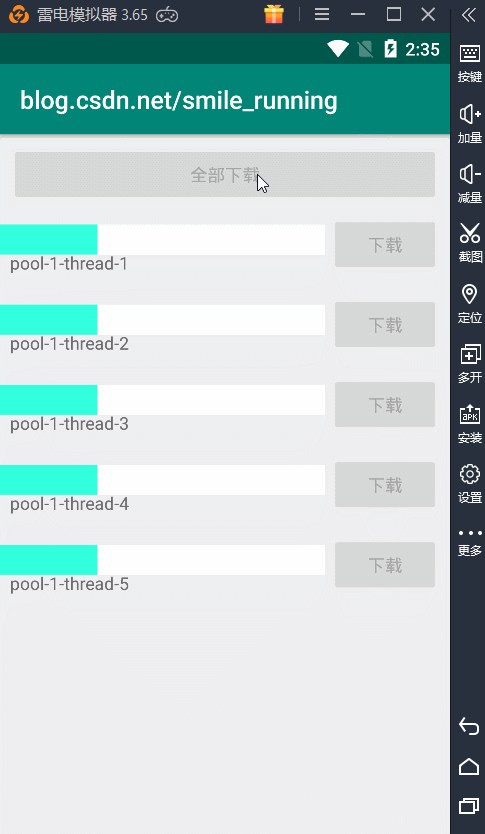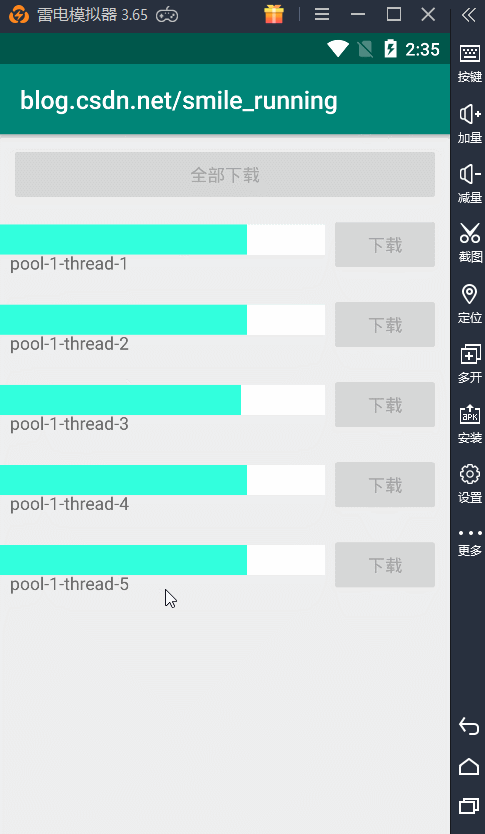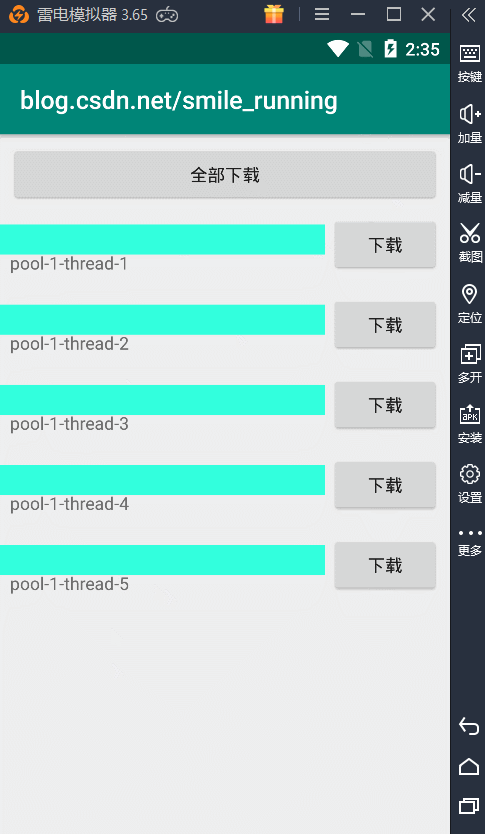
线程池的概念与作用就介绍完了,下面就是线程池的运用了,我们来看这样的一个例子,模拟网络下载的功能,开启多任务下载操作,其中每条下载都开辟新线程来执行。
效果图:
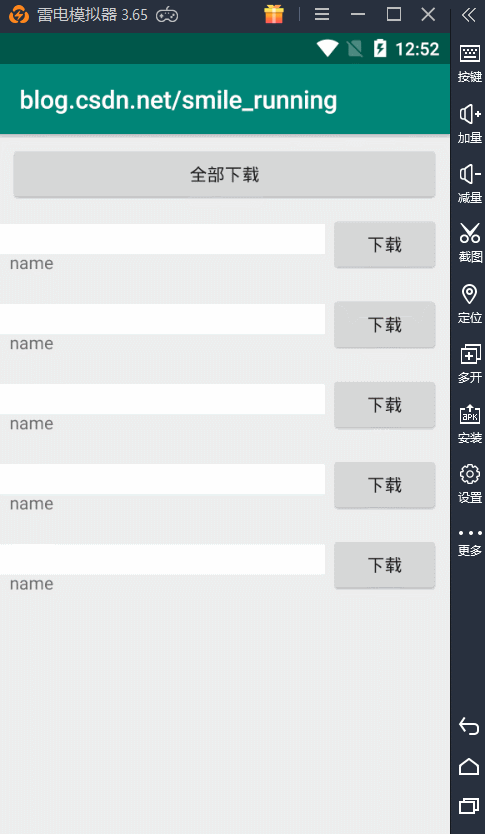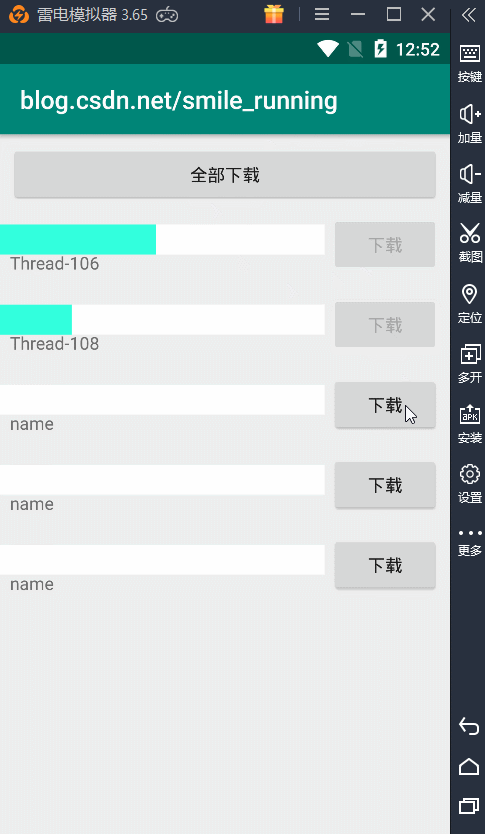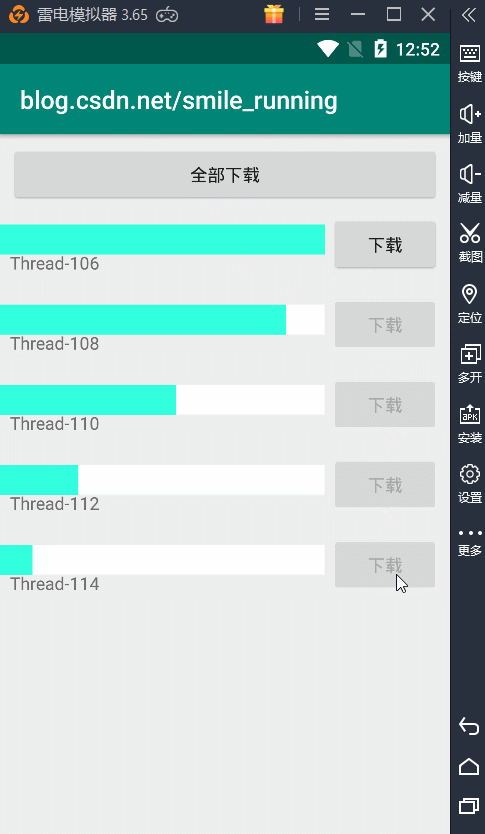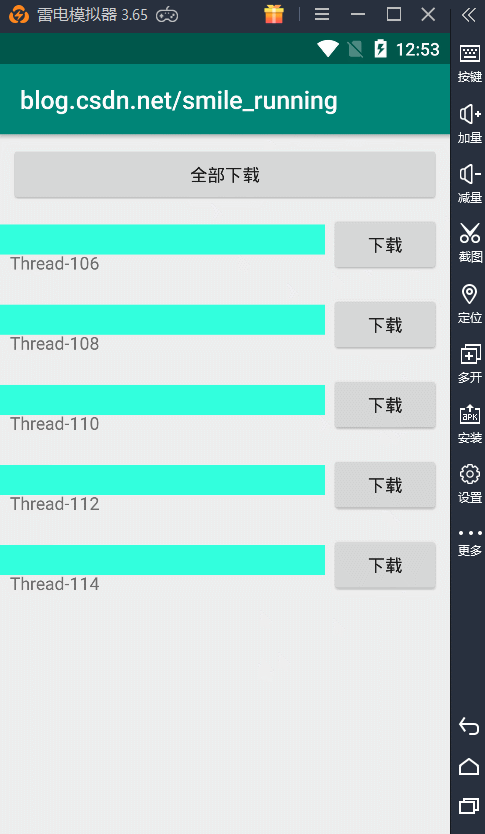
可以看到就是这样效果,这里的每次点击下载按钮,都会开启一个子线程来更新进度条操作。注意了:这里我们看到的 name 就是线程的名字。可以观察到,5个下载任务所用的线程都是不同的,所以它们的线程名都不一样。
也就是说,我们每个任务开辟的都是一个新的线程,假如我们下载任务量非常庞大时,那开辟的线程将不可控制,先不说性能问题,如果出现了线程安全问题或者是线程的调度,处理起来都是非常困难的。所以这种情况下,非常的有必要引入我们的线程池来管理这些线程,刚刚我们介绍了线程池的优点,现在让我们具体的实现一下,才能体会它到底有那些优势。
首先,我们的线程池类型一共有 4 种,分别是 newSingleThreadPool、newFixedThreadPool、newCachedThreadPool、newScheduledThreadPool 四种,这是在 JDK1.8 版本以前了,在JDK1.8 版本又加入了一种:newWorkStealingPool,所以现在一共是 5 种。
1、线程池的创建过程
通过这几种线程池的命名,我们大致可以猜测出来它的用意,当然,还是必须要实践一下。对线程池的创建一般都是这样的步骤:
-
//创建单核心的线程池 -
ExecutorService executorService = Executors.newSingleThreadExecutor(); -
//创建固定核心数的线程池,这里核心数 = 2 -
ExecutorService executorService = Executors.newFixedThreadPool(2); -
//创建一个按照计划规定执行的线程池,这里核心数 = 2 -
ExecutorService executorService = Executors.newScheduledThreadPool(2); -
//创建一个自动增长的线程池 -
ExecutorService executorService = Executors.newCachedThreadPool(); -
//创建一个具有抢占式操作的线程池 -
ExecutorService executorService = Executors.newWorkStealingPool();
我们只需要这样调用就可成功的创建适用于我们的线程池,不过从上面看不出上面东西来,我们要进入线程池创建的构造器,代码如下:
-
/** -
* Creates a new {@code ThreadPoolExecutor} with the given initial -
* parameters and default thread factory and rejected execution handler. -
* It may be more convenient to use one of the {@link Executors} factory -
* methods instead of this general purpose constructor. -
* -
* @param corePoolSize the number of threads to keep in the pool, even -
* if they are idle, unless {@code allowCoreThreadTimeOut} is set -
* @param maximumPoolSize the maximum number of threads to allow in the -
