一、引言
1、什么是Redis?
Redis是一款基于内存的键-值型NoSQL数据库。NoSQL - 非关系型数据库
特点:可以进行快速的数据读写,官方给的数据 11W/s 读 8W/s 写。
Memcache
2、Redis在实际开发中的运用场景
1)作为分布式系统的缓存服务器
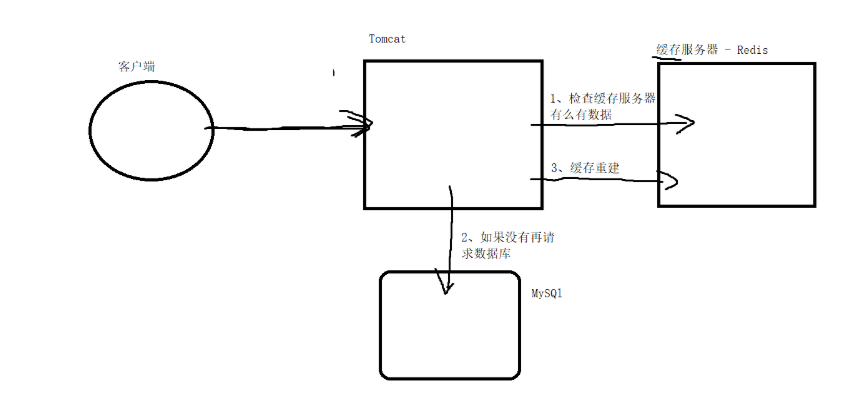
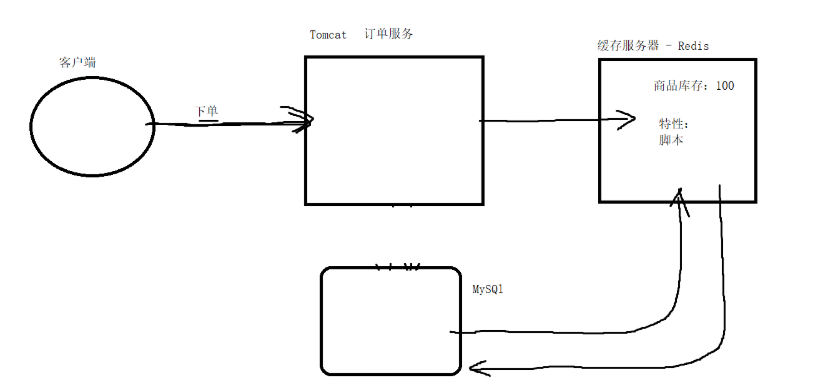
2)应对数据高速读写的业务
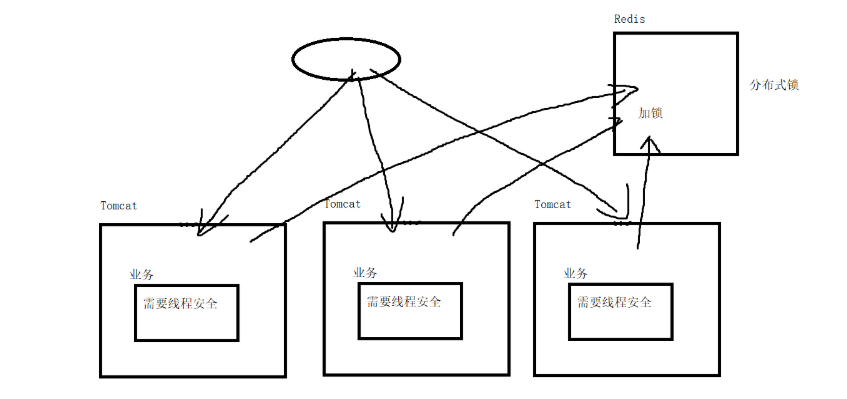
3)作为分布式锁使用(Zookeeper、Redis)
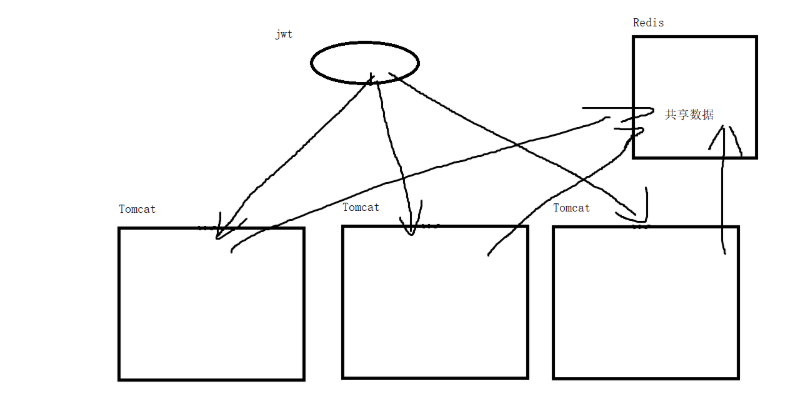
4)数据共享
5)ID自增序列
二、Docker安装Redis
1)在合适位置准备好redis.conf配置文件
./redis/conf/redis.conf
注意:./表示docker-compose.yml所在的路径
2)编写docker-compose.yml
redis:
image: redis:5
container_name: redis
restart: always
ports:
- 6379:6379
volumes:
- ./redis/conf/redis.conf:/etc/redis/redis.conf
- ./redis/conf/data:/data
command:
['redis-server', '/etc/redis/redis.conf']
3)修改宿主机中的redis.conf配置文件( 0.0.0.0在服务器的环境中,指的就是服务器上所有的ipv4地址, 所有机器上的地址都可以访问服务 )
把
bind 127.0.0.1
改成
bind 0.0.0.0
4)重启redis并且通过工具连接操作redis
三、Java通过API操作redis
1)添加依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.0.1</version>
</dependency>
2)编写代码操作redis
//通过连接池
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(100);
poolConfig.setMaxIdle(50);
poolConfig.setMinIdle(20);
JedisPool jedisPool = new JedisPool(poolConfig,"192.168.195.188", 6379);
Jedis jedis = jedisPool.getResource();
//连接redis
// Jedis jedis = new Jedis("192.168.195.188", 6379);
//操作redis
// jedis.set("money", "10000");
String value = jedis.get("money");
System.out.println(value);
//关闭连接
jedis.close();
四、Spring通过API操作redis
1)添加依赖
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>2.2.3.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.2.7.RELEASE</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.0.1</version>
</dependency>
