文章目录
- ==数据下载链接==
- 背景
- 理解问题
- 观察数据
- 数据清洗
- 缺失值处理
- 年龄:Age
- 舱位:Cabin
- 港口:Embarked
- 删除无法利用的列
- 分属性清洗
- 是否存活:Survived
- 客舱等级:Pclass
- 名字:Name
- 性别:Sex
- 年龄:Age
- 家庭成员数:SibSp,Parch
- 票价:Fare
数据下载链接
链接:https://www.kaggle.com/c/titanic/data
或者去网盘下载:
链接: https://pan.baidu.com/s/174qUpR2PDsrXrVOSenBUEA 提取码: qw67
背景
1921年4月15日,泰坦尼克号与冰山相撞,2224 名乘客和船员中有1502人丧生,虽然在沉船中幸存下来有一些运气因素,但是运气因素之外,是否还有其他因素呢?
理解问题
- 目的:预测泰坦尼克号上的游客能否存活
- 问题类型:只有幸存和遇难两个结果,所以是二元分类问题
- 衡量标准:准确度(accuracy)
观察数据
这一步主要是要了解数据的概况:数据的维度、属性的名称、属性的类型、缺失值情况等。
#加载库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#加载文件,注意:路径名称如果有中文,加上参数engine = 'python'
train_df = pd.read_csv('train.csv', engine = 'python')
train_df.head(3)
#查看数据的维度
print('===数据维度:{:}行{:}列===n'.format(train_df.shape[0],train_df.shape[1]))
#查看每列的名称、含义、数据类型
print('===各列数据类型如下:===')
train_df.info()
#查看各列的缺失值情况
print('n===各列的缺失值情况如下:===')
train_df.isnull().sum()
数据预览如下
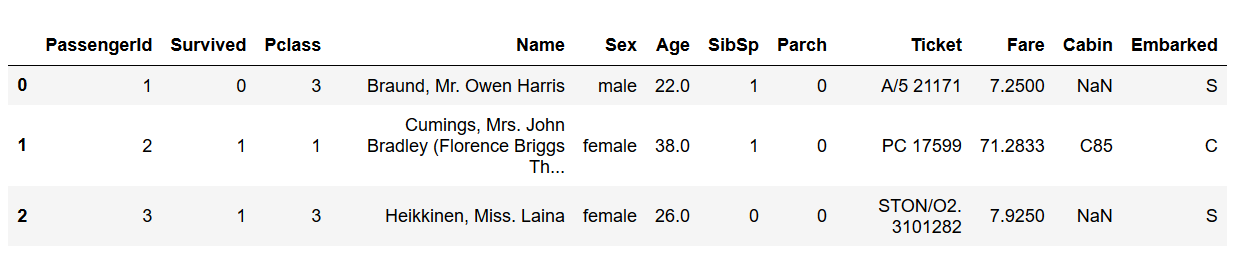
数据基本情况如下
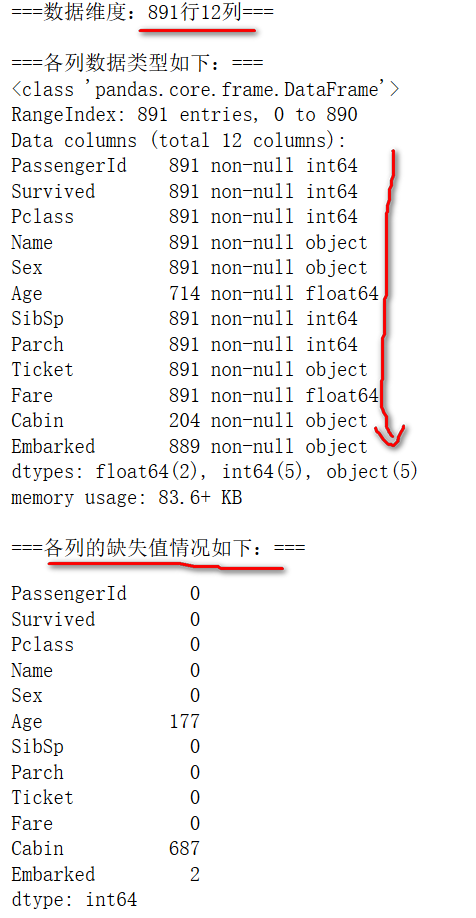 可以看到,共有891个观测值,12个属性,其中,Age属性缺失177个值,Cabin属性缺失687个值,Embarked缺失两个值
可以看到,共有891个观测值,12个属性,其中,Age属性缺失177个值,Cabin属性缺失687个值,Embarked缺失两个值
- 分类变量有PassengerId,Pclass,Name,Embarked等
- 数值变量有Age、Fare等
各个变量的含义: - PassengerId:序号,无特别意义
- Survived:0代表遇难,1代表幸存
- pclass:船票等级,1、2、3分别代表一等座、二等座、三等座
- sibsp:在船上兄弟姐妹、配偶的数量
- parch:在船上父母和孩子的数量
- ticket:船票编号
- fare:乘客票价
- cabin:船舱编号
- embarked:上船的港口(C、Q、S)
数据清洗
缺失值处理
首先查看有缺失值的属性并计算百分比:
print('===各属性缺失值数量:===')
train_df.isnull().sum()
print('n===各属性缺失值百分比:===')
(train_df.isnull().sum())/train_df.shape[0]*100
缺失值情况如下:
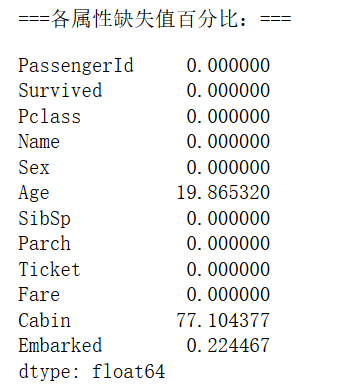
- Age:缺失177个值,占比20%,填充缺失值;
