K近邻算法:
对新的输入数据,在训练数据上找到与该实例最邻近的k个实例,k个实例的多数属于的类别作为输入数据的类别。
用于分监督学习的k近邻算法:
sklearn.neighbors.NearestNeighbors(n_neighbors=5,radius=1.0,algorithm='auto',leaf_size=30,
metric='minkowski',p=2,metric_params=None,n_jobs=1,**kwargs)
n_neighbors:int,默认为5
对输入数据进行投票的训练数据个数,即k的大小
对新的输入数据,在训练数据上找到与该实例最邻近的k个实例,k个实例的多数属于的类别作为输入数据的类别。
用于分监督学习的k近邻算法:
sklearn.neighbors.NearestNeighbors(n_neighbors=5,radius=1.0,algorithm='auto',leaf_size=30,
metric='minkowski',p=2,metric_params=None,n_jobs=1,**kwargs)
n_neighbors:int,默认为5
对输入数据进行投票的训练数据个数,即k的大小
radius:float,默认1.0
radius_neighbors查询时默认的参数空间范围,即半径。给定目标点及半径r,在目标点为圆心,r为半径的圆中的点距目标点更近
radius_neighbors查询时默认的参数空间范围,即半径。给定目标点及半径r,在目标点为圆心,r为半径的圆中的点距目标点更近
algorithm:{'auto','ball_tree','kd_tree','brute'}
计算最近邻使用的算法,输入为稀疏表示时会强制使用brute
计算最近邻使用的算法,输入为稀疏表示时会强制使用brute
leaf_size:int,默认30
BallTree或KDTree的叶节点数,即子区域个数。会影响树结构建立和查询的速度以及耗费的内存。
BallTree或KDTree的叶节点数,即子区域个数。会影响树结构建立和查询的速度以及耗费的内存。
metric:string或函数调用,默认'minkowsik'。
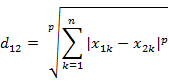
计算距离的方式。可以使用scikit-learn或者scipy.spatial.distance定义个任意方式.
p:int,默认2
minkowski的参数。p=1时为曼哈顿距离,p=2为欧式距离。
minkowski的参数。p=1时为曼哈顿距离,p=2为欧式距离。
metric_params:字典,默认None。对metric的追加参数
n_jobs:int ,默认1
并行计算的工作数,即CPU的占用个数
并行计算的工作数,即CPU的占用个数
方法:
fit(X[,y])
X:{array-like,sparse matrix,BallTree,KDTree}
训练数据,X为array 或matrix,shape(n_samples,n_features)。或者直接传入构建完成的数结构
fit(X[,y])
X:{array-like,sparse matrix,BallTree,KDTree}
训练数据,X为array 或matrix,shape(n_samples,n_features)。或者直接传入构建完成的数结构
get_params(deep=True):获取模型的参数映射关系
kneighbors(X=None,n_neighbors=None,return_distance=True)
寻找点的k个最近邻,返回每个最近邻点的索引和距离。
X:array-like,shape(n_query,n_features)。
n_neighbors:int.获得的最近邻点个数,默认是构造函数的n_neighbors值
return_distance:boolean,默认True
是否返回距离
返回值:
dist:array,表示目标点到k个最近邻的距离矩阵
ind:array,表示k个最近邻的索引值矩阵
example:
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(algorithm='kd_tree')
train = np.array([[2,3],[5,4],[9,6],[4,7],[8,1],[7,2]])
nn.fit(train)
dist,ind = nn.kneighbors(X=[[1,3],[5,5]],n_neighbors=2)
print(dist)
#[[1. 4.12310563]
# [1. 2.23606798]]
print(ind)
#[[0 1]
# [1 3]]
寻找点的k个最近邻,返回每个最近邻点的索引和距离。
X:array-like,shape(n_query,n_features)。
n_neighbors:int.获得的最近邻点个数,默认是构造函数的n_neighbors值
return_distance:boolean,默认True
是否返回距离
返回值:
dist:array,表示目标点到k个最近邻的距离矩阵
ind:array,表示k个最近邻的索引值矩阵
example:
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(algorithm='kd_tree')
train = np.array([[2,3],[5,4],[9,6],[4,7],[8,1],[7,2]])
nn.fit(train)
dist,ind = nn.kneighbors(X=[[1,3],[5,5]],n_neighbors=2)
print(dist)
#[[1. 4.12310563]
# [1. 2.23606798]]
print(ind)
#[[0 1]
# [1 3]]
kneighbors_graph(X=None,n_neighbors=None,mode='connectivity')
为X的每一个点计算权值图
X:array-like,shape(n_query,n_features)。如果为None,会计算每一个训练点
n_neighbors:int.获得的最近邻点个数,默认是构造函数的n_neighbors值
mode:{'connectivity','distance'}
'connectivity'会返回0,1构成的连接矩阵,'distance'返回点与点的欧氏距离
为X的每一个点计算权值图
X:array-like,shape(n_query,n_features)。如果为None,会计算每一个训练点
n_neighbors:int.获得的最近邻点个数,默认是构造函数的n_neighbors值
mode:{'connectivity','distance'}
'connectivity'会返回0,1构成的连接矩阵,'distance'返回点与点的欧氏距离
返回:
A:shape(n_samples,n_samples_fit)的稀疏矩阵。
A[i,j]是连接i,j的边的权值。
example:
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(algorithm='kd_tree',n_neighbors=1)
train = np.array([[2,3],[5,4]])
nn.fit(train)
print(nn.kneighbors_graph(mode='distance').toarray())
#[[0. 3.16227766]
# [3.16227766 0. ]]
A:shape(n_samples,n_samples_fit)的稀疏矩阵。
A[i,j]是连接i,j的边的权值。
example:
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(algorithm='kd_tree',n_neighbors=1)
train = np.array([[2,3],[5,4]])
nn.fit(train)
print(nn.kneighbors_graph(mode='distance').toarray())
#[[0. 3.16227766]
# [3.16227766 0. ]]
radius_neighbors(X=None,radius=None,return_distance=True)
返回以X为球心,radius为半径的超球体中的所有数据点
X:array-like,shape(n_samples,n_features)
radius:flaot,半径.