</dependencies>
2)配置applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- 配置redis连接池对象 -->
<bean id="poolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!-- 最大空闲数 -->
<property name="maxIdle" value="50"/>
<!-- 最大连接数 -->
<property name="maxTotal" value="100"/>
<!-- 最大等待时间 -->
<property name="maxWaitMillis" value="20000"/>
</bean>
<!-- 配置redis连接工厂 -->
<bean id="connectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory">
<!-- 连接池配置 -->
<property name="poolConfig" ref="poolConfig"/>
<!-- 连接主机 -->
<property name="hostName" value="192.168.195.188"/>
<!-- 端口 -->
<property name="port" value="6379"/>
</bean>
<bean id="stringRedisSerializer" class="org.springframework.data.redis.serializer.StringRedisSerializer"></bean>
<bean id="jdkSerializationRedisSerializer" class="org.springframework.data.redis.serializer.JdkSerializationRedisSerializer"></bean>
<!-- 配置redis模板对象 -->
<bean class="org.springframework.data.redis.core.RedisTemplate">
<!-- 配置连接工厂 -->
<property name="connectionFactory" ref="connectionFactory"/>
<property name="keySerializer" ref="stringRedisSerializer"/>
<property name="valueSerializer" ref="stringRedisSerializer"/>
</bean>
</beans>
注意:Spring整合Redis提供的RedisTemplate默认对 key 和 value进行jdk的序列化操作。这样做的好处在于可以存放类型复杂的key-value,但是到了redis中会变成序列化的字符串,命令不能直接操作。
建议实际开发过程中,换成字符串的序列化方式,如果需要存放类型复杂的对象,可以手动的转换成JSON字符串。
五、SpringBoot整合Redis
1)添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2)配置application.yml
spring:
redis:
host: 192.168.195.188
port: 6379
3)注入对象操作redis
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private StringRedisTemplate stringRedisTemplate;
....