* pool -
* @param keepAliveTime when the number of threads is greater than -
* the core, this is the maximum time that excess idle threads -
* will wait for new tasks before terminating. -
* @param unit the time unit for the {@code keepAliveTime} argument -
* @param workQueue the queue to use for holding tasks before they are -
* executed. This queue will hold only the {@code Runnable} -
* tasks submitted by the {@code execute} method. -
* @throws IllegalArgumentException if one of the following holds:<br> -
* {@code corePoolSize < 0}<br> -
* {@code keepAliveTime < 0}<br> -
* {@code maximumPoolSize <= 0}<br> -
* {@code maximumPoolSize < corePoolSize} -
* @throws NullPointerException if {@code workQueue} is null -
*/ -
public ThreadPoolExecutor(int corePoolSize, -
int maximumPoolSize, -
long keepAliveTime, -
TimeUnit unit, -
BlockingQueue<Runnable> workQueue) { -
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, -
Executors.defaultThreadFactory(), defaultHandler); -
}
当然,上面的注释都对参数进行了介绍,我们用自己的语言进行归纳一下:
- corePoolSize: 表示线程池核心线程数,当初始化线程池时,会创建核心线程进入等待状态,即使它是空闲的,核心线程也不会被摧毁,从而降低了任务一来时要创建新线程的时间和性能开销。
- maximumPoolSize: 表示最大线程数,意味着核心线程数都被用完了,那只能重新创建新的线程来执行任务,但是前提是不能超过最大线程数量,否则该任务只能进入阻塞队列进行排队等候,直到有线程空闲了,才能继续执行任务。
- keepAliveTime: 表示线程存活时间,除了核心线程外,那些被新创建出来的线程可以存活多久。意味着,这些新的线程一但完成任务,而后面都是空闲状态时,就会在一定时间后被摧毁。
- unit: 存活时间单位,没什么好解释的,一看就懂。
- workQueue: 表示任务的阻塞队列,由于任务可能会有很多,而线程就那么几个,所以那么还未被执行的任务就进入队列中排队,队列我们知道是 FIFO 的,等到线程空闲了,就以这种方式取出任务。这个一般不需要我们去实现。
还有一个注意点就是它这里的规定,可能会抛出这样的异常情况。这下面写的很明白了,就不要再介绍了:
-
* @throws IllegalArgumentException if one of the following holds:<br> -
* {@code corePoolSize < 0 } -
* {@code keepAliveTime < 0 } -
* {@code maximumPoolSize <= 0 } -
* {@code maximumPoolSize < corePoolSize } -
* @throws NullPointerException if {@code workQueue} is null
好了,以上重点几个参数内容我们介绍完了,现在来看看几种线程池的比较和表现吧!
