上回书说到,谱聚类算法实现的过程中有许多参数需要选择。今天就想具体地谈谈这些参数选择的“规矩”。
首先,回顾一下上一篇文章中的一部分内容
讨论范围为三种不同的谱聚类算法:
1. unnormalized spectral clustering
2. Shi and Malik的算法(2000)
3. NJW算法(2002)
其中算法1使用未标准化Laplacian矩阵,算法2,3则分别使用了不同的标准化Laplacian矩阵。
(算法2使用的Laplacian为
Lrw
,算法3使用的Laplacian矩阵为
Lsym
,关于Laplacian矩阵,本文中将会给予具体的说明)
把他们分别称为非标准化谱聚类和标准化谱聚类。
假设需要聚类的
n
个点
谱聚类算法的实施过程通常包含以下几个步骤:
1.输入:相似度矩阵
(在此之前需要完成两项工作: 1.选择合适的相似度函数,2.选择合适的聚类数目
2.构造出相似图及其赋权的邻接矩阵(weighted adjacency matrix)
(这一步需要选择:相似图的类型以及相应的参数)
3.计算出相似图的
Laplacian
矩阵
(这一步需要选择:
Laplacian
矩阵的类型)
4.计算
Laplacian
矩阵的前
k
个特征值对应的特征向量,以这
5.视矩阵U的每一行为
Rk
中的一个点,对这
n
个点
6.输出聚类结果
A1,A2,...Ak
:
yi
被分到
Cj
中的哪一类,
xi
就被分到相应的
Aj
类
可以看到,在谱聚类算法的实施中,有着诸多需要人为控制的地方。其中,选择的不同可能导致不同类型的谱聚类算法(Laplacian矩阵的选择),另外的一些选择则没有涉及算法框架的不同(相似度函数、聚类数目k、相似图的类型和参数)。
关于这些所有的选择,都有一定的经验规则,也即是本文主要讨论的内容。
本文将分为以下几个部分:
* 相似度函数的选择
* 相似图类型、参数的选择
* 聚类数目的选择
* Laplacian矩阵的选择
* k-means步骤的其他可能性
* 关于特征向量计算的说明
正文开始:
相似度函数的选择
这是一个很困难的问题,至少我觉得如此。现在大家都在用的相似度函数都是高斯相似度函数(Gaussian similarity function):
当然,这里有一个潜在的假设:数据点都处于欧式空间 Rd 中。注意到,这里有一个参数 σ 是需要选取的,我们将在稍后的 相似图类型、参数的选择中谈到。
但真的如我们所见如此,都只使用上述的高斯相似度函数吗?如果可以的话,我还是乐于见到有其他备选项的。我觉得真的很难让人相信,这样一个简单的式子,就能把所有的相似的数据点之间的特征描述清楚的。
从理论上来说,选择不同的相似度函数还是可能的。而设计相似度函数时,有两点是值得注意的
1.有意义:即根据相似度函数判断的非常类似的数据点,在数据的应用背景中,也应该是非常相似的。
2.”微观效应”不那么重要:数据点之间的相似度是0.01还是0.001,带来的影响并不大,因为这些值已经足够小,在相似图中,我们是不会把这样的点连起来的(相信看到后文相似图类型、参数的选择部分,会有更直观的了解)。
很遗憾,关于相似度函数的选择,我能说的只有这么些了。希望以后能有对于“相似”更为本质的认识,可以谈得远一些。
相似图类型、参数的选择
相似图的构造是谱聚类中非常重要的一步,得到它的赋权邻接矩阵 W ,是计算Laplacian矩阵的起点。关注相似图构造中需要注意的一些事项,也因此成为了实践中考虑的重点。
在相似图的构造阶段,对于数据集
在这一部分,我们首先来了解一下相似图的几种类型:
1.
ϵ
-邻图(The ε -neighborhood graph)
选定参数
ϵ
,把点间距离小于
ϵ
的点连接起来,所得到的图就是
ϵ
-邻图。
在
ϵ
-邻图中,所有被连接起来的点之间的距离几乎都有着差不多的大小(至多为
ϵ
),因此常常会出现这样的情况:即使给这些连起来的边赋权,也并不能把数据中的更多信息体现到图里来。所以,在一般情况下,
ϵ
-邻图都视作无权图(unweighted graph)考虑。
2.