六、Redis常见的数据类型(https://www.redis.net.cn/)
1)String类型
结构:key - value
常用命令:
set key value
get key
incr key
incrby key xxx
decr key
decrby key xxx
2)Hash类型
结构:key - value(field, value)…
常用命令:
hset key field value
hget key field
hgetall key
hdel key field运用场景:通常用来保存一个对象,field对应对象中的一个属性。
案列:gateway基于redis实现令牌桶算法限流:hash结构是key filed value 这个key就是桶的名字,filed就是令牌的数量 ,和桶的令牌最大的数量
3)List类型 - 链表
结构:key - value1,value2,value3…
特点:value有多个,可以重复,并且有序,底层是一个双向链表
常用命令:
lpush key value1 value2…
rpush key value1 value2…
llen key
lpop key
rpop key
lrange key beginIndex endIndex (含头含尾)
4)Set类型 - 集合
结构:key - value3,value2,value4,value1
特点:value有多个,无序不可重复,底层是一张哈希表
常用命令:
sadd key value1 value2…
smembers key
scard key运用场景:去重、判断唯一、判定是否存在
案列:
防止提前下单的操作: reids有一个数据set集合,set集合底层用的是哈希表,哈希表可以用来,判断是否存在。
5)Zset类型 - 有序集合
结构:key - (score1, value1) (score2, value2)…
特点:value有多个,每个value都携带一个评分,根据评分排序,元素不能重复,底层是一张跳跃表
常用的命令:
zadd key score1 value1 score2 value2 …
zscan key cursor
zcard key
zrange key startindex endindex
zrevrangebyscore key maxScore minScore运用场景:热门搜索词 - 搜索词的搜索频率设置score
案列: 客户端发送一个消息,在抢卷服务设置提醒计算开抢时间,然后存到redis的有序集合里,以年月日为key,value就是用户id和优惠券id(时间段)绑定在一起。系统时间一到就会触发定时任务,获得当前时间,把这个时间在redis查询,然后循环的通知netty服务的消息中心在通知到客户端。
6)redis中非类型相关的常见命令
keys * - 查看当前redis库中所有的key
type key - 返回key对应的数据类型
del key - 删除指定的key,无论数据类型
select index - 选择指定的数据库(0 ~ 15)
flushdb - 清空当前的数据库的所有key
flushall - 清空所有数据库的所有key
#对应的SpringBoot中的API操作代码
stringRedisTemplate.opsForValue();//操作String类型
stringRedisTemplate.opsForHash();//操作hash类型
stringRedisTemplate.opsForList();//操作list类型
stringRedisTemplate.opsForSet();//操作set类型
stringRedisTemplate.opsForZSet();//操作zset类
stringRedisTemplate.expire("", 5, TimeUnit.MINUTES);
stringRedisTemplate.delete("");
七、Redis的超时时间
7.1 redis的超时时间有什么用?
redis通常作为缓存服务器存在,数据库中的很多数据都会缓存到redis中,以此减少数据库的访问压力。但是因为存储单位的不同,不可能将所有的数据库数据都缓存到redis中,只能缓存局部数据。实际开发中,肯定希望redis尽可能的缓存热点数据,如何判断哪些数据是热点数据? 通过给key设置超时时间可以帮助redis过滤掉很多的冷门数据。
7.2 超时时间的相关命令
expire key - 给key设置超时时间,单位是秒
persist key - 移除key的超时时间
ttl key - 查看key的剩余超时时间
-2 表示当前key不存在
-1 表示当前key永生
注意:redis中,key如果过期的话,并不会立刻从内存中移除,在redis中移除过期key的机制:
1)当客户端需要使用到某个key时
2)后台有个线程间隔的扫描所有过期的key,再进行移除
八、redis的内存淘汰策略
8.1 什么是redis的内存淘汰策略?
简单来说,就是当redis发现自己内存满了之后,怎么办?
8.2 如何配置Redis的内存淘汰策略?