2、线程池的比较
**(1)newSingleThreadPool,**为单核心线程池,最大线程也只有一个,这里的时间为 0 意味着无限的生命,就不会被摧毁了。它的创建方式源码如下:
-
public static ExecutorService newSingleThreadExecutor() { -
return new FinalizableDelegatedExecutorService -
(new ThreadPoolExecutor(1, 1, -
0L, TimeUnit.MILLISECONDS, -
new LinkedBlockingQueue<Runnable>())); -
}
最形象的就是拿我们下载那个例子,为了便于测试,我当然添加了一个 全部下载的功能,newSingleThreadPool测试结果如下:
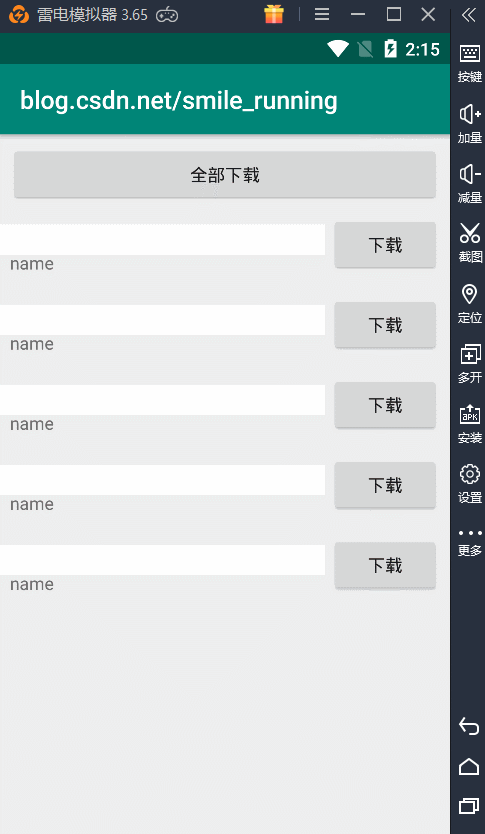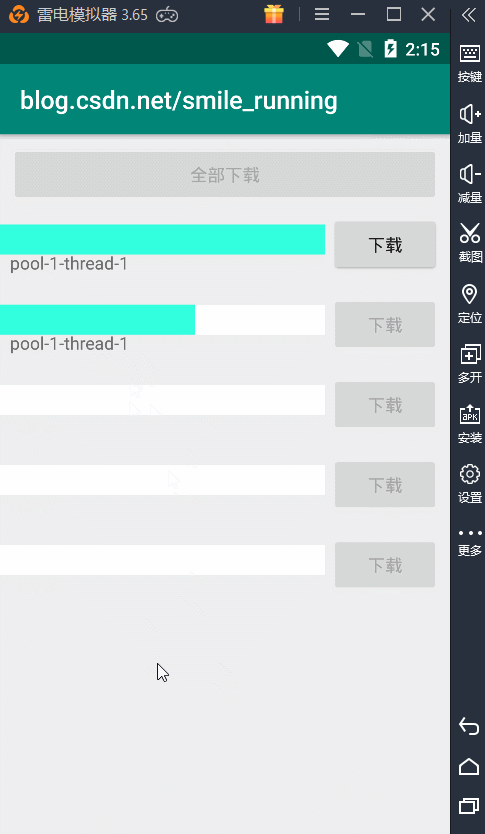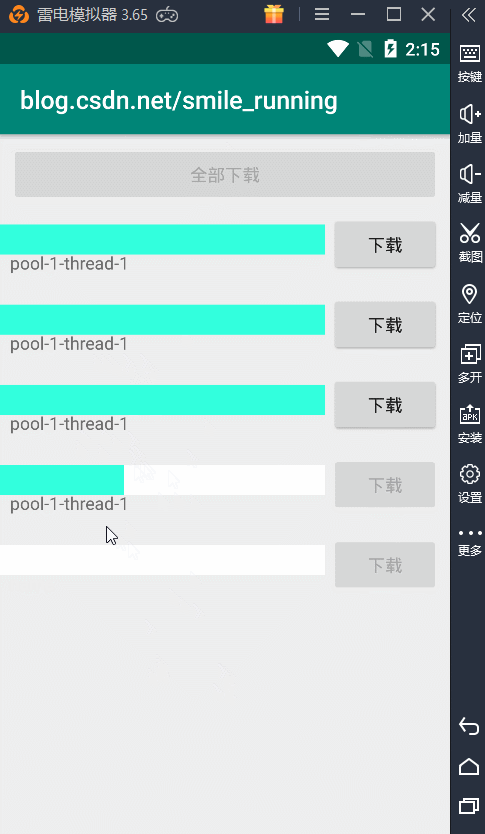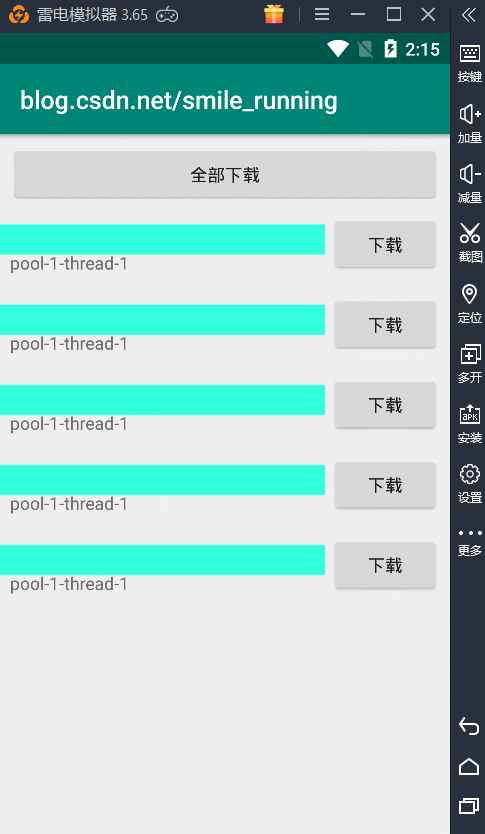
由于我们的线程池中使用的从始至终都是单个线程,所以这里的线程名字都是相同的,而且下载任务都是一个一个的来,直到有空闲线程时,才会继续执行任务,否则都是等待状态。
(2)newFixedThreadPool,我们需要传入一个固定的核心线程数,并且核心线程数等于最大线程数,而且它们的线程数存活时间都是无限的,看它的创建方式:
-
public static ExecutorService newFixedThreadPool(int nThreads) { -
return new ThreadPoolExecutor(nThreads, nThreads, -
0L, TimeUnit.MILLISECONDS, -