return_distance:boolean,默认True
是否返回距离
返回:
dist:array,shape(n_samples,)表示目标点到球体中的数据点的距离矩阵
ind:array,shape(n_samples,)表示求体重的数据点的索引值矩阵
example:
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(algorithm='kd_tree',n_neighbors=1)
train = np.array([[2,3],[5,4]])
nn.fit(train)
dist,ind = nn.radius_neighbors([[3,3]],radius=2)
print(ind[0][0])
#0
print(dist[0][0])
#1.0
返回以X为球心,radius为半径的超球体中的所有数据点
X:array-like,shape(n_samples,n_features)
radius:flaot,半径.
return_distance:boolean,默认True
是否返回距离
返回:
dist:array,shape(n_samples,)表示目标点到球体中的数据点的距离矩阵
ind:array,shape(n_samples,)表示求体重的数据点的索引值矩阵
example:
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(algorithm='kd_tree',n_neighbors=1)
train = np.array([[2,3],[5,4]])
nn.fit(train)
dist,ind = nn.radius_neighbors([[3,3]],radius=2)
print(ind[0][0])
#0
print(dist[0][0])
#1.0
radius_neighbors_graph(X=None,radius=None,mode='connectivity')
为在超球体中的数据点计算权值图
X:array-like,shape(n_query,n_features)。如果为None,会计算每一个训练点
radius:float.超球体的半径,默认是构造函数的radius值
mode:{'connectivity','distance'}
'connectivity'会返回0,1构成的连接矩阵,'distance'返回点与点的欧氏距离
为在超球体中的数据点计算权值图
X:array-like,shape(n_query,n_features)。如果为None,会计算每一个训练点
radius:float.超球体的半径,默认是构造函数的radius值
mode:{'connectivity','distance'}
'connectivity'会返回0,1构成的连接矩阵,'distance'返回点与点的欧氏距离
返回:
A:shape(n_samples,n_samples_fit)的稀疏矩阵。
A[i,j]是连接i,j的边的权值。
example:
>>> X = [[0], [3], [1]]
>>> from sklearn.neighbors import NearestNeighbors
>>> neigh = NearestNeighbors(radius=1.5)
>>> neigh.fit(X)
NearestNeighbors(algorithm='auto', leaf_size=30, ...)
>>> A = neigh.radius_neighbors_graph(X)
>>> A.toarray()
array([[ 1., 0., 1.],
[ 0., 1., 0.],
[ 1., 0., 1.]])
A:shape(n_samples,n_samples_fit)的稀疏矩阵。
A[i,j]是连接i,j的边的权值。
example:
>>> X = [[0], [3], [1]]
>>> from sklearn.neighbors import NearestNeighbors
>>> neigh = NearestNeighbors(radius=1.5)
>>> neigh.fit(X)
NearestNeighbors(algorithm='auto', leaf_size=30, ...)
>>> A = neigh.radius_neighbors_graph(X)
>>> A.toarray()
array([[ 1., 0., 1.],
[ 0., 1., 0.],
[ 1., 0., 1.]])