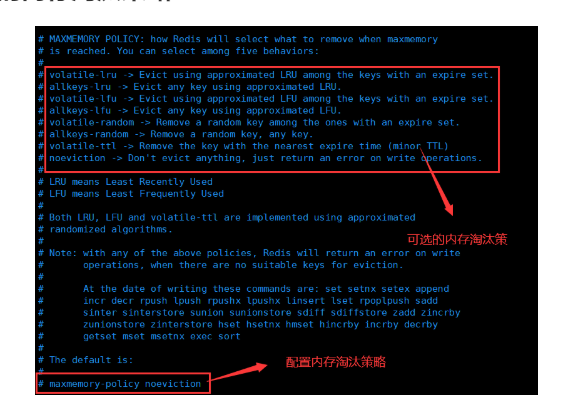
内存淘汰策略的可选项:
volatile-lru -> Evict using approximated LRU among the keys with an expire set.
allkeys-lru -> Evict any key using approximated LRU.
volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
allkeys-lfu -> Evict any key using approximated LFU.
volatile-random -> Remove a random key among the ones with an expire set.
allkeys-random -> Remove a random key, any key.
volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
noeviction -> Don’t evict anything, just return an error on write operations.可选值:
noeviction -> redis变成只读模式
volatile-lru -> 在所有设置了过期时间的key中,淘汰最近最少被使用的key
allkeys-lru -> 在所有的key中,淘汰最近最少被使用的key
volatile-lfu -> 在所有设置了过期时间的key中,淘汰总共最少被使用的key
allkeys-lfu -> 在所有的key中,淘汰总共最少被使用的key
volatile-random -> 在所有设置了过期时间的key中,随机淘汰key
allkeys-random -> 在所有的key中,随机淘汰key
volatile-ttl -> 在所有设置了过期时间的key中,淘汰存活时间最短的key前缀后缀:
allkeys - 表示所有的key
volatile - 表示设置了过期时间的keylru - 最近最少被使用
lfu - 总共最少被使用
random - 随机
ttl - 存活时间最短
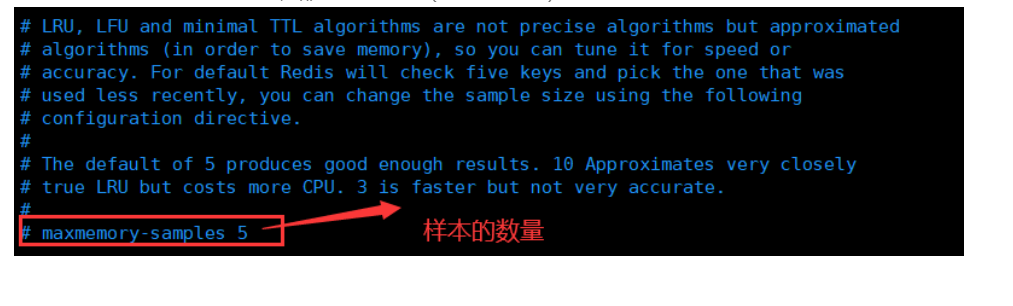
注意:redis中的所有淘汰策略,都是近似算法(lru、lfu、ttl)
九、Redis的lua脚本
9.1 Redis的线程模型
redis是单线程模型的服务。所有的Redis单线程,并不是说Redis服务只有一个线程,确切来说,只有一个主线程在接收执行客户端的命令。
为什么Redis要设计成单线程?
Redis的执行效率瓶颈不在于CPU,Redis的效率瓶颈在于网络,多线程执行命令对于Redis来说,反而要额外的进行线程切换的开销。
单线程的Redis是否意味着线程安全?
Redis内部确实是线程安全的,但是调用Redis的服务不一定线程安全?