new LinkedBlockingQueue<Runnable>()); -
}
对比newSingleThreadPool,其实改变的也就是可以根据我们来自定义线程数的操作,比较相似。我们通过newFixedThreadPool(2)给它传入了 2 个核心线程数,看看下载效果如何:
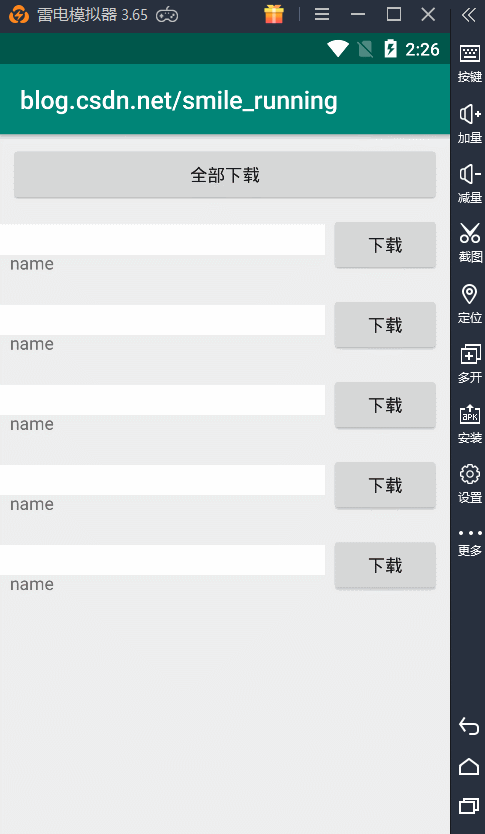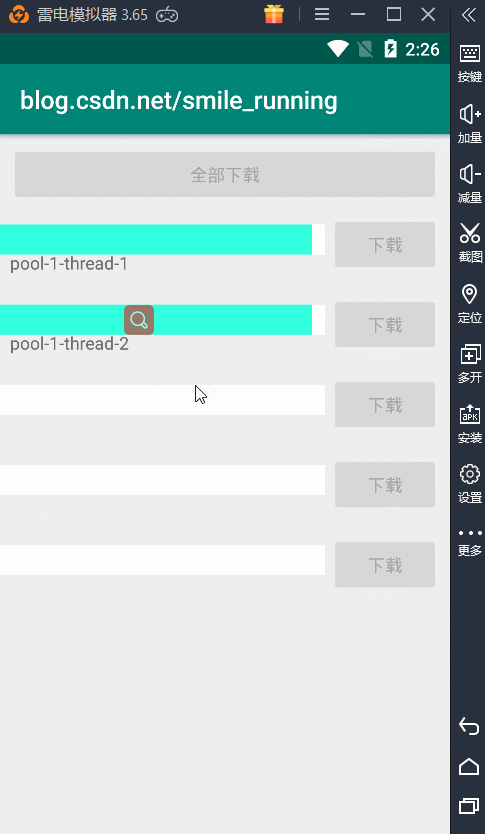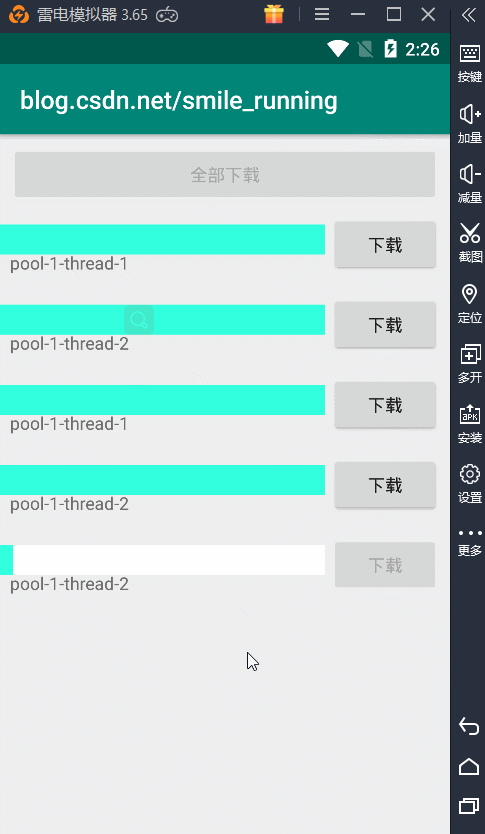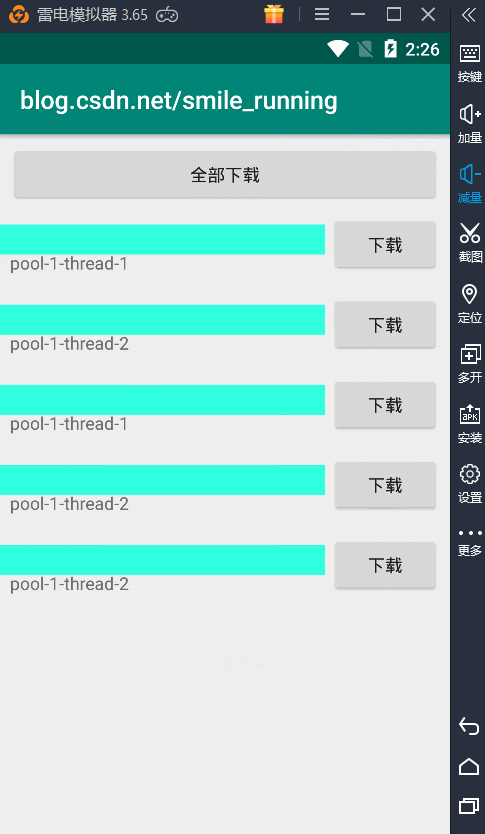
显然,它就可以做到并发的下载,我们两个下载任务可以同时进行,并且所用的线程始终都只有两个,因为它的最大线程数等于核心线程数,不会再去创建新的线程了,所以这个方式也可以,但最好还是运用下面一种线程池。
**(3)newCachedThreadPool,**可以进行缓存的线程池,意味着它的线程数是最大的,无限的。但是核心线程数为 0,这没关系。这里要考虑线程的摧毁,因为不能够无限的创建新的线程,所以在一定时间内要摧毁空闲的线程。看看创建的源码:
-
public static ExecutorService newCachedThreadPool() { -
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, -
60L, TimeUnit.SECONDS, -
new SynchronousQueue<Runnable>()); -
}
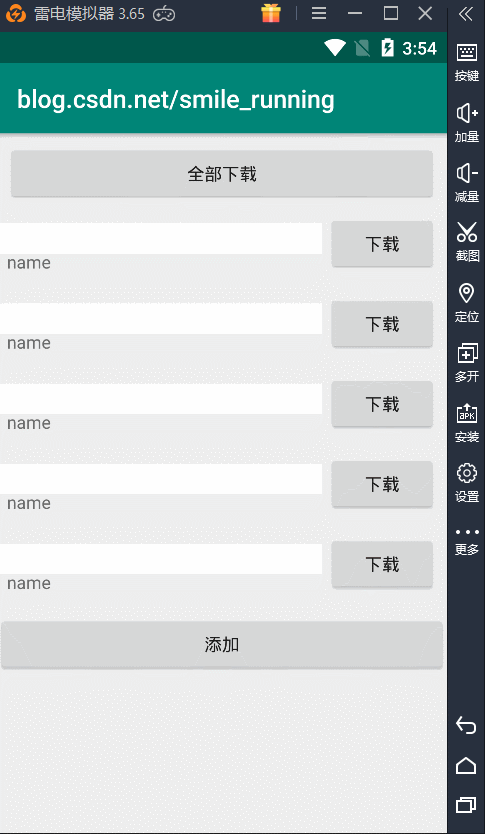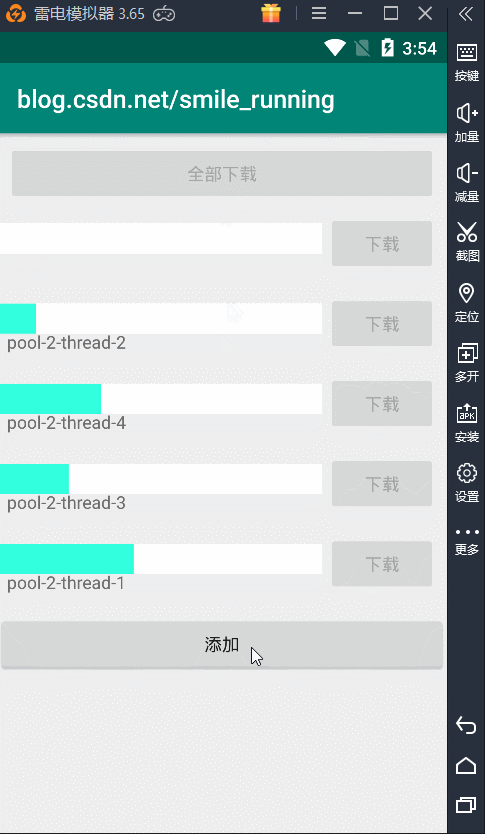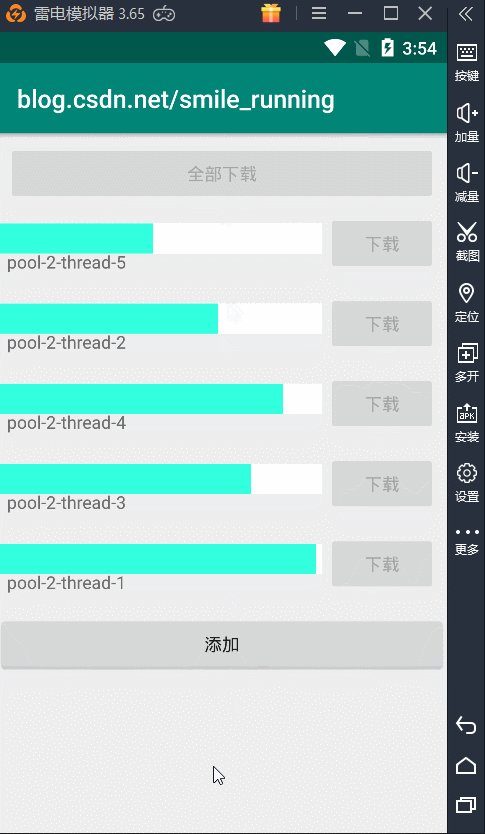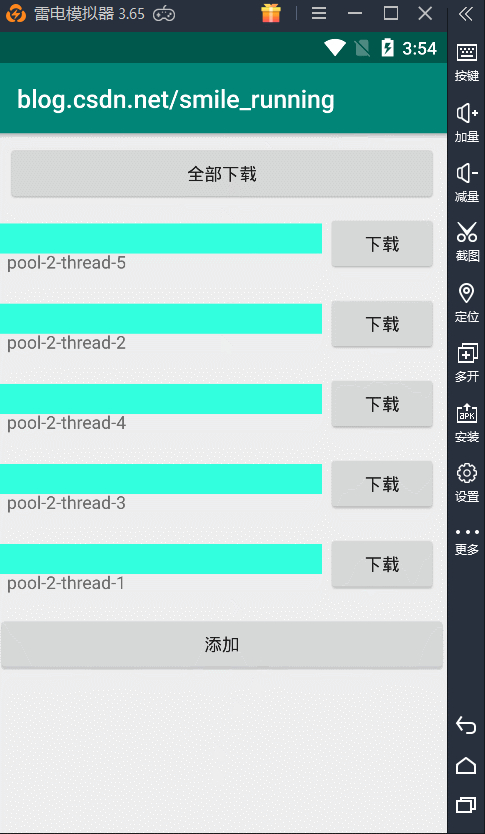