set_params(**params):设置参数
sklearn.neighbors.KDTree(X,leaf_size=40,metric='minkowski',**kwargs)
为n个点构造KDTree
X:array-like,shape(n_samples,n_features)
leaf_size:正数,默认40
保证leaf_size<=n_points<=2*leaf_size
metric:str.默认计算欧式距离
为n个点构造KDTree
X:array-like,shape(n_samples,n_features)
leaf_size:正数,默认40
保证leaf_size<=n_points<=2*leaf_size
metric:str.默认计算欧式距离
属性:
data:np.ndarray
data:np.ndarray
方法:
query(X,k=1,return_distance=True,dualtree=False,breadth_first=False)
X:array-like,待查询的数据点
k:返回的最近邻个数
dualtree:True时使用两种形式的树,数据量大时效果更好
breadth_first:boolean,默认false
True:查询时广度优先,否则深度优先
query(X,k=1,return_distance=True,dualtree=False,breadth_first=False)
X:array-like,待查询的数据点
k:返回的最近邻个数
dualtree:True时使用两种形式的树,数据量大时效果更好
breadth_first:boolean,默认false
True:查询时广度优先,否则深度优先
返回:
i:return_distance==False
(d,i):return_distance==True
d,i即为上述dist,ind
example:
from sklearn.neighbors import KDTree
X = np.array([[2,3],[5,4],[9,6]])
kd = KDTree(X,leaf_size=2)
dist,ind = kd.query([[3,3]])
print(dist)
#[[1.]]
print(ind)
#[[0]]
i:return_distance==False
(d,i):return_distance==True
d,i即为上述dist,ind
example:
from sklearn.neighbors import KDTree
X = np.array([[2,3],[5,4],[9,6]])
kd = KDTree(X,leaf_size=2)
dist,ind = kd.query([[3,3]])
print(dist)
#[[1.]]
print(ind)
#[[0]]
query_radius(X,r):查询在半径r的超球体内的数据点,返回信息类似query.
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,weights='uniform',algorithm='auto',leaf_size=30,
p=2,metric='minkowski',metric_params=None,n_jobs=1,**kwargs)
通过k近邻的投票对输入数据分类
weights:str 或者callable,默认'uniform'
'uniform':所有数据点权值一样。
'distance':根据距离确定权值,越近权值越大,对数据点的结果影响越大
[callable]:用户定义的计算权值的函数
fit(X,y):
X:{array-like, sparse matrix, BallTree, KDTree}.训练数据
y : {array-like, sparse matrix}.对应的目标值
X:{array-like, sparse matrix, BallTree, KDTree}.训练数据
y : {array-like, sparse matrix}.对应的目标值
kneighbors(X=None, n_neighbors=None, return_distance=True)
kneighbors_graph(X=None, n_neighbors=None, mode=’connectivity’)
kneighbors_graph(X=None, n_neighbors=None, mode=’connectivity’)
predict(X):
预测输入数据的类别。
X:array-like, shape (n_query, n_features), or (n_query, n_indexed) if metric == ‘precomputed’
y:array of shape [n_samples] or [n_samples, n_outputs]预测结果
预测输入数据的类别。
X:array-like, shape (n_query, n_features), or (n_query, n_indexed) if metric == ‘precomputed’
y:array of shape [n_samples] or [n_samples, n_outputs]预测结果
predict_proba(X):
返回预测结果的概率
X:array-like, shape (n_query, n_features), or (n_query, n_indexed) if metric == ‘precomputed’
y:array of shape [n_samples, n_classes]预测结果的概率
返回预测结果的概率
X:array-like, shape (n_query, n_features), or (n_query, n_indexed) if metric == ‘precomputed’
y:array of shape [n_samples, n_classes]预测结果的概率
score(X,y,sample_weight=None):
计算平均正确率
from sklearn.neighbors import KNeighborsClassifier
X = np.array([[-1,-1],[-2,-1],[-1,-2],[1,1],[2,1],[1,2]])
y = np.array([-1,-1,-1,1,1,1])
knc = KNeighborsClassifier(leaf_size=3,n_neighbors=3)
knc.fit(X,y)
print(knc.predict_proba([[3,3],[-3,-2]]))
#[[0. 1.]
# [1. 0.]]
print(knc.score([[1.5,2.5],[-1.5,-3],[3,-1]],[1,-1,1]))
#1.0
计算平均正确率
from sklearn.neighbors import KNeighborsClassifier
X = np.array([[-1,-1],[-2,-1],[-1,-2],[1,1],[2,1],[1,2]])
y = np.array([-1,-1,-1,1,1,1])
knc = KNeighborsClassifier(leaf_size=3,n_neighbors=3)
knc.fit(X,y)
print(knc.predict_proba([[3,3],[-3,-2]]))
#[[0. 1.]
# [1. 0.]]
print(knc.score([[1.5,2.5],[-1.5,-3],[3,-1]],[1,-1,1]))
#1.0
sklearn.neighbors.KneighborsRegressor(n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30,
p=2, metric=’minkowski’, metric_params=None, n_jobs=1, **kwargs)
预测回归问题,根据k个最近邻点及其对应的权值求均值作为测试数据的目标值
用法同上。
p=2, metric=’minkowski’, metric_params=None, n_jobs=1, **kwargs)
预测回归问题,根据k个最近邻点及其对应的权值求均值作为测试数据的目标值
用法同上。
最后
以上就是傻傻冰棍最近收集整理的关于sklearn.neighbors常用API介绍的全部内容,更多相关sklearn内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复