往往可以基于 单线程特性 + Lua脚本 实现无锁化的线程安全业务。
注意:
1、Lua脚本中不能执行耗时操作,如果执行超过5S的lua脚本,Redis服务会自动停止lua脚本运行。
2、Redis 6.0之后,开始支持多线程。主线程 + n个IO线程,IO线程主要负责连接的处理,数据的读写,所有IO线程的命令会交给主线程执行。
9.2 Lua脚本的基本语法
Redis执行lua脚本的语法:
eval SCRIPT numkeys [key …] [arg …]
解释:
eval 固定写法,表示执行一个lua脚本
SCRIPT 脚本内容
numkeys 脚本中key变量的数量
[key …] 传入脚本的key变量的实际值
[arg …] 传入脚本中的附加参数的实际值
在lua脚本中,操作redis的语法:
redis.call(‘…’, ‘…’, ‘…’);
比如:set name xiaoming -> redis.call(‘set’, ‘name’, ‘xiaoming’)
案例:
eval “return redis.call(‘get’, ‘name’)” 0
eval “return redis.call(‘set’, KEYS[1], ARGV[1])” 1 name xiaohong
eval “redis.call(‘hset’, KEYS[1], ARGV[1], ARGV[2])” 1 person sex man练习:求取一个链表所有元素的平均值
--获得redis链表的总长度 local agesLength = redis.call('llen', KEYS[1]) --获得redis链表的所有元素放入一个对象(数组) local ages = redis.call('lrange', KEYS[1], 0, agesLength) --临时变量 local ageSum = 0 --循环数组,年龄的累加 for i=1,#ages do --循环体 ageSum = ages[i] + ageSum end --求取平均值 return ageSum/#ages
lua脚本的缓存
缓存脚本:script load “SCRIPT” 返回一个sha签名字符串
执行缓存脚本:evalsha “脚本签名” numkeys [key …] [arg …]
9.3 SpringBoot中执行lua脚本
/**
* 执行lua脚本
*/
@Test
void script(){
String str = "--获得redis链表的总长度n" +
"local agesLength = redis.call('llen', KEYS[1])n" +
"n" +
"--获得redis链表的所有元素放入一个对象(数组)n" +
"local ages = redis.call('lrange', KEYS[1], 0, agesLength)n" +
"n" +
"--临时变量n" +
"local ageSum = 0n" +
"n" +
"--循环数组,年龄的累加n" +
"for i=1,#ages don" +
" --循环体n" +
" ageSum = ages[i] + ageSumn" +
"endn" +
"n" +
"--求取平均值n" +
"return ageSum/#ages";
//创建一个脚本对象
DefaultRedisScript script = new DefaultRedisScript(str, Long.class);
List<String> keys = new ArrayList<>();
keys.add("ages");
//执行脚本
Long result = (Long) stringRedisTemplate.execute(script, keys);
System.out.println("脚本执行的结果:" + result);
}
十、使用Redis的lua脚本,实现分布式锁
package com.qf.util;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.stereotype.Component;
import java.util.Collections;
import java.util.UUID;
@Component
public class LockUtil {
@Autowired
private StringRedisTemplate redisTemplate;
//加锁的lua脚本
private String lockLua = "--锁的名称n" +
"local lockName=KEYS[1]n" +
"--锁的valuen" +
"local lockValue=ARGV[1]n" +
"--过期时间 秒n" +
"local timeout=tonumber(ARGV[2])n" +
"--尝试进行加锁n" +
"local flag=redis.call('setnx', lockName, lockValue)n" +
"--判断是否获得锁n" +
"if flag==1 thenn" +
"--获得分布式锁,设置过期时间n" +
"redis.call('expire', lockName, timeout)n" +
"endn" +
"--返回标识n" +
"return flag ";
//解锁的lua脚本
private String unLockLua = "--锁的名称n" +
"local lockName=KEYS[1]n" +
"--锁的valuen" +
"local lockValue=ARGV[1]n" +
"--判断锁是否存在,以及锁的内容是否为自己加的n" +
"local value=redis.call('get', lockName)n" +
"--判断是否相同n" +
"if value == lockValue thenn" +
" redis.call('del', lockName)n" +
" return 1n" +
"endn" +
"return 0";
private ThreadLocal<String> tokens = new ThreadLocal<>();
/**
* 加锁
* @return
*/
public void lock(String lockName){
lock(lockName, 30);
}
public void lock(String lockName, Integer timeout){
String token = UUID.randomUUID().toString();
//设置给threadLocal
tokens.set(token);
//分布式锁 - 加锁
Long flag = (Long) redisTemplate.execute(new DefaultRedisScript(lockLua, Long.class),
Collections.singletonList(lockName),
token, timeout + ""
);
System.out.println("获得锁的结果:" + flag);
//设置锁的自旋
if (flag ==0) {
//未获得锁
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock(lockName, timeout);
}
}
/**
* 解锁
* @return
*/
public boolean unlock(String lockName){
//获得ThreadLocal
String token = tokens.get();
//解锁
Long result = (Long) redisTemplate.execute(new DefaultRedisScript(unLockLua, Long.class),
Collections.singletonList(lockName),
token);
System.out.println("删除锁的结果:" + result);
return result == 1;
}
}
十一、Redis的持久化
为什么要持久化?