没有核心线程数,但是我们的最大线程数没有限制,所以一点全部开始下载,就会创建出 5 条新的线程同时执行任务,从上图的例子看出,每天线程都不一样。看不出这个线程池的效果,下面我们通过修改这个逻辑。
首先,我们点开始下载,只会下载前面三个,为了证明线程的复用效果,我这里又添加了一个按钮,在这个按钮中继续添加后面两个下载任务。
那么,当线程下载完毕时,空闲线程就会复用,结果显示如下,复用线程池的空闲线程:
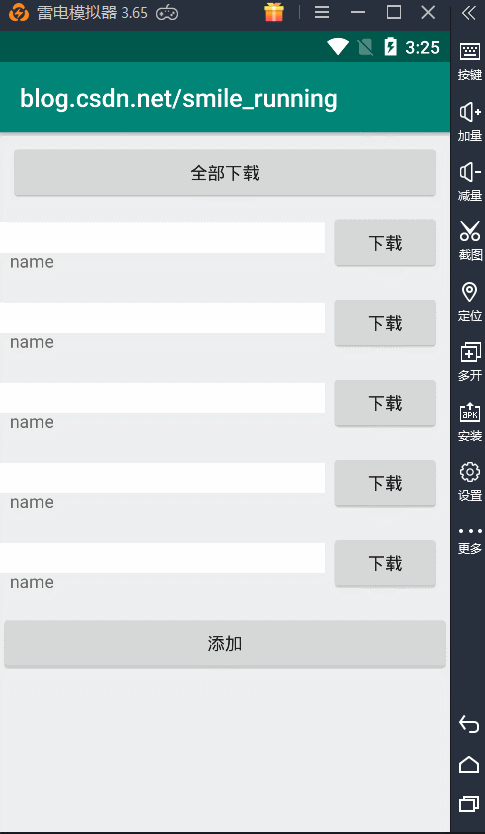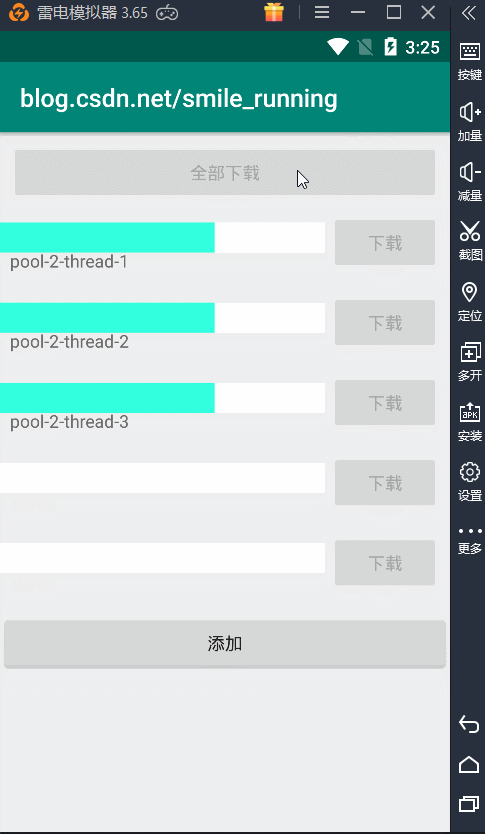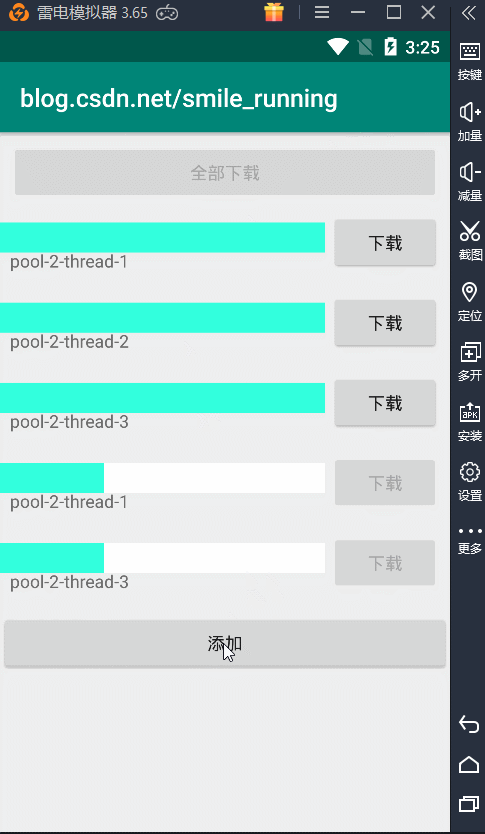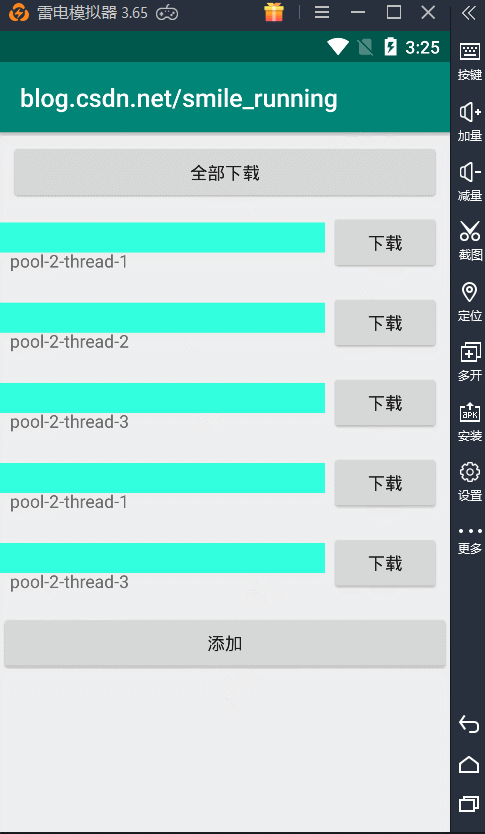
另一种情况,当线程池中没有空闲线程时,这时又加了新的任务,它就会创建出新的线程来执行任务,结果如下:
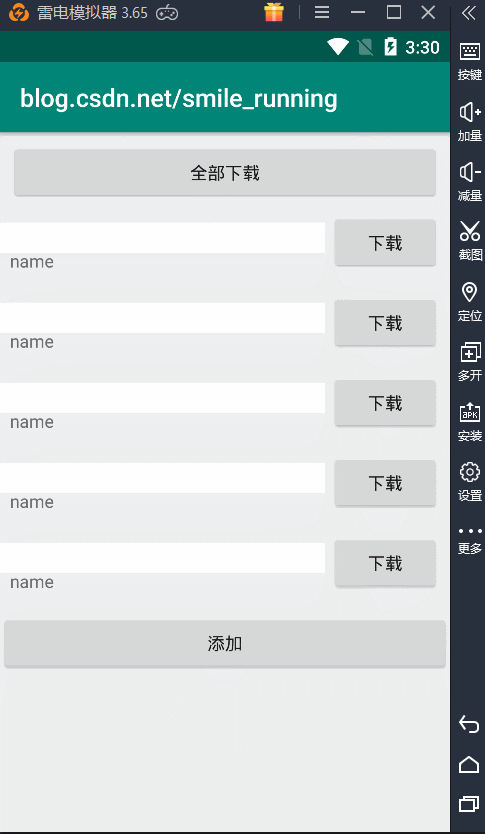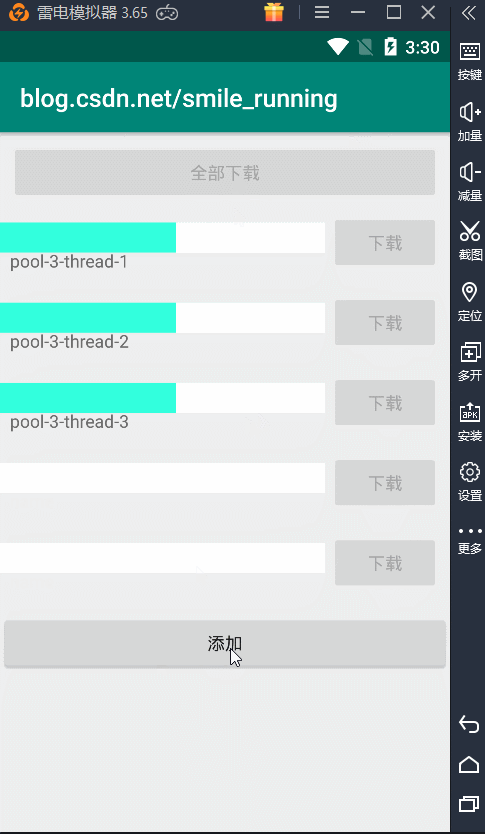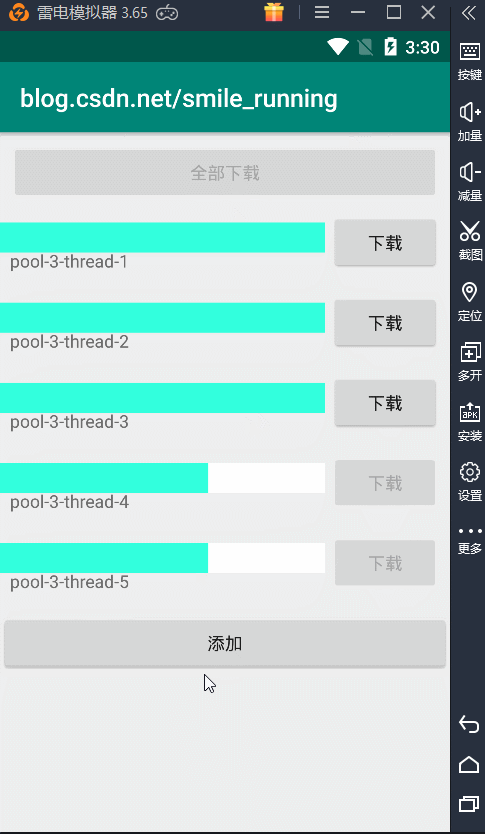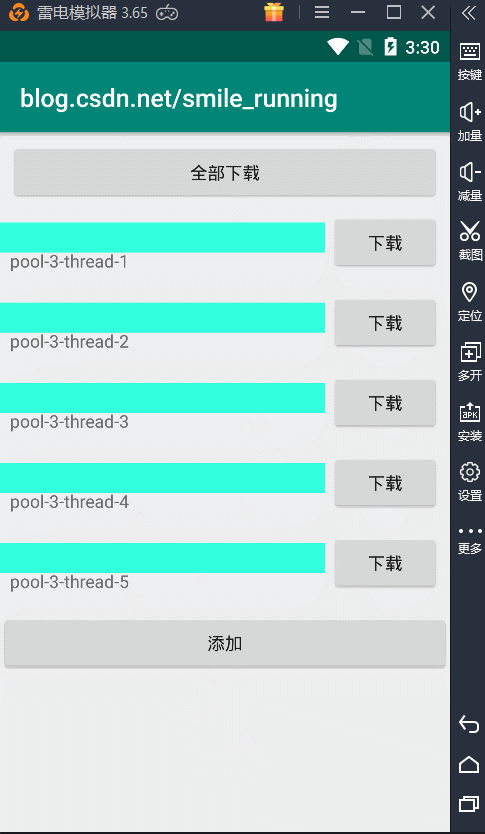
这下算是搞清楚这种线程池的作用了吧,但是由于这种线程池创建时初始化的都是无界的值,一个是最大线程数,一个是任务的阻塞队列,都没有设置它的界限,这可能会出现问题。
这里可以参考我的一篇文章:AsyncTask 源码分析,或者这个单利模式解读的文章,里面有提到如何创建自定义的线程池,参考的是AsyncTask的源码线程池创建代码。
**(4)newScheduledThreadPool,**这个表示的是有计划性的线程池,就是在给定的延迟之后运行,或周期性地执行。很好理解,大家应该用过 Timer 定时器类吧,这两个差不多的意思。它的构造函数如下:
-