k
-近邻图(k-nearest neighbor graph)
选定参数
需要注意的是,因为这样的邻近关系并不是对称的(
vj
是
vi
的
k
近邻
(1)忽视边的方向。即只要
vj
是
vi
的
k
近邻,或者
(2)仅当
3.全连通图(The fully connected graph)
在这里,只是把所有具有非负相似度的点都连接起来,并以其之间的相似度
我们期望得到的图能够很好地表达局部邻域信息,因此仅当相似度函数本身就能很好地模拟局部邻域时,全连通的图才是好的选择。一个很普遍的例子就是利用前面提到的高斯相似度函数来构造这样的全连通图,此时函数中的参数
σ
起到的作用就是控制邻域的宽度,它与
ϵ
在
ϵ
-邻图中起到的作用类似。
以上的几种都是在谱聚类中常用的相似图。就我们目前所知,关于这些相似图的选择,还没有好的理论结果。
接下来,我们将谈谈在实际应用中,这些图的表现和选择
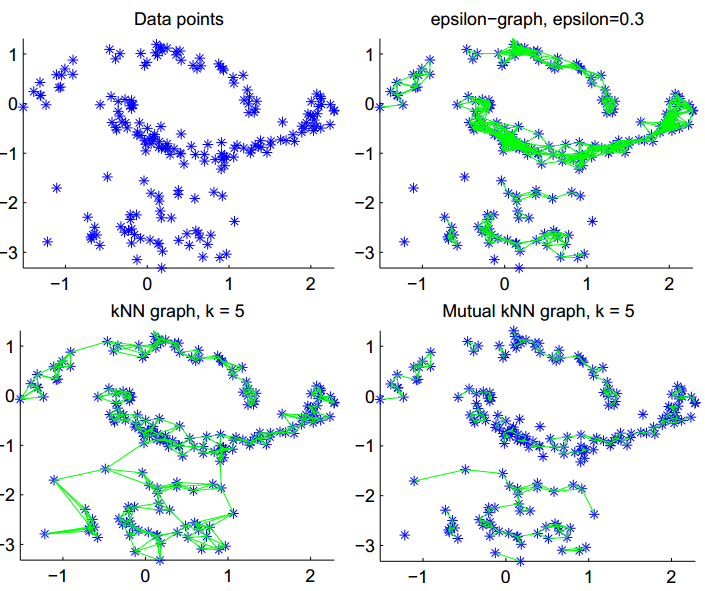
上图为测试数据,以说明各图之特点。(图由两个”月亮”和一个依高斯分布取样的散点集组成,其中下面的“月亮”较之上方,点的密度大一些)
1.
ϵ
-邻图(The ε -neighborhood graph)
有效的参数
ϵ
并不好选择。在上图(右上)中,可以看到中间的”月亮”中的点都被紧密地连接起来了,但对于取自高斯分布的点,效果却不太好。事实上正是如此,
ϵ
-邻图难以处理多尺度(即不同区域内,点之间的距离也不相同)的数据。
2.
k
-近邻图(k-nearest neighbor graph)
相较而言,
3.混合
k
-近邻图(mutual k-nearest neighbor graph)
它倾向于把某一固定密度的区域内的点连接起来,而不是把具有不同密度的区域之间的点相连。因此,看上去它可以是
4.全连通图(The fully connected graph)
正如刚才提到的一样,参数
在实践中,一般建议采取 k -近邻图(k-nearest neighbor graph)作为第一选择:它能够被简单地构造、得到的赋权邻接矩阵是稀疏的、对于参数的稳定性也较其他图好一些。
这一部分的最后,来看看不同类型图的参数选取的一些经验规则。
遗憾的是,几乎没有理论上的结果来指导这一任务。
一般而言,如果相似图中包含着比算法要求的聚类数目更多的连通分支,谱聚类算法将会平凡地将连通分支作为聚类返回。除非操作者能保证这些连通分支就是正确的聚类,否则是应该尽量使得相似图是全连通的,或者只包含几个很少的连通分支(或孤立点)。
其实在随机图的连通性上,还是有许多理论上的结果的,但所有的这些结果都是渐进(即数据点的个数
所以关注经验规则其实也是非常无奈的选择。现在就来看看吧。
1.
ϵ
-邻图(The ε -neighborhood graph)
计算使得图保持连通的
ϵ
的最小值还是比较简单的,它正好等于全连通图的最小生成树中最长边的长度,通过最小生成树算法即可计算。但如果数据中存在离群点,选出的
ϵ
就会很大,因为也要保证离群点被连入图中。此外,如果图中出现相互远离的小聚类的时候,也会出现类似的问题。这些情况下,对于反应数据中最重要的信息来说,
ϵ
都取得太大了。
2.
k
-近邻图(k-nearest neighbor graph)
对于中等大小的图,可以通过手试的办法来确定
3.混合
k
-近邻图(mutual k-nearest neighbor graph)
可以发现,当
4.全连通图(The fully connected graph)
使用全连通图时,有一个需求,就是对于每一个点来说,与它的相似度显著地大于
但要注意的是,上面的所有经验法则都只是经验法则而已,面对具体的数据,它们可能失效,参数的选择就要看使用者的敏锐了。
就先谈这么些吧,由于篇幅过长,后面的内容包括:聚类数目的选择、 Laplacian矩阵的选择、k-means步骤的其他可能性、关于特征向量计算的说明将另开一篇续之。
最后
以上就是炙热小松鼠最近收集整理的关于谱聚类基础-原理和细节(2):实践中的选择细节I的全部内容,更多相关谱聚类基础-原理和细节(2):实践中内容请搜索靠谱客的其他文章。








发表评论 取消回复