- Cabin:缺失687个值,占比77%,删除该属性;
- Embarked:缺失2个值,占比0.2%,填充缺失值。
年龄:Age
缺失值较多,这里采用一种较为简单的填充方法,根据未缺失的样本中各年龄出现的概率,随机选择适当的年龄填充,如果要更精细的话,可以继续考虑其他因素进行填充,如考虑是否有小孩、性别等因素再填充年龄。
#根据概率填充
s = train_df['Age'].value_counts(normalize = True)
missing_age = train_df['Age'].isnull()
train_df.loc[missing_age, 'Age'] = np.random.choice(s.index, size = len(train_df[missing_age]),
p = s.values)
#检查是否填充成功
train_df['Age'].isnull().sum()
舱位:Cabin
缺失值太多,直接删除
train_df = train_df.drop("Cabin", axis = 1)
港口:Embarked
只缺失两个值,所以可以直接采用最简单的方法填充值
train_df['Embarked'] = train_df['Embarked'].fillna(method = 'ffill')
#缺失值处理完成,检验是否还有缺失值:
train_df.isnull().sum()
删除无法利用的列
像PassengerId、Ticket都不容易进一步使用,这里先删除
train_df = train_df.drop(['PassengerId','Ticket'], axis = 1)
到这一步,数据预览如下:

分属性清洗
是否存活:Survived
这是响应列,不处理
客舱等级:Pclass
该属性分为1、2、3三个等级,后期进行独热编码,也先不处理
名字:Name
可以将名字中的称呼提取出来,或许和称呼有关系。
#使用正则表达式提取出称呼
train_df['title'] = train_df['Name'].str.extract(r' ([A-Za-z]+).',expand = False)
#查看称呼和生存情况的交叉表
title_df = pd.crosstab(train_df['title'], train_df['Survived'])
title_df
称呼和是否生存交叉表如下
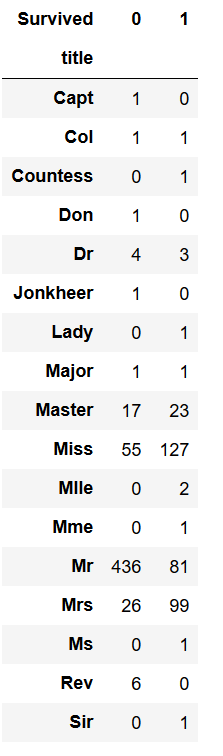
我们发现属性的取值太多,不利于我们进一步分析,因此我们要将数量少的属性进行合并。
#属性太多,将数量太少合并为一类进行观察,
train_df['title'] = train_df['title'].replace(['Lady', 'Countess','Capt', 'Col',
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
train_df['title'] = train_df['title'].replace('Mlle', 'Miss')
train_df['title'] = train_df['title'].replace('Ms', 'Miss')
train_df['title'] = train_df['title'].replace('Mme', 'Mrs')
更专业一点,应该比较odds,将odds值相近的分到一组,参考代码如下:
title_df = pd.crosstab(train_df['title'], train_df['Survived'])
title_df['odds'] = (title_df.iloc[:,1] - title_df.iloc[:,0])/title_df.sum(axis = 1)