因为,redis本身运行时数据保存在内存中,如果不进行持久化,那么在redis出现非正常原因宕机或者关闭redis的进程或者关闭计算机后数据肯定被会操作系统从内存中清掉。
11.1 Redis持久化的方式
1)RDB - 默认
快照 - 将redis当前瞬间的内存结构记录并且保存到硬盘上
2)AOF - 默认关闭
AOF (Append only file) - 记录所有redis执行过的写命令,当需要恢复数据时,重放这些写命令即可
11.2 RDB相关命令和配置
快照相关的命令
save - 手动执行一个前台快照,由当前主线程执行快照,在快照的过程当中,不能执行任何命令
bgsave - 手动执行一个后台快照,会开启一个新的线程进快照操作,但是开发者没办法获得快照的结果
快照的相关配置
快照的执行频率,每xx秒后,有xx数据发生变化,就执行一个快照
save 900 1
save 300 10
save 60 10000当bgsave错误时,前台是否需要停止写入操作
stop-writes-on-bgsave-error yes配置快照文件的名字和路径
dbfilename dump.rdb
dir ./
11.3 AOF的相关配置
AOF的相关配置
配置是否开启AOF
appendonly no - 默认关闭配置AOF的文件名称
appendfilename “appendonly.aof”配置AOF的记录频率
appendfsync always - 每执行一个写命令,就记录一次
appendfsync everysec - 默认行为,每秒记录当前这一秒钟所有的写命令
appendfsync no - 根据操作系统的配置决定什么时候快照配置AOF文件的重写的条件
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
AOF文件的优化策略:
Bgrewriteaof命令 - 手动触发后台对aof文件的重写,重写后会得到一个体积优化版
redis会自动的触发AOF文件重写
11.4 快照和AOF的选择策略
1、找时机开发过程中,AOF往往比快照更安全,AOF最多只会丢失1S以内的数据
2、redis服务启动后,先根据AOF文件恢复数据,再恢复快照的数据
3、当数据量很大时,快照恢复的速度要快与AOF
4、如果希望数据相对更安全,官方推荐同时开启快照和AOF,但是仍然不能保证数据的绝对安全
5、如果Redis仅仅只是作为分布式缓存服务器使用,快照和AOF都可以关闭
十二、Redis作为缓存服务器的使用
12.1 自定义缓存策略
@Override
public List<Student> queryAll() {
//获取缓存中的数据
List<Student> stulist = (List<Student>) redisTemplate.opsForValue().get("stulist");
if(stulist == null) {
//如果缓存中没有,再查询数据
System.out.println("查询了数据库?");
stulist = stuDao.selectList(null);
//缓存重建
redisTemplate.opsForValue().set("stulist", stulist, 10, TimeUnit.MINUTES);
}
return stulist;
}
@Override
@Transactional
public Student insert(Student student) {
stuDao.insert(student);
//删除必要的缓存
redisTemplate.delete("stulist");
//新建学生缓存
redisTemplate.opsForValue().set("stuone_" + student.getId(), student, 10, TimeUnit.MINUTES);
return student;
}
@Override
public Student queryOne(Integer id) {
Student student = (Student) redisTemplate.opsForValue().get("stuone_" + id);
if(student == null){
System.out.println("查询数据了!!!!");
student = stuDao.selectById(id);
redisTemplate.opsForValue().set("stuone_" + id, student, 10, TimeUnit.MINUTES);
}
return student;
}
@Override
public int deleteById(Integer id) {
int result = stuDao.deleteById(id);
//删除必要的缓存
redisTemplate.delete("stulist");