public ScheduledThreadPoolExecutor(int corePoolSize) { -
super(corePoolSize, Integer.MAX_VALUE, -
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS, -
new DelayedWorkQueue()); -
}
内部有一个延时的阻塞队列来维护任务的进行,延时也就是在这里进行的。我们把创建newScheduledThreadPool的代码放出来,这样对比效果图的话,显得更加直观。
-
//参数2:延时的时长 -
scheduledExecutorService.schedule(th_all_1, 3000, TimeUnit.MILLISECONDS); -
scheduledExecutorService.schedule(th_all_2, 2000, TimeUnit.MILLISECONDS); -
scheduledExecutorService.schedule(th_all_3, 1000, TimeUnit.MILLISECONDS); -
scheduledExecutorService.schedule(th_all_4, 1500, TimeUnit.MILLISECONDS); -
scheduledExecutorService.schedule(th_all_5, 500, TimeUnit.MILLISECONDS);
这个线程池好像不是很常用,做个了解就好了。
(5)newWorkStealingPool,这个是 JDK1.8 版本加入的一种线程池,stealing 翻译为抢断、窃取的意思,它实现的一个线程池和上面4种都不一样,用的是ForkJoinPool类,构造函数代码如下:
-
/** -
* Creates a thread pool that maintains enough threads to support -
* the given parallelism level, and may use multiple queues to -
* reduce contention. The parallelism level corresponds to the -
* maximum number of threads actively engaged in, or available to -
* engage in, task processing. The actual number of threads may -
* grow and shrink dynamically. A work-stealing pool makes no -
* guarantees about the order in which submitted tasks are -
* executed. -
* -
* @param parallelism the targeted parallelism level -
* @return the newly created thread pool -
* @throws IllegalArgumentException if {@code parallelism <= 0} -
* @since 1.8 -
*/ -
public static ExecutorService newWorkStealingPool(int parallelism) { -
return new ForkJoinPool -
(parallelism, -
ForkJoinPool.defaultForkJoinWorkerThreadFactory, -
null, true); -
}
