(时隔一个月咕咕咕博主终于更新了。。。。)
写在读前:博客内代码基本每句都含注释,请参考注释食用~
博客内容包括课程框架梳理,要点总结,笔者个人总结的拓展内容,PTA课后题解等等,多有理解不当或者概念错误请多多指出并加以包涵~
引例:二分查找;
引自百度百科词条 “二分查找”
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
引自百度百科词条 “二分查找的过程”
首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
通过递归实现的二分查找是分治算法应用的一个典型例子,分治算法的思想是“树”这一部分的基础,在第一章习题集中也略有提及,不了解的同学可以先看一下这篇题解(点我点我点我)中分治算法的部分,略窥一二。
二分查找又被形象地称为折半查找,“折半”即为分治中“分”的过程。在一个有序排列的线性结构中,每次查找将当前的范围一分为二,判断在哪一范围内,层层递归,最终找到目标。
代码实现:
//在表L中查找值为X的元素,返回其位置Poisiton;
Position BinarySearch(List L,ElementType X)
{
ElementType left=1,right=L->Last,answer=0;
while(left<=right)
{
ElementType mid=(left+right)/2;
if(L->Data[mid]>X) right=mid-1;
else left=mid+1;
}
if(L->Data[right]==X) return right;
else return NotFound;
}
树的基本介绍
不同于线性表中 “一个结点挨一个结点” 优先级都一致的结构 ,树中的结点拥有了一个 “优先级” ,一个结点可以连接多个结点,形成 “一对多” 的关系,对于一个结点及其所连接的结点,这个结点称为其所连接结点的 “父节点” ,其所连接的结点称为这个结点的 “子节点”。或大或小的树都是由这种具有 “父子关系” 的结构组成。
如图,A为{B,C,D,E}的父节点,{B,C,D,E}为A的子节点。
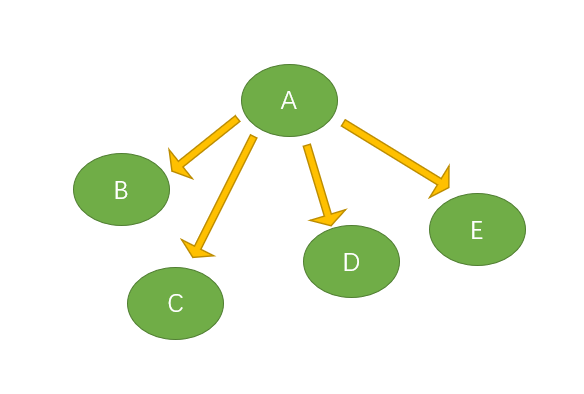
基本术语:
结点的度:该结点子树的个数;
树的度:所有结点中最大的度;
叶节点:度为0的结点
兄弟结点:若两个点拥有同一父节点,则这两个点互为兄弟结点。
根:所有点(不包括这个点本身)的“祖先结点”, 即最高级的 “父节点”。
祖先结点:如果一个节点的父节点仍然有父节点,则“这个点的父节点的父节点”称为此结点的祖先结点,同理,父节点的父节点的父节点也称为此点的祖先结点;
子孙结点:一个结点的子节点及其子节点的子节点及其… … … …都称为该点的子孙结点(禁止套娃)。
结点的层数(深度):规定根节点在第一层,其他任意一结点的层数是其父节点的层数加1。
树的深度:所有结点中最大的层数。
路径:从A结点到B结点,所经过的所有结点构成A到B的路径;
路径长度:此条路径上点的个数。
树的表示:
静态的基本单元表示法:
一棵树由一层一层的“子树”构成,往下分解到树的基本单位就是一个一个的结点,在线性表一章的学习中,我们所使用的数组和链表、栈、队列等,其基本单元的结构都是一致的,比如一个单向链表的基本单元的结构,由一个数据域和一个指针域构成。而到了树这里,我们仍然可以用数组或者链表来表示一棵树,但我们要考虑另外一个现象,结点A有4个子节点,而结点B有5个子结点,结点C有999个子节点。上述现象造成了在表示一棵树时,我们的基本单元的结构并不能确定,因为这个结点你开了4个指针域,而下一个结点可能就要用到8个指针。
链表:
针对上述现象,我们在这里再引入一个概念——二叉树:每个结点最多有两个子节点的树。
而对于任意一颗树,我们都可以将他转化为一颗二叉树,在何钦铭老师的课程中,我们学到一种特殊的树的结构表示方法——儿子兄弟表示法,即将每一个结点的子节点都连成一串链表,每个结点开两个指针,一个指向子节点链表的头节点,另一个指向与自己相邻的兄弟(因为当前结点也处于其父节点的子节点链表中)。详情如图:
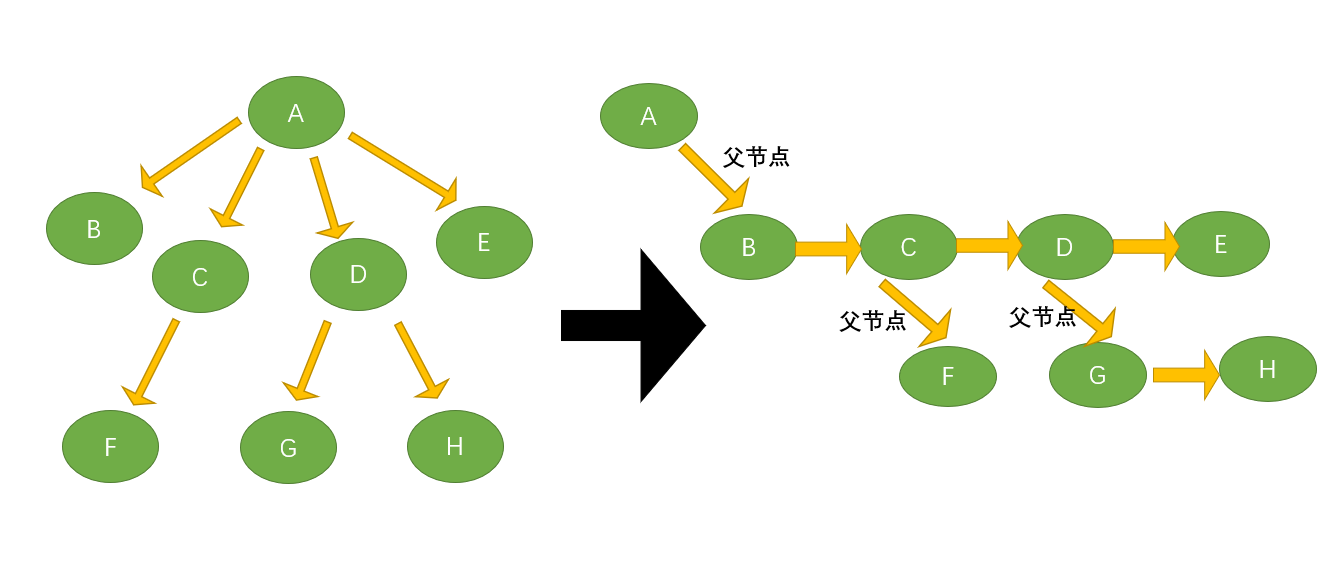
A具有两个指针,一个连接子节点链表,一个连接兄弟结点,因为A是根节点,所以A的第二个指针指向NULL;
B具有两个指针,因为是叶节点,没有子节点,所以第一个指向NULL,第二个指向与其相邻的兄弟节点C;
C的两个指针,一个指向子节点链表(链表中只有F),另一个指向与其相邻的兄弟节点D;
… … …
其他结点同理。
至此,我们原本具有1个、2个和4个指针的结点结构都可以化为具有两个结点的结构了。
基于此种思想,我们便可以化一般为特殊,使得任意一颗树都可以采用链表的方式储存,为了方便编写程序,我们也一般在解决问题时就将一颗普通树的化为一颗二叉树。
基本单位:
typedef struct node *PtrToNode;
struct Node{
ElementType Data;
PtrToNode left,right;
};
PtrToNode binary_tree;
数组:
既然我们已经有了能将树存入链表中的方法,那么能不能进一步简化,仅仅使用数组呢?
链表与数组的区别就在于指针的存在,我们只需要使用数组模拟指针即可。建立储存数据的Data[]数组,模拟左指针的数组left[]与模拟右指针的数组right[],将子节点的下标存入对应的两个数组即可。
动态的基本单元表示法(拓展内容):
上文中提到,我们通过构造二叉树避开了 “各结点指针数量不一致” 的问题,那么是否有其他的方法,不用创建新结构,更为直接的存储一颗树呢?
我们知道,树是一种特殊的图,可以把树看出是一种所有结点的入度都为1的,无环无权值的单向图。
图中的储存结构在树中同样适用,尤其是邻接表的表示方法,而作为对邻接表进行了空间再优化的向前星,也同样适用于储存图。
在上一章的学习记录中有关于向前星的详细讲解,有兴趣的读者请移步此处。
更新于2020.9.30凌晨。
最后
以上就是隐形书包最近收集整理的关于学习记录 mooc浙大数据结构第三、四讲 树的全部内容,更多相关学习记录内容请搜索靠谱客的其他文章。








发表评论 取消回复