redisTemplate.delete("stuone_" + id);
return result;
}
/**
* 修改数据时,数据库和缓存服务器一致性问题
* 1、修改数据库,修改缓存 - 相对比较大的概率引起数据不一致
* 在A线程 - 修改数据库学生1,即将修改缓存的时候这里被打断进入B线程,修改数据库,修改缓存;这个时候的a线程在去修改数据库已经没有意义了,数据库已经被修改过了。
* 2、修改缓存,修改数据库 - 相对比较大的概率引起数据不一致
* 在A线程 - 修改缓存学生1,即将修改数据库的时候这里被打断进入B线程,修改缓存这个时候就会把a线程修改的缓存给覆盖掉再去修改数据库;(所以以后操作redis不要修改自己删除就没有覆盖的问题了)
* 3、删除缓存,修改数据库 - 相对比较大的概率引起数据不一致
* 在A线程 - 删除缓存学生1,即将修改数据库的时候这里被打断进入B线程,删除缓存再去修改数据库,这个是没问题的,怕就怕在B线程是去查询缓存的,这个时候缓存被删了去查询数据库然后在重建缓存,这个时候到了a线程去修改数据库这个时候数据又不一致了
* 4、修改数据库,删除缓存 - 相对来说出问题的概率较小
* B线程,查询学生1,先查缓存,缓存失效了,缓存没有再查数据库这个时候(A线程这里被打断进入 - 修改数据库学生删除缓存),然后b线程重建缓存(这里重建的数据就是a线程的数据),
*
所以这个时候就可以看出一般都是删缓存放在数据的后面,出问题概率比较小所以得用缓存注解
* 延时双删:修改数据 -> 删除缓存 -> 延迟2s -> 删除缓存
*
*
* @param id
* @return
*/
@Override
public int updateById(Integer id) {
Student student = this.queryOne(id);
student.setName(student.getName() + 1);
int result = stuDao.updateById(student);
//删除必要的缓存
redisTemplate.delete("stulist");
redisTemplate.delete("stuone_" + id);
return result;
}
12.2 Spring提供的缓存操作注解
1)添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
2)启动类配置注解
@EnableCaching
3)配置application.yml
spring:
redis:
host: 192.168.195.188
#配置缓存的过期时间
cache:
redis:
time-to-live: 600000
4)使用注解完全缓存的操作
@Cacheable
- 通常用于查询业务,先去缓存服务器查询,如果有结果直接返回,如果没有,再调用目标方法执行业务,并且将目标方法的返回值重建到缓存中
@CachePut
- 标记了该注解的方法,一定会被执行,将方法的返回值重建到缓存中,多用于添加的业务(就是添加的到缓存中,查询就直接在缓存中查)
@CacheEvict
- 表示删除某个缓存,多用于新增、修改、删除的业务
@Caching
- 以上3个注解的数组集合体
@CacheConfig
- 进行缓存的统一配置,标记在类上
12.3 分布式缓存的常见问题
1)缓存击穿
客户端恶意的访问一个不存在的数据,从而穿透缓存,请求到达数据库,频繁的发送这类请求,直接查询数据库,增加数据库的压力。
解决:
1、在缓存服务中缓存null值
2、用户黑名单(ip拉黑)-》但是如果黑客用木马植入很多电脑去访问这个方法也是没办法的
3、使用布隆过滤器(判断,一个数据可能存在或者一定不存在)他其实是一张大的哈希表,他的能够判断一个数据可能存在或者一定不存在,在大量数据面前,我只要设置好布隆过滤器之后,访问数据布隆过滤器非常快的判断这个数据,一定不存在就一定不存在,可能存在就不一定了,可能存在的误差就很低他还可以帮我们实现点击率
2)缓存失效
某个缓存失效之后,大量的请求访问该数据,在第一个请求重建缓存回来之前,大量的请求发现缓存失效,都会去尝试重建缓存,从而导致数据库压力增加。
解决:
1、在重建缓存时,添加分布式锁
3)缓存雪崩
大量的缓存,在同一时刻一起失效。
解决:
1、新建缓存时,采用固定 + 随机数的方式设置过期时间;错开他们的过期时间
4)缓存预热
在项目运行之前,分析出热点数据,直接添加到缓存服务器中(统计结果或者大数据分析)
十三、Redis集群结构
13.1 主从集群
主从复制:
1、简单来说,是使用两个或两个以上相同的数据库,将一个数据库当做主数据库,而另一个数据库当做从数据库。在主数据库中进行相应操作时,从数据库记录下所有主数据库的操作,使其二者一模一样。
2、当主数据库出现问题时,可以当从数据库代替主数据库,可以避免数据的丢失。
3、可以进行读写分离读写分离:
1、是一种让数据库更稳定的的使用数据库的方法。是在有从数据库的情况下使用,当主数据库进行对数据的增删改也就是写操作时,将查询的任务交给从数据库。