从上面代码的介绍,最明显的用意就是它是一个并行的线程池,参数中传入的是一个线程并发的数量,这里和之前就有很明显的区别,前面4种线程池都有核心线程数、最大线程数等等,而这就使用了一个并发线程数解决问题。从介绍中,还说明这个线程池不会保证任务的顺序执行,也就是 WorkStealing 的意思,抢占式的工作。
如下图,任务的执行是无序的,哪个线程抢到任务,就由它执行:
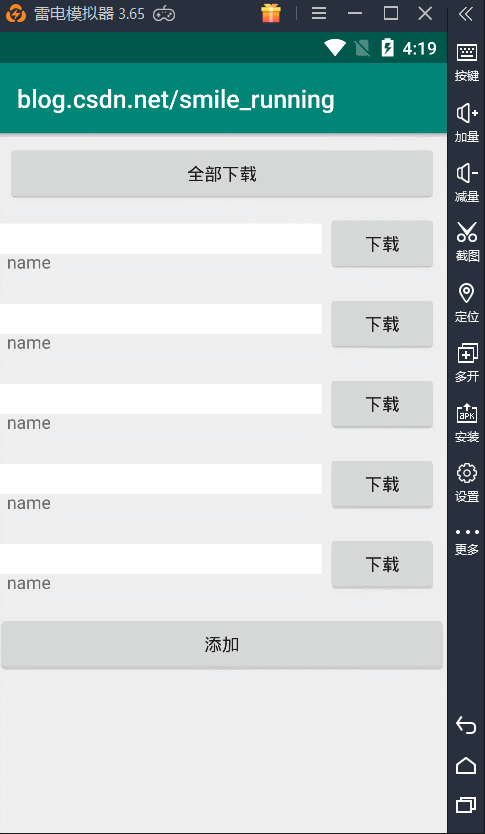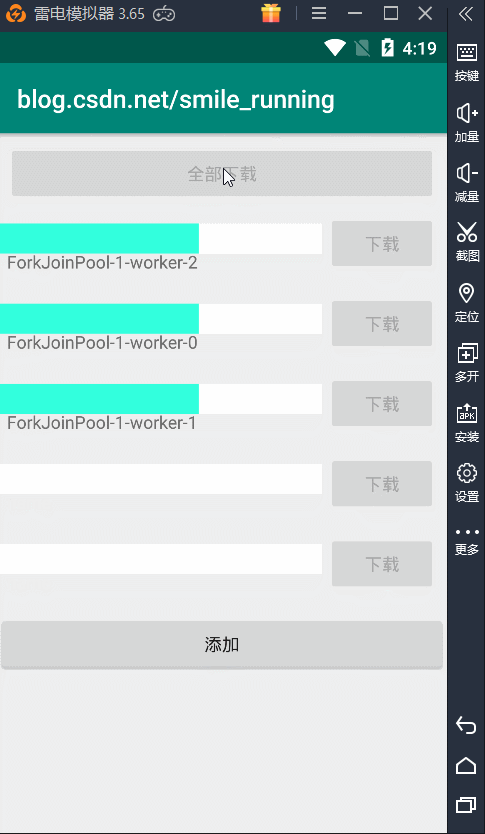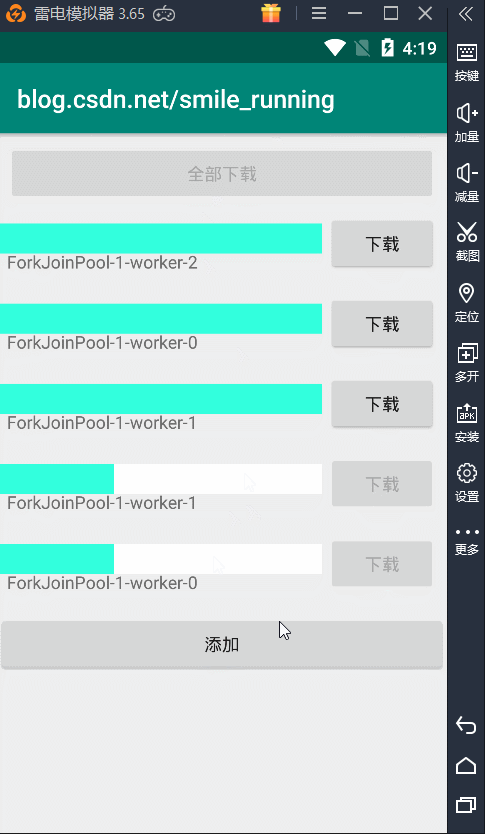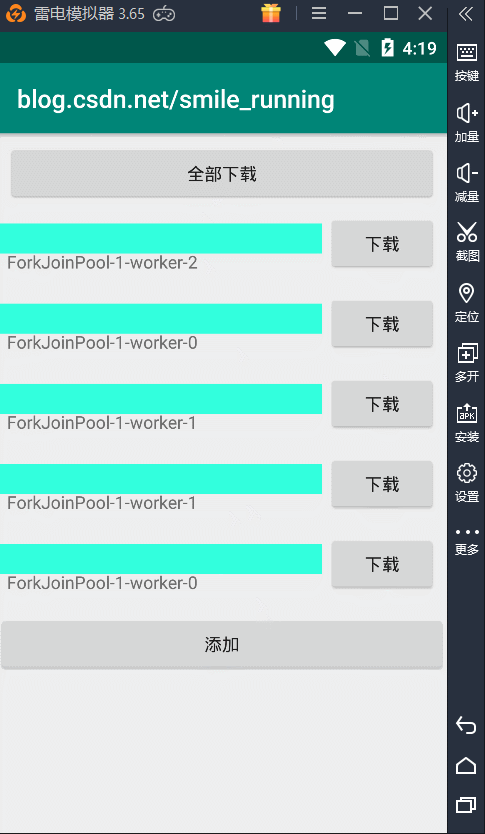
对比了以上 5 种线程池,我们看到每个线程池都有自己的特点,这也是为我们封装好的一些比较常用的线程池。当然,我建议你在使用**(3)可缓存的线程池**时,尽量的不要用默认的那个来创建,因为默认值都是无界的,可能会出现一些问题,这时我们可以参考源码中的线程池初始化参数的设置,可以尽可能的避免错误发生。
通过这个案例,我们把线程池学习了一遍,总结一下线程池在哪些地方用到,比如网络请求、下载、I/O操作等多线程场景,我们可以引入线程池,一个对性能有提升,另一个就是可以让管理线程变得更简单。
参考
ThreadPoolExecutor API Doc
转载自:
https://www.cnblogs.com/CarpenterLee/p/9558026.html
https://blog.csdn.net/smile_Running/article/details/91409942?utm_source=app
最后
以上就是冷酷航空最近收集整理的关于java线程池详解及五种线程池方法详解Java 五种线程池详解的全部内容,更多相关java线程池详解及五种线程池方法详解Java内容请搜索靠谱客的其他文章。








发表评论 取消回复