title_df['sum'] = title_df.iloc[:,0] + title_df.iloc[:,1]
title_df['sum_percent'] = title_df['sum']/title_df['sum'].sum()
title_df
结果如下:
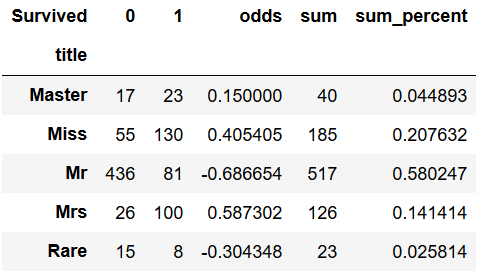 原则上来讲,Master和Rare两个取值的样本数量不到总样本的5%,应该讲其合并到odds最接近的进行合并
原则上来讲,Master和Rare两个取值的样本数量不到总样本的5%,应该讲其合并到odds最接近的进行合并
提取完称呼后,接下来可以删除name属性:
#现在删除Name属性
train_df = train_df.drop(['Name'], axis = 1)
性别:Sex
这里只将性别换成0和1,便于进一步分析:
pat = {
'male':1,
'female':0
}
train_df['Sex'] = train_df['Sex'].map(pat)
年龄:Age
是一个连续变量,先画直方图观察趋势:
plt.hist(train_df['Age'])
plt.xlabel('Age')
plt.ylabel('Count')
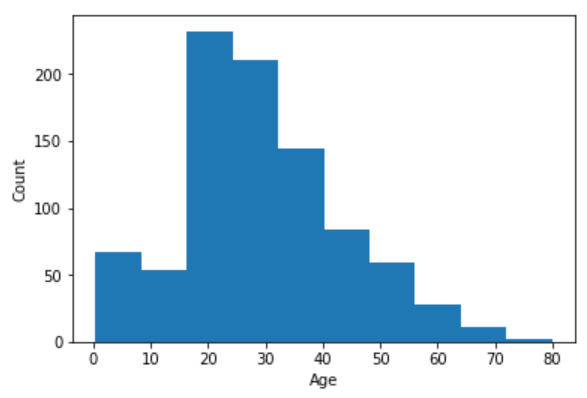 发现数据不算很分散,所以采用等宽的离散化方法:
发现数据不算很分散,所以采用等宽的离散化方法:
#分成均等的五份
train_df['AgeBin'] = pd.cut(train_df['Age'], 5)
#删除Age列
train_df = train_df.drop(['Age'], axis = 1)
家庭成员数:SibSp,Parch
我们知道SibSp代表兄弟姐妹/配偶的数量,Parch代表父母/孩子的数量,我们可以利用SibSp和Parch创建FamilySize和IsAlone变量,分别代表家庭成员数量和是否单独出行,IsAlone=1表明是单独的状态,0表示不是。
train_df['FamilySize'] = train_df['SibSp'] + train_df['Parch'] + 1
train_df['IsAlone'] = 1
train_df['IsAlone'].loc[train_df['FamilySize'] > 1] = 0
票价:Fare
票价还是连续变量,先画直方图看趋势。
plt.hist(train_df['Fare'])
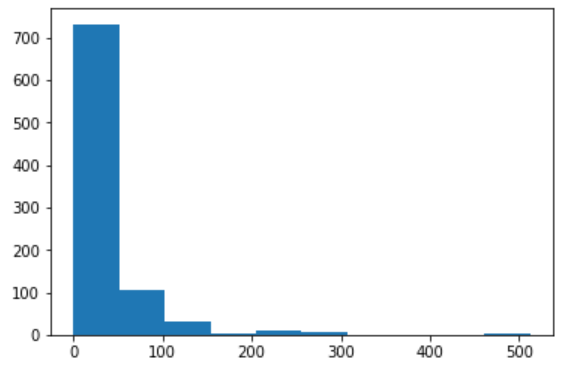 数据分布极不均匀,因此采用等频的离散化的方法
数据分布极不均匀,因此采用等频的离散化的方法
train_df['FareBin'] = pd.qcut(train_df['Fare'], 4)
train_df = train_df.drop(['Fare'], axis = 1)
到这一步,数据预览效果如下
 所有连续变量都转换成了离散变量,删除了无用的列、填充了缺失值,后面还需要进行将离散变量进行编码,选择模型、训练模型等操作。
所有连续变量都转换成了离散变量,删除了无用的列、填充了缺失值,后面还需要进行将离散变量进行编码,选择模型、训练模型等操作。
最后
以上就是感性微笑最近收集整理的关于数据挖掘入门_泰坦尼克号存活预测之数据清洗(含数据)【一】数据下载链接背景理解问题观察数据数据清洗的全部内容,更多相关数据挖掘入门_泰坦尼克号存活预测之数据清洗(含数据)【一】数据下载链接背景理解问题观察数据数据清洗内容请搜索靠谱客的其他文章。








发表评论 取消回复