2、减轻主数据库的压力。因为进行写操作更耗时,所以如果不进行读写分离的话,写操作将会影响到读操作的效率哨兵:主从故障切换、请求读写分离
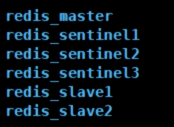
使用docker搭建Redis主从复制集群(6个容器、3个redis、3个哨兵)
1)准备配置文件和文件夹的路径
2)编写docker-compose.yml
version: "3.1"
services:
master:
image: redis:5
container_name: master
restart: always
network_mode: host
volumes:
- ./redis_master/conf/redis.conf:/etc/redis/redis.conf
- ./redis_master/data:/data
command:
['redis-server', '/etc/redis/redis.conf']
slave1:
image: redis:5
container_name: slave1
restart: always
network_mode: host
volumes:
- ./redis_slave1/conf/redis.conf:/etc/redis/redis.conf
- ./redis_slave1/data:/data
command:
['redis-server', '/etc/redis/redis.conf']
slave2:
image: redis:5
container_name: slave2
restart: always
network_mode: host
volumes:
- ./redis_slave2/conf/redis.conf:/etc/redis/redis.conf
- ./redis_slave2/data:/data
command:
['redis-server', '/etc/redis/redis.conf']
3)配置slave从机的redis.conf
replicaof 192.168.195.188 6379
主从复制搭建完成
4)搭建哨兵模式(docker-compose.yml)
sentinel1:
image: redis:5
container_name: sentinel1
restart: always
network_mode: host
volumes:
- ./redis_sentinel1/conf/sentinel.conf:/etc/redis/sentinel.conf
- ./redis_sentinel1/data:/data
command:
['redis-sentinel', '/etc/redis/sentinel.conf']
sentinel2:
image: redis:5
container_name: sentinel2
restart: always
network_mode: host
volumes:
- ./redis_sentinel2/conf/sentinel.conf:/etc/redis/sentinel.conf
- ./redis_sentinel2/data:/data
command:
['redis-sentinel', '/etc/redis/sentinel.conf']
sentinel3:
image: redis:5
container_name: sentinel3
restart: always
network_mode: host
volumes:
- ./redis_sentinel3/conf/sentinel.conf:/etc/redis/sentinel.conf
- ./redis_sentinel3/data:/data
command:
['redis-sentinel', '/etc/redis/sentinel.conf']
5)配置哨兵的sentinel.conf
sentinel monitor mymaster 192.168.195.188 6379 2
sentinel down-after-milliseconds mymaster 10000 #多久未收到master的心跳,认为master下线
6)SpringBoot连接哨兵,进行读写分离
Spring:
redis:
sentinel:
master: mymaster
nodes:
- 192.168.195.188:26379
- 192.168.195.188:26380
- 192.168.195.188:26381
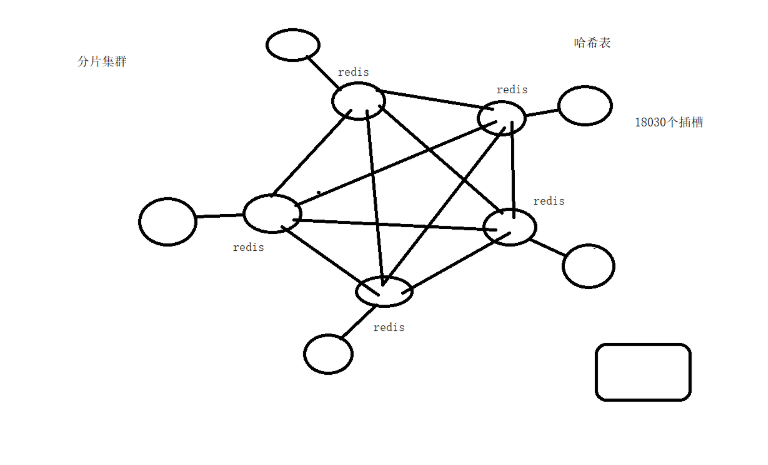
13.2 分片集群
最后
以上就是傻傻冰棍最近收集整理的关于3. redis (数据缓存中间件)的全部内容,更多相关3.内容请搜索靠谱客的其他文章。








发表评论